

爬取小说《重生之狂暴火法》 1~140章
需要使用的库
- requests
- re
1、打开网址“ http://www.17k.com/list/2726194.html ”查看章节目录
按F12查看如下:

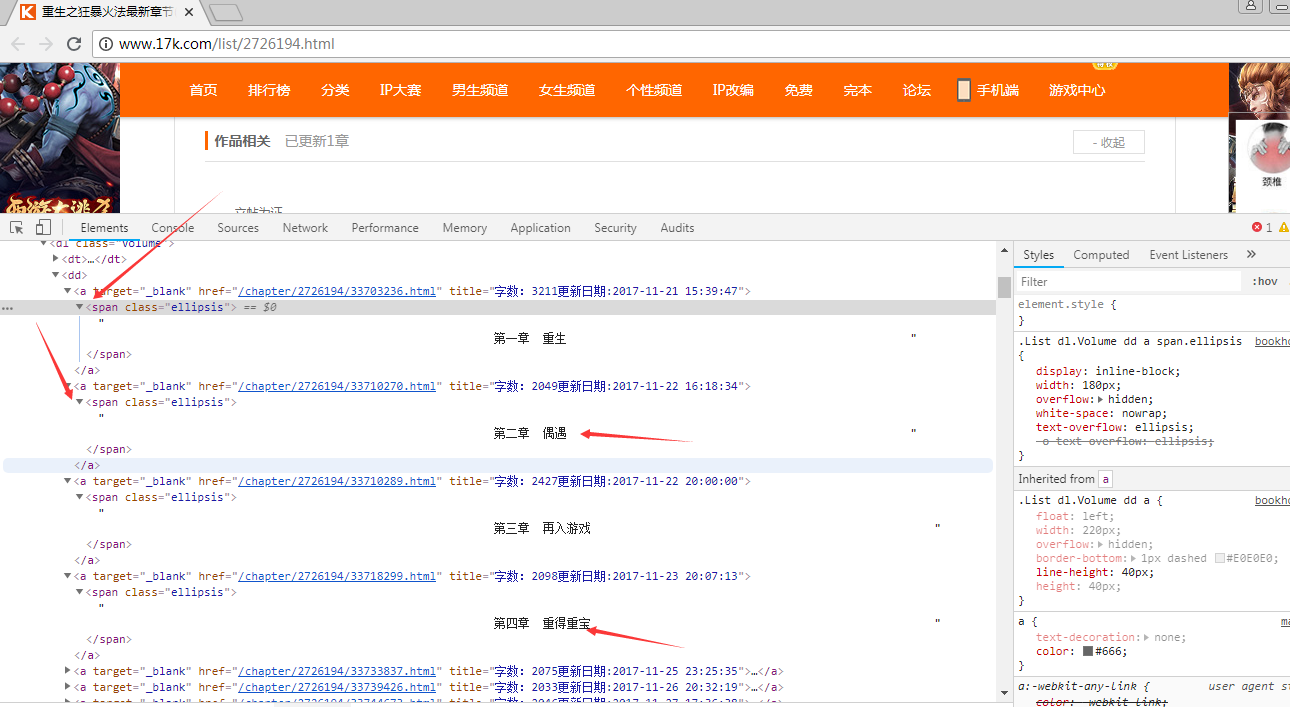
经过分析,我们可以通过简单的正则表达式,提取出每一章的章节名称(源代码第34行)
1 pat = r"(第.+章.+)</h1>"
2、接下来打开第一章通过源代码再次分析
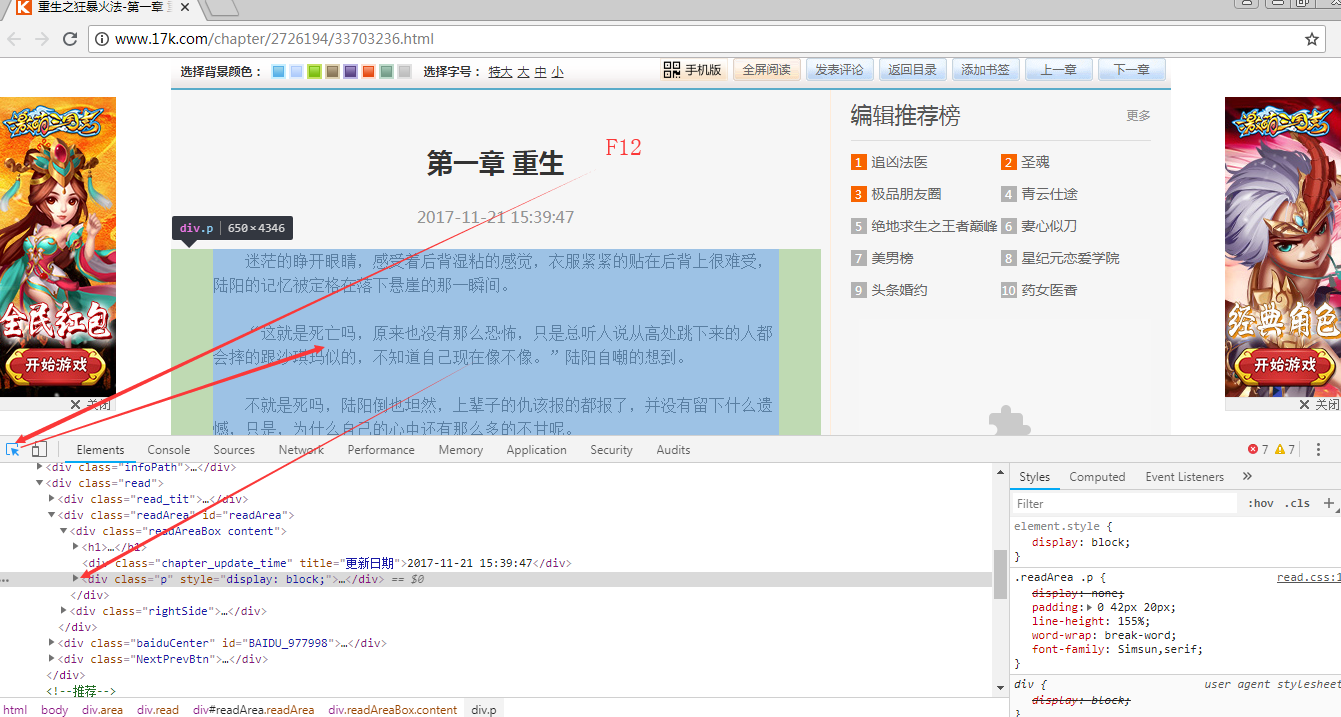

再次通过简单的分析,我们可以可以用简单的正则表达式提取出小说内容(源代码45~47行)
3、源代码如下
1 import requests 2 import re 3 4 5 class Novel(object): 6 url_list = [] 7 chapter_list = [] 8 chapter_title_list = [] 9 10 11 def __init__(self, url): 12 self.url = url 13 14 def obtain_url(self): 15 response = requests.get(self.url) 16 response.encoding = "utf-8" 17 pat = r"/chapter/2726194/(\d+)\.html" 18 ls = [] 19 ls2 = [] 20 for i in re.findall(pat, response.text): 