排序算法之堆排序
简介
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。
堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即父节点结点的键值或索引总是小于(或者大于)它的子节点。
堆的概念
在介绍堆排序之前,简单介绍一下堆的概念。
堆是一棵顺序存储的完全二叉树。
其中每个结点的关键字都大于等于其孩子结点的关键字,这样的堆称为大根堆。
其中每个结点的关键字都小于等于其孩子结点的关键字,这样的堆称为小根堆。
举个栗子,对于 \(n\) 个元素的序列 \({R_0,R_1,R_2 ... R_{n-1}}\) 当且仅当满足下列关系之一时,被称之为堆:
(1)\({R_i >= R_{2i+1}}\) 且 \({R_i >= R_{2i+2}}\) 大根堆
(2)\({R_i <= R_{2i+1}}\) 且 \({R_i <= R_{2i+2}}\) 小根堆
基本思想
将待排序的序列建立成一个大根堆,此时,整个序列的最大值就是堆顶的根节点。
每次将堆顶的最大值换到末尾,此时末尾为最大值;然后将剩余 n-1 个元素重新构建成一个大根堆,这样会得到剩余 n-1 个元素的最大值,反复执行,就能够得到一个有序序列了。
排序过程
构造大根堆
1、无序序列初始结构,此处排序数据:{1,8,6,5,3,7,4}
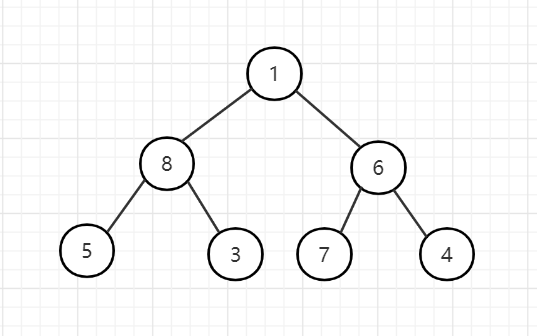
2、从最后一个非叶子节点开始,每个点向下调整,最终要使每个点的子树满足大根堆的性质,最终整个完全二叉树建立为大根堆。
首先从节点6开始调整,发现节点7最大,交换。
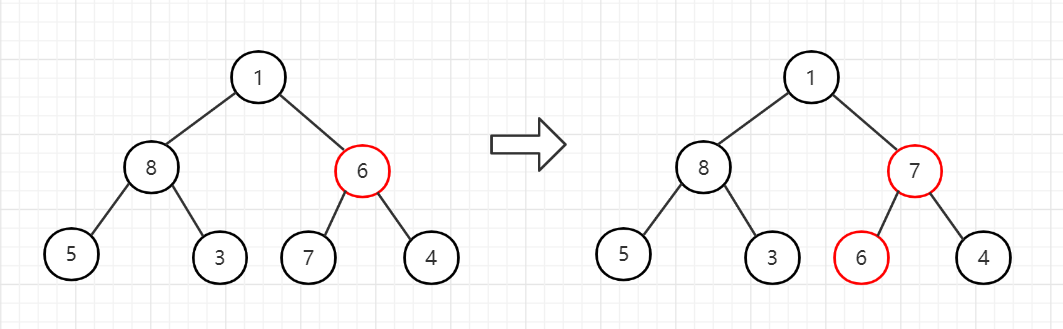
3、调整节点8,已经是最大,不用交换。
