

Hive概念学习
Hive简介
Hive是基于Hadoop的数据仓库工具,可以对存储在HDFS上的文件数据集进行查询和分析处理。可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询语言 HiveQL,在做查询时将HQL语句转换成MapReduce任务,在Hadoop层进行执行。主要用途:做离线数据分析,比直接用MapReduce开发效率更高。
Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP),Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。
Hive和数据库的异同
由于Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在Online的应用中,但是Hive是为数据仓库而设计的。
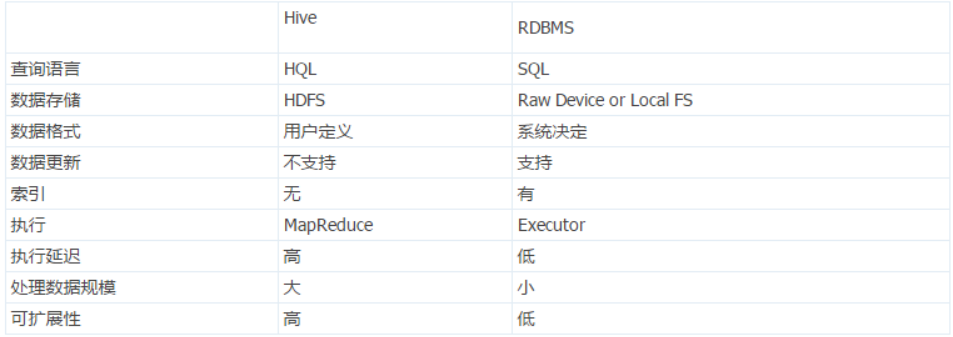
1.查询语言。由于 SQL 被广泛的应用在数据仓库中,因此专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
2.数据存储位置。Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或者本地文件系统中。 3.数据格式。Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive中默认有三个文件格式TextFile,SequenceFile以及RCFile)。由于在加载数据的过程中,不需要从用户数据格式到Hive定义的数据格式的转换,因此,Hive在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的HDFS目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
4.数据更新。由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用INSERT INTO ... VALUES添加数据,使用UPDATE ... SET修改数据。
5.索引。之前已经说过,Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于MapReduce的引入, Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了Hive不适合在线数据查询。
6.执行。Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现的(类似select * from tbl的查询不需要MapReduce)。而数据库通常有自己的执行引擎。
执行延迟。之前提到,Hive在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致Hive执行延迟高的因素是MapReduce框架。由于MapReduce本身具有较高的延迟,因此在利用MapReduce执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
7.可扩展性。由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的。而数据库由于ACID语义的严格限制,扩展行非常有限。
8.数据规模。由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive的特点
优点:
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
避免了去写MapReduce,减少开发人员的学习成本
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
可以处理海量数据
缺点:
因为Hive底层是MapReduce, 所以执行延迟比较高, 无法提供实时查询, 而且不支持流式数据
不支持行级别的增删改
迭代算法无法表达
Hive优化比较困难
数据库和数据仓库对比
|
数据库 |
数据仓库 |
|
为线上系统提供实时数据 |
为离线分析存储历史数据 |
|
具有完整的增删改查的能力 |
只支持一次写入多次查询,不支持行级别的增删改 |
|
具有完整的事务能力 |
不强调事务的特性 |
|
尽量的避免冗余 提高存储 和处理的效率 |
人为的制造冗余 提高查询的效率 |
|
数据来源单一 |
数据来源多样 |
OLTP(Online Transaction Processing) 联机事务处理系统
数据库属于OLTP, 涵盖了企业大部分的日常操作,如购物、库存、制造、银行、工资、注册、记账等, 比如Mysql,oracle等关系型数据库
OLTP是面向用户的、用于程序员的事务处理以及客户的查询处理
OLTP系统的访问由于要保证原子性,所以有事务机制和恢复机制
OLTP系统具有较强的事务
OLAP(Online Analytical Processing) 联机分析处理系统
主要用于分析数据, Hive, HBase都属于OLAP
OLAP是面向市场的,用于知识工人(经理、主管和数据分析人员)的数据分析
OLAP通常会集成多个异构数据源的数据,数量巨大
OLAP系统一般存储的是历史数据,所以大部分都是只读操作,不需要事务
Hive架构
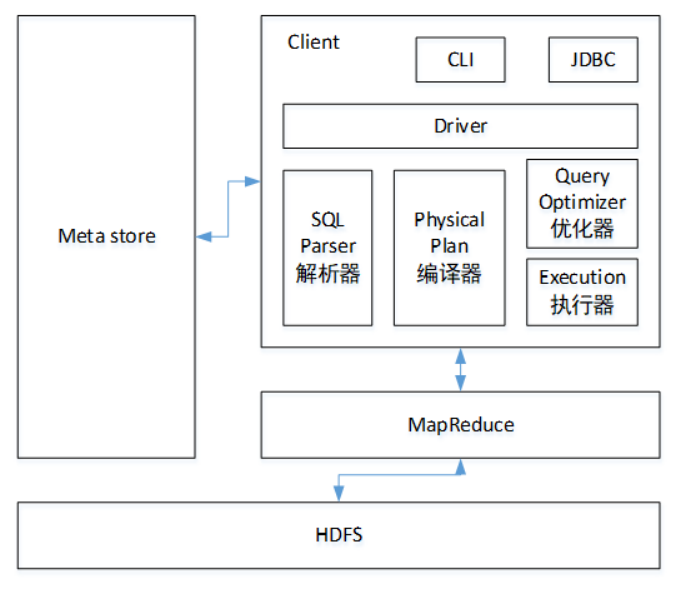
1 Client(客户端)
即用户接口, 其中包括CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
2 Metastore(元数据)
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等
注意:HIve默认的元数据存储在自带derby数据库中, 但是不推荐使用derby数据库, 可以自定义成MySQL数据库存储
3.Hadoop
Hive基于HDFS存储, 将类SQL语句翻译成MapReduce在Yarn上运行
4.Driver(驱动器)
解析器
将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
编译器
将AST编译生成逻辑执行计划
优化器
对逻辑执行进行优化
执行器
把逻辑执行计划转换成可运行的物理计划, 对于Hive来说, 也就是MapReduce或者Spark
Hive执行流程
1.用户通过客户端提交一个HQL语句
2.通过complier(编译组件) 对HQL语句进行词法和语法分析, 在这一步编译器会分析出HQL语句要操作哪张表
3.去元数据获取表信息
4.complier编译器提交HQL语句分析方案
5.执行HQL语句
执行器在执行方案时,会进行判断:如果当前方案不涉及到MapReduce组件,比如为表添加分区信息、比如字符串操作等,比如简单的查询操作等,此时就会直接和元数据库交互,然后去HDFS上去找具体数据.
如果涉及到计算或者复杂的查询, 就需要将HQL语句转换成MapReduce去执行.
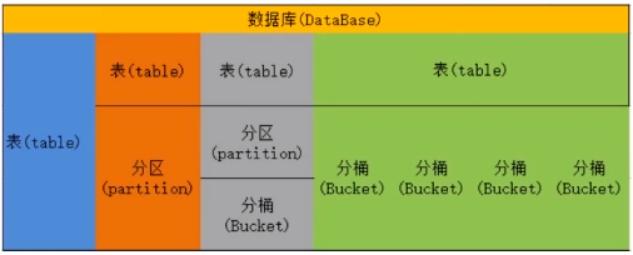
Hive的数据模型主要有以下四种:
Hive安装

参考:
https://blog.csdn.net/alaskyed/article/details/105444201


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本