软 工 实 践 · 结 队 作 业 —— 第二次作业
【软 工 实 践 · 结 队 作 业】 第二次作业
Part 1 · 结 队 成 员 信 息
- 吴 海 林 - 031502430 · 实 力 抱 大 腿
- 苏 伟 鹏 - 031502331 · 实 力 代 码 输 出
Part 2 · Github链 接

Part 3 · 听 说 你 是 最 好 的 数 据

Part 3 - 1 · 听 说 你 是 这 样 生 成 的
- 需求:需要300个学生信息及20个部门信息
- 做法:
- 初始化
自定义标签库及空闲时间库用数组存储自定义标签及空闲时间库- 采用随机数生成函数,随机生成学生学号、预选部门编号及一组不重复的随机序列,通过随机序列随机生成相应的标签及空闲时间
- 考虑因素:主要是考虑数据生成的随机性
- 不足:时间段生成部门为自定义时间段,扩展性较好,但是随机性较差,在计算权值边可能会造成学生部门空闲时间匹配数目较高的问题,可采用随机生成数去生成时间段去改进,另外就是那个格式的问题,打算直接用库函数的,但是一直报
Assertion failed type_ == nullValue || type_ == objectValue这个错误,网上看了很多解决方法,然而并没有什么卵用,无奈只能手动格式
Part 4 · 部 门 匹 配 之 非 诚 勿 扰
Part 4 - 1 · 数 据 建 模
1.现实实体学生与部门之间是多对多的联系关系,这里我们只考虑一对一的联系方式,主要原因是较容易实现
2.权值定义:由志愿顺序、时间匹配度及标签匹配度构成,具体算法详见代码
Part 4 - 2 · 非 诚 勿 扰
1.计算相应权值并排序,设置bool值表示当前学生学生是否已被录取,通过相应判断抉择是否能加入该部门
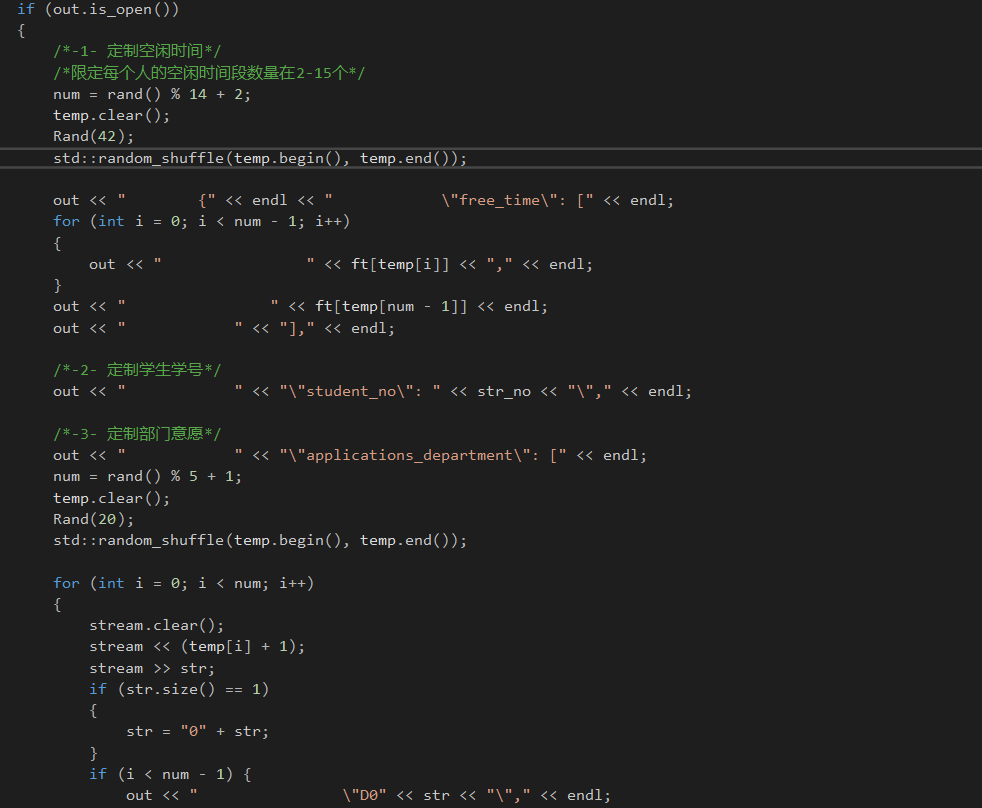
Part 4 - 3 · 核 心 代 码 清 单
PS:具体代码详见Github,这边只是贴出部分核心代码
/*匹配算法*/
for (int j = 0; j < stu_num; j++) {
if (dep[i].member_limit == 0) break;
if (wishtmp[j].value != 0) {
if (stu[wishtmp[j].stu_index].flag == false) {
addmitted[i].member[addmitted[i].memeber_num++] =stu[wishtmp[j].stu_index].student_no;
stu[wishtmp[j].stu_index].flag = true;
dep[i].member_limit--;
}
else{
continue;
}
}
if (wishtmp[j].value == 0) break;
}
}
for (int i = 0; i < dep_num; i++) {
if (addmitted[i].memeber_num == 0) {
unlucky_depa[unluck_dep_num++].department_no = addmitted[i].department_no;
}
}
for (int i = 0; i < stu_num; i++) {
if (!stu[i].flag) {
unlucky_student[unluck_stu_num++].student_sno = stu[i].student_no;
}
}
/*权值计算*/
for (int i = 0; i < dep_event_num; i++) {
int mark = 0; //标记该部门活动时间 该学生能否有时间 参加该活动
int event_total_time = dep_end[i] - dep_begin[i]; //部门开展活动总时间
int free_total_time = 0; //该学生能参加活动的总时间
for (int j = 0; j < stu_free_num; j++) {
if (stu_begin[j] <= dep_begin[i] && stu_end[j] <= dep_end[i] || free_total_time >= event_total_time) {
mark = 1;
break;
}
else if (stu_begin[j] >= dep_begin[i] && stu_end[j] >= dep_end[i]) {