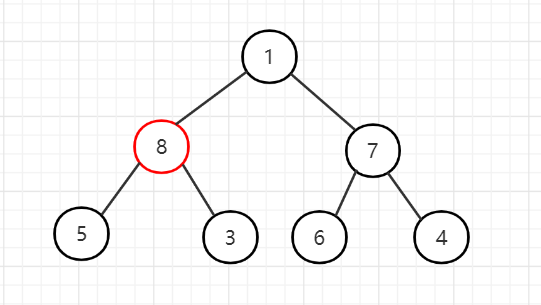
4、调整节点1,发现节点8最大,交换;继续向下调整,交换节点5和节点1。
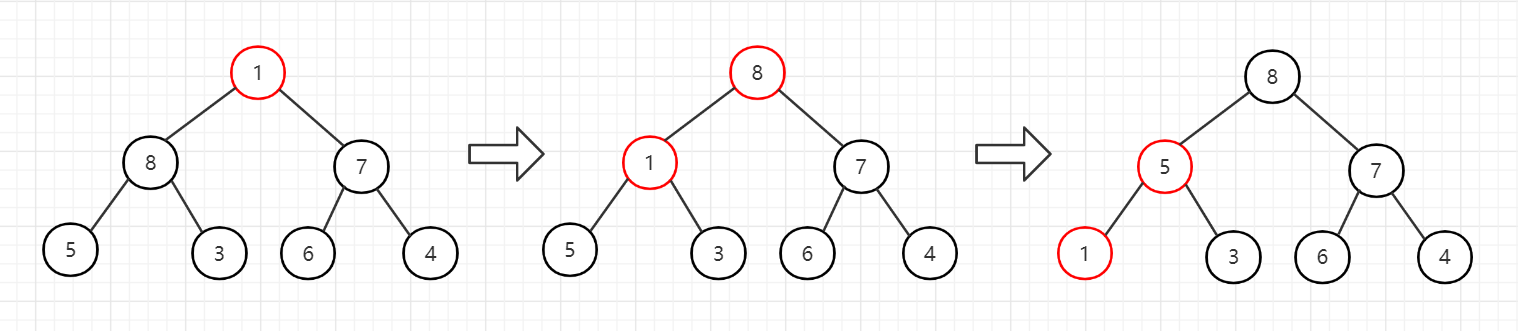
5、至此,大根堆已经构建完成了。
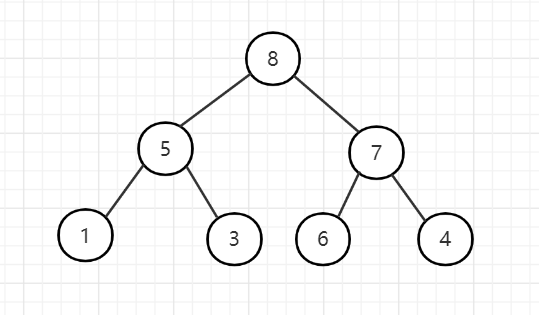
堆排序
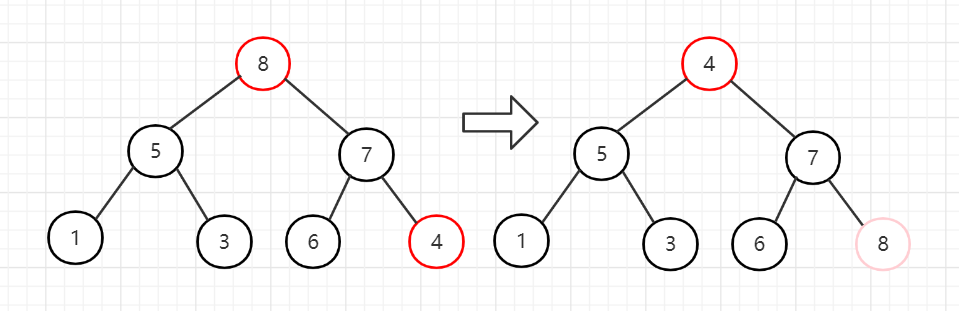
1、将堆顶元素和末尾元素交换,使末尾元素最后,然后继续调整剩下的 n-1 个元素。如此反复进行交换、重建、交换。
首先将节点8换到最后,跟末尾节点4交换。然后堆的长度减一,忽略最后一个节点8。然后从堆顶向下调整。
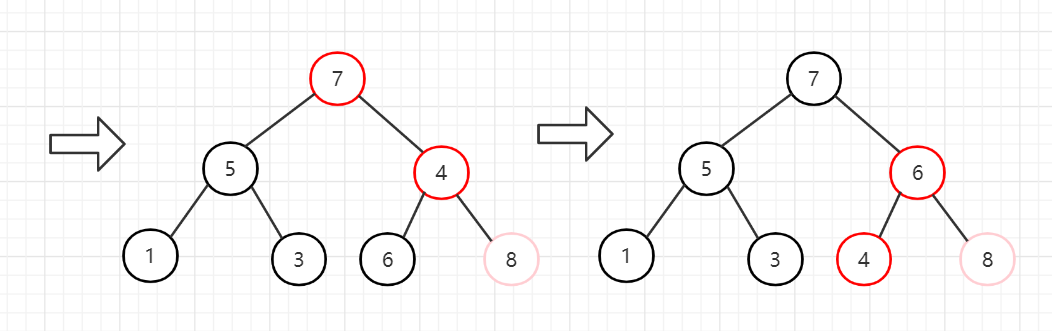
2、节点7和节点4交换,堆长度减一,忽略节点7。然后从堆顶向下调整。
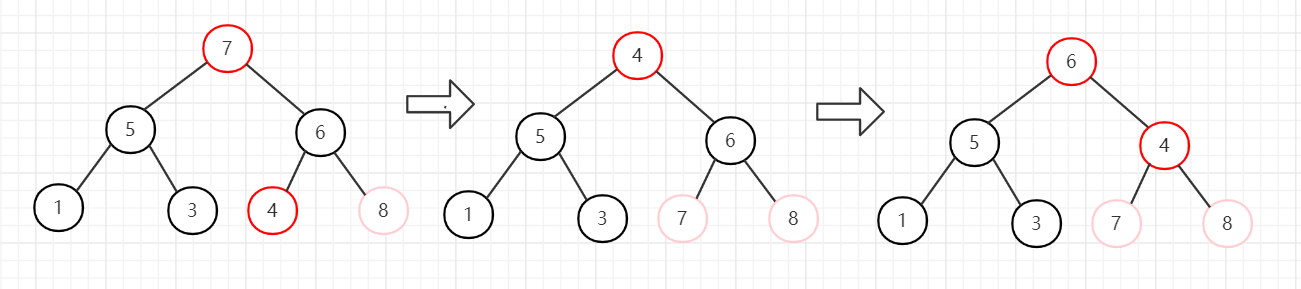
3、节点6和节点3交换,堆长度减一,忽略节点6。然后从堆顶向下调整。
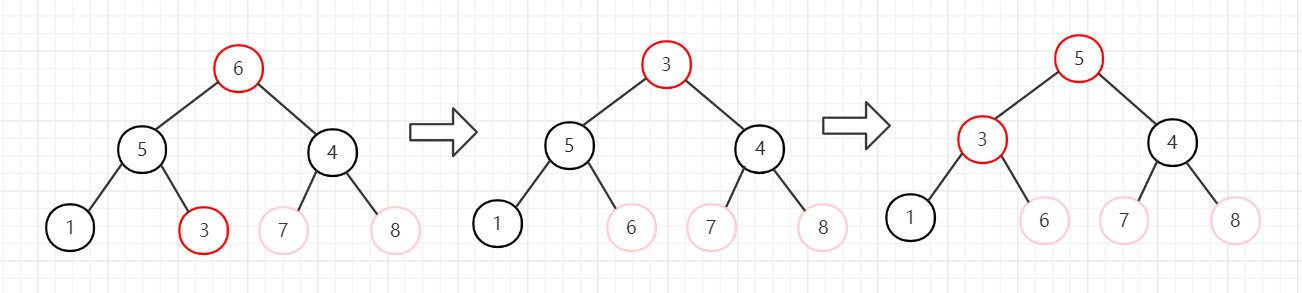
4、节点5和节点1交换,堆长度减一,忽略节点5。然后从堆顶向下调整。
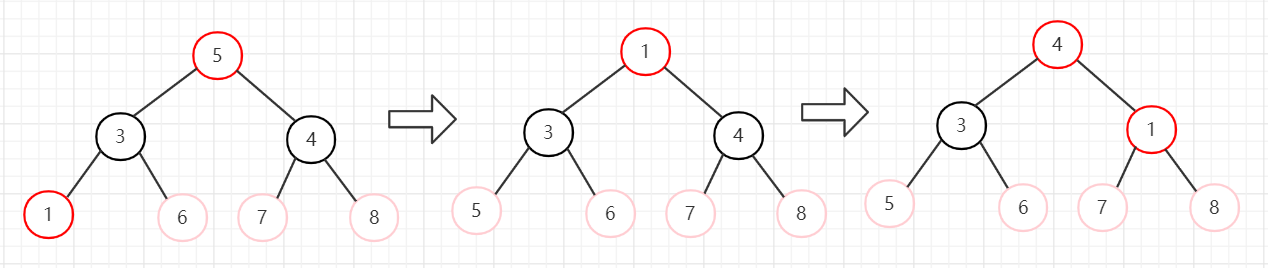
5、节点4和节点1交换,堆长度减一,忽略节点4。然后从堆顶向下调整。
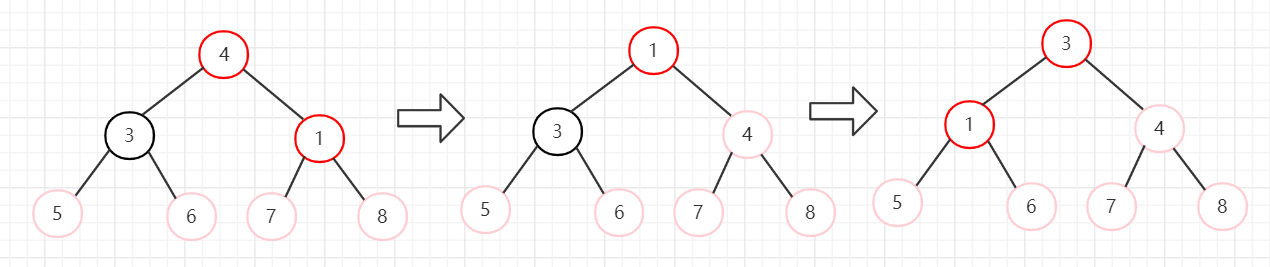
6、节点3和节点1交换,堆长度减一,忽略节点3。然后从堆顶向下调整。
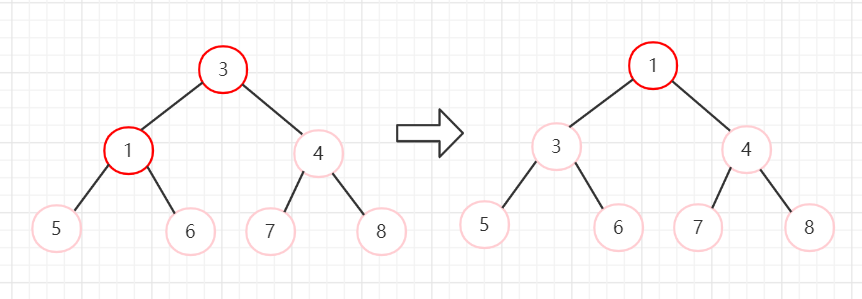
7、堆排序完成,当前序列已经有序。
总结
(1)将无序序列构建成一个堆,根据升序或降序需求选择大顶堆或小顶堆。
