


一个简单存储过程的性能分析
在一次例行的SQL Server性能跟踪中,发现了一个通过blogname得到blogid的存储过程被频繁的调用,而性能表现不尽如人意,尽管这个存储过程很简单。
CREATE PROCEDURE dbo.UPS_GetBlogIDByName
@BlogName nvarchar(50)
AS
SET NOCOUNT ON
SELECT ID FROM Blogs with(nolock)WHERE Name=@BlogName
GO
而事实上表Blogs的结构是这样定义的
|
字段名 |
名称 |
类型 |
备注 |
|
ID |
博客ID |
Int |
主键 |
|
Name |
博客名 |
Varchar(50) |
该字段建立索引 |
|
Blogheading |
博客标题 |
Nvarchar(250) |
|
|
… |
… |
… |
其他字段省略 |
该表的数量级为百万级。
粗看,此存储过程似乎没有一点问题,要不是性能跟踪时发现性能很差,真是不容易发现。原因就在存储的参数BlogName的类型声明成了Nvarchar(50),这样就会使数据库去查询表时,会先把表的博客名(Name)先转化成nvarchar的这一步的动作,导致Name上的索引失效。
不知道当时作者是笔误还是根本就没有注意到varchar与nvarchar的区别,反正就是这个小小的不注意,导致了数据库性能下降了不少。
以下是我具体的测试数据,截图为据。
Declare @b varchar(50)
Declare @bc nvarchar(50)
Set @b = ‘blogtest’
Set @bc = N‘blogtest’
Select id from blogs where name=@b
Select id from blogs where name=@bc
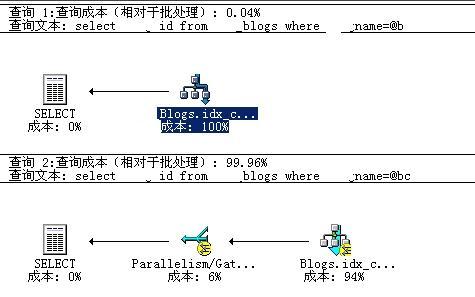
从图上可以看出,两者的性能差别之大,真是始料不及的。故而,我们在以后写存储过程的时候,特别要注意查询字段的类型务必要和表中相应字段保持一致,以免出现不容易被发现的重大失误。

