re.finditer方法和groups() group() groupdict()
p='''bottle\r\nbag\r\nbig\napple'''
import re
regex=re.compile(r'\bb(?P<middle>\w)(?P<tail>g)')
mat=regex.finditer(p)
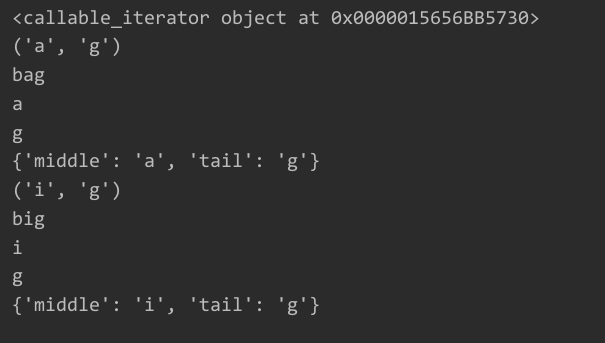
print(mat)
for m in mat:
print(m.groups()) # 匹配到的所有分组(包括命名分组)
# print(m.group()) # m.group() == m.group(0) 匹配到的所有内容,与分组无关
print(m.group(0))
print(m.group(1))
print(m.group(2))
print(m.groupdict())
迭代每个匹配到的整体
groups()取所有分组(包括命名分组)为一个元组
groupdict()取所有命名分组为dict
group()按编号取值(包括命名分组)
都是针对<re.Match object; span(0,6),match='bottle'>对象操作
import re
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile('(b)(\w+)',re.M|re.I)
b=regex.match(p)
print(b)
print(b.groups(),b.group(0),p[b.start():b.end()])
print(b.groupdict())

一个快速取值的方法是b.group()或b.group(0)
import re
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile('(b)(\w+)',re.M|re.I)
b=regex.search(p,1)
print(b.groups())
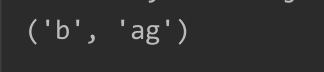
指定起始位置
import re
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile(r'(b\w+)\r\n(?P<name1>b\w+)\r\n(?P<name2>b\w+)')
b=regex.match(p)
print(b)
print('''b.group()= {}'''.format(b.group(0)))
print(b.groups(),b.group(1),b.group(2),b.group(3))
print(b.groupdict())
print(b.groupdict()['name1'])
print(b.groupdict()['name2'])

import re
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile(r'b\w+\r\n(?P<name1>b\w+)\r\n(?P<name2>b\w+)')
b=regex.findall(p)
print(b) # 只匹配到一个,为分组形成的元组
for m in b[0]:
print(type(m),m)

import re
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile(r'(b\w+)\r\n(?P<name1>b\w+)\r\n(?P<name2>b\w+)')
b=regex.findall(p)
print(b) # 只匹配到一个,为分组形成的元组
for m in b[0]:
print(type(m),m)

import re
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile('(?P<head>b\w+)')
b=regex.finditer(p)
print(b)
for m in b: # finditer找到一个匹配,就yield一个re.Match对象
print(type(m),m,m.group(),m.group('head'),m.groupdict()['head'])

import re
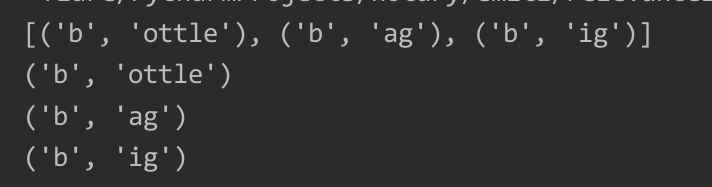
p='''bottle\r\nbag\r\nbig\napple'''
regex=re.compile('(b)(\w+)')
b=regex.findall(p)
print(b) # 如果匹配中有分组,则元素为元组,忽略命名分组
for m in b:
print(m)
import re
s='''os.path([path]) sub-path'''
print(re.split('[^-\w]+',s)) # 将-作为连字符


 浙公网安备 33010602011771号
浙公网安备 33010602011771号