(2)将堆顶元素与末尾元素交换,将最大元素换到堆的末尾。
(3)重新调整堆的结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行,直到排序完成。
代码实现
/**
* 堆排序
* @Author distance
*/
public class HeapSort {
private static void shiftDown(int[] heap, int heapLen, int i) {
int temp, mark; // mark 标记最大的点下标
// 下标从 0 开始的 i 节点,左子节点 i*2+1,右子节点 i*2+2
while (i * 2 + 1 < heapLen) {
int left = i * 2 + 1, right = i * 2 + 2;
if (heap[i] < heap[left]) {
mark = left;
} else {
mark = i;
}
if (right < heapLen) { // 右子节点存在
if (heap[mark] < heap[right]) {
mark = right;
}
}
if (mark != i) { // 交换 i 位置 和 mark 位置的值
temp = heap[i];
heap[i] = heap[mark];
heap[mark] = temp;
i = mark; // 继续向下调整
} else { // 停止调整
break;
}
}
}
public static void sort(int[] heap) {
int heapLen = heap.length, temp; // heapLen 堆数组的长度
// 从树的最后一个非叶子结点,开始向下调整
// 调整堆为大根堆,根节点大于左子节点和右子节点
for (int i = (heapLen - 1) / 2; i >= 0; i--) {
shiftDown(heap, heapLen, i);
}
// 堆排序,每次取堆顶最大值,将堆顶的最大值移动到最后
for (int i = 0; i < heap.length; i++) {
temp = heap[0]; // 交换
heap[0] = heap[heapLen - 1];
heap[heapLen - 1] = temp;
heapLen --; // 堆的大小减一,忽略最后点
shiftDown(heap, heapLen, 0); //调整堆,保持为大根堆
}
}
public static void main(String[] args) {
int[] num = {1,8,6,5,3,7,4};
HeapSort.sort(num);
for (int i = 0; i < num.length; i++) {
System.out.print(num[i] + " ");
}
}
}
算法分析
时间复杂度
初始化建堆的时间复杂度为 \(O(n)\),排序重建堆的时间复杂度为 \(O(n\log_2 n)\) ,所以总的时间复杂度为 \(O(n+n\log_2 n)=O(n\log_2 n)\)。
另外堆排序的比较次数和序列的初始状态有关,但只是在序列初始状态为堆的情况下比较次数显著减少,在序列有序或逆序的情况下比较次数不会发生明显变化。
所以堆排序的平均时间复杂度为 O(n*logn)。
算法稳定性
因为在堆的调整过程中,关键字进行比较和交换所走的是该结点到叶子结点的一条路径,因此对于相同的关键字就可能出现排在后面的关键字被交换到前面来的情况。
所以堆排序是一种不稳定排序算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号