21 ls.append(i) 22 for i in range(1, 141): 23 ls2.append(ls[i]) 24 for i in ls2: 25 new_url = "http://www.17k.com/chapter/2726194/" + i + ".html" 26 Novel.url_list.append(new_url) 27 28 29 30 def obtan_title(self): 31 for i in self.url_list: 32 response = requests.get(i) 33 response.encoding = "utf-8" 34 pat = r"(第.+章.+)</h1>" 35 title = re.findall(pat,response.text) 36 self.chapter_title_list.append(str(title)) 37 38 39 40 def grab_url(self): 41 for i in self.url_list: 42 response = requests.get(i) 43 response.encoding = "utf-8" 44 lst = '' 45 pat = r"  (.+)<br /><br />" 46 new_text = str(re.findall(pat, response.text))[1:-1] 47 pat2 = r"[^<br /><br />  ]" 48 for j in re.findall(pat2, new_text): 49 if j == "。": 50 j = "\n" 51 lst = lst + j 52 self.chapter_list.append(lst) 53 54 55 def storage(self): 56 with open("F:\\重生.txt", "a") as f: 57 i = 0 58 while i < 140: 59 f.write(str("\n" + self.chapter_title_list[i]) + "\n") 60 f.write(self.chapter_list[i]) 61 i += 1 62 63 64 # 主方法 65 def grab(self): 66 # 获取网址 67 self.obtain_url() 68 69 #章节标题 70 self.obtan_title() 71 72 #章节内容 73 self.grab_url() 74 75 #存储 76 self.storage() 77 78 if __name__ == '__main__': 79 try: 80 spider = Novel("http://www.17k.com/list/2726194.html") 81 spider.grab() 82 except : 83 print("爬取出错~~")
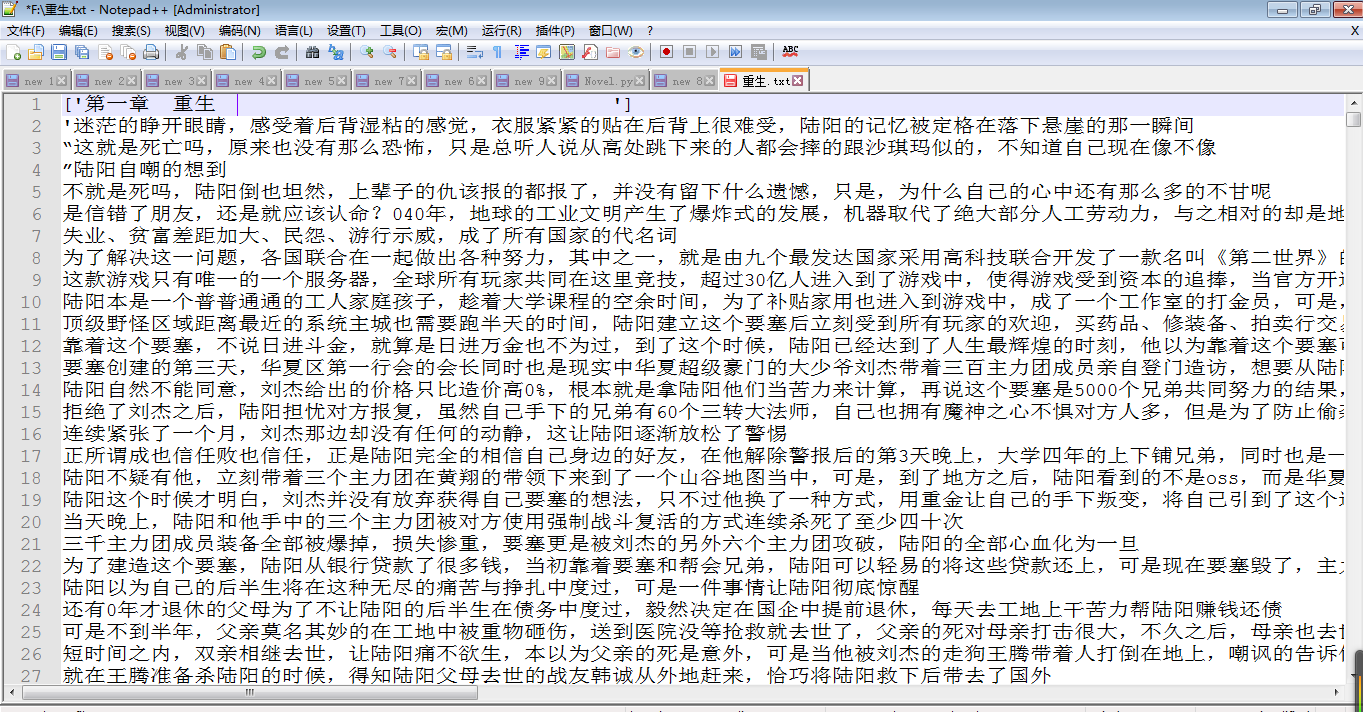
运行后会在F盘生成一个 "重生.txt" 的文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号