if (stu_begin[j] < dep_end[i]) free_total_time += dep_end[i] - stu_begin[j];
else {
continue;
}
}
else if (stu_end[j] <= dep_end[i] && stu_begin[j] <= dep_begin[i]) {
if (stu_end[j] <= dep_begin[i]) { continue; }
else free_total_time += stu_end[j] - dep_begin[i];
}
else {
free_total_time += stu_end[i] - stu_begin[i];
}
}
if (mark == 1) {
times++;
}
else if ((double)(free_total_time*1.0 / event_total_time) > 0.5) {
times++;
}
}
/*
*rank2 = tim/deparment_time * 33.33
*根据学生课余时间 课余时间越多,rank值越大 tim学生能参加活动的次数 deparment_time *门举办活动的次数
*/
//保证分母不为0
if (departments.event_schedules->length() != 0) {
rank2 = double(1.0*times / (departments.event_schedules->length()) * 33.33);
}
/*
rank3 = match_tags/dep_tags * 33.33
根据学生兴趣,与部门标签的占比,觉得最后的分数。 match_tags匹配到的标签数目 dep_tags部门所拥有的标签数目
*/
for (int i = 0; i < departments.tag_num; i++) {
for (int j = 0; j < students.tags_num; j++) {
if (departments.tags[i] == students.tags[j]) {
match_tags++;
}
}
}
//保证分母不为0
if (departments.tag_num != 0) {
rank3 = double(1.0*match_tags / departments.tag_num * 33.33);
}
Part 5 · 规 范
- 主要包括规范注释、合理运用空行、代码格式化、无冗余代码及无废弃代码等
Part 6 · 结 果 评 估
匹配算法前提条件:一个学生只加一个部门,志愿至少一个,至多五个
匹配结果:通过计算该学生对部门的权值进行匹配,然后通过权值进行相应匹配,以自动生成的数据为例子,300个学生有56个学生未被匹配,匹配率大概有80%这样子,好像真的很高的样子
不足之处:受部分前提条件限制,与现实生活情况好像不相符合
Part 7 · 结 队 感 受
队友感受:本次作业比起上次作业,确实有趣了很多,毕竟能敲代码,上次作业也就画画图什么的,结对最大的好处就是可以共同讨论问题,共同解决问题,每当遇到bug的时候可能自己找到眼花缭乱,队友可能只需要一会儿的功夫,这就节约了很多时间,还有就是分工合作,加大了作业的效率。当然为了这个作业,也和队友熬了一夜,想想多么可怕,但是又是开心的,因为学习是一件快乐的事,哈哈哈哈!!!!作业固然重要,从中能学到很多东西。不仅可以从网络学,还可以从队友身上学习。所以啊,结对给我的最好的感受是:分忧解难,增强效率
我的感受:一句话评价结队的最大好处——当局者迷,旁观者清,在项目收官的时候,接连出现了好几个未知的bug,一般都是当局者一直找不到bug,然后旁观者看着看着就突然发现了,当然也有出现两个人都找不到的情况,这种就比较尴尬了,总之,DeBug能力尚待提高,结队效率远远高于一个人。然后就是说说个人,上一篇博客队友信息描述实力预言了这次作业的分工,这次作业代码主力输出都在队友身上,我就端端茶倒倒水写了工作量比较小的数据生成程序,总体还是非常感谢队友的付出,毕竟有五年的同窗之谊,好像说了太多废话,总而言之,言而总之,结队编程,不试不知道,一试吓一跳。嗯 收工~ ~ ~ ~
Part 8 · 听 说 你 是 我 队 友


 浙公网安备 33010602011771号
浙公网安备 33010602011771号