Transformer加载预训练模型实践
以使用google-bert/bert-base-chinese 模型为例
- 下载预训练模型
官方站点:https://www.huggingface.co/(如果无法访问,使用镜像站点)
镜像站点:https://hf-mirror.com/
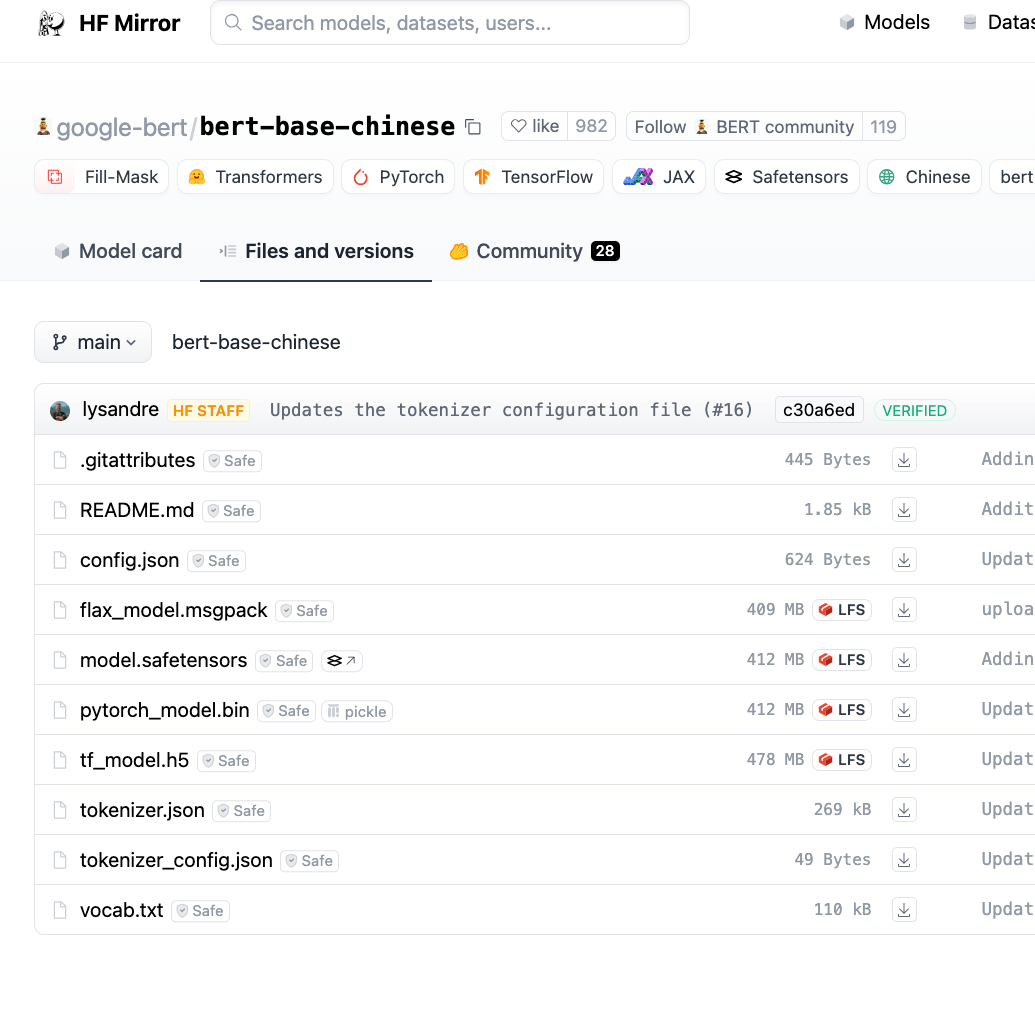
搜索框内搜索自己需要的模型,点击Files and versions ,
![]()
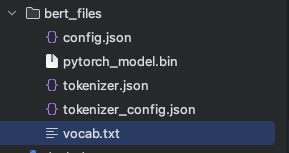
一般下载config.json、pytorch_model.bin、tokenizer.json、tokenizer_config.json、vocab.txt文件,放在自己设置的文件夹内
![]()
- 加载
# 初始化tokenizer tokenizer = BertTokenizer.from_pretrained(model_dir + '/other_code_files/bert_files/') 注意这里加斜杠 # 定义模型类 class Newsxxx(nn.Module): def __init__(self, n_classes): super(NewsClassifier, self).__init__() self.bert = BertModel.from_pretrained(model_dir + '/other_code_files/bert_files') 注意这里不加斜杠

 浙公网安备 33010602011771号
浙公网安备 33010602011771号