AWK改变输入输出分隔符实例分析
awk默认从STDIN接受数据,打印文本到STDOUT。
awk的默认输入和输出分隔符:
FS : 输入字段分隔符,默认空格。
RS : 输入行分隔符,默认\n。
OFS : 输出字段分隔符,默认空格。
ORS : 输出行分隔符,默认\n。
实例:通过改变默认的内置变量使多行变成一行
file.txt ( 每个人的信息条数不确定,区分是一个空行 )
路人甲
电话: 13777707771
手机: 010-12345678
路人乙
电话: 13912344321
手机: 010-56784321
QQ: 87654221
想要把格式变为:
路人甲 电话:13777707771 手机:010-12345678
路人乙 电话:13912344321 手机:010-56784321 QQ: 87654221
先给出最终命令,再看分析。
awk 'BEGIN{FS="\n";RS="";ORS=""}{for(x=1;x<=NF;x++){print $x"\t"} print "\n"}' ./t.txt
分析:
空行是由两个连续的\n形成的,FS为\n,那么两个连续的\n会形成一个NULL,正好是一个RS,这样就会把一个人的信息读入为一行。现在就是两行数据了。下一步就是输出。
因为默认的OFS就是空格,ORS就是\n,这就是我们想要的,所以
awk 'BEGIN{FS="\n";RS=""}{print $1,$2,$3,$4}' ./t.txt
输出的结果为:
路人甲 电话:13777707771 手机:010-12345678
路人乙 电话:13912344321 手机:010-56784321 QQ: 87654221
这就是我们想要的结果,但是从$1输出到$4不是个好主意,假设一个人最多的记录不止4行呢。
这时我想直接print $0不就行了,和 print $1,$2,$3,$4不是一样的,可结果却是:
awk 'BEGIN{FS="\n";RS=""}{print $0}' ./t.txt
路人甲
电话:13777707771
手机:010-12345678
路人乙
电话:13912344321
手机:010-56784321
QQ: 87654221
和想要的结果有些差别呢,为什么呢?因为OFS在输出$0时不起作用,OFS只用在输出多个域时会插入到每个域之间。
这时我想那就用for循环把每行的每个域print出来好了。于是
awk 'BEGIN{FS="\n";RS=""}{for(x=1;x<=NF;x++){print $x}}' ./t.txt
路人甲
电话:13777707771
手机:010-12345678
路人乙
电话:13912344321
手机:010-56784321
QQ: 87654221
结果好像没什么变化,因为for循环的每个print之后会输出一个ORS,可以指定一个可见的ORS试试看就知道了。
所以需要把ORS指定为"",手动输出换行符。这个就是最开始的命令了。
当我们只指定FS="\n",而不指定RS的时候,RS默认为"\n",这个时候RS的优先级高
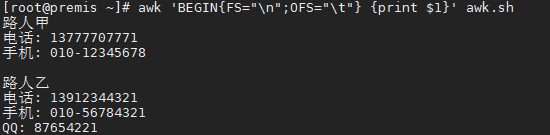
可以看到"\n"是作为了行分隔符

上面"\n"是作为了FS分隔符,因为RS被重新定义了
awk 'BEGIN{FS="\n";RS="";} {$1=$1;print $0}' awk.sh


 浙公网安备 33010602011771号
浙公网安备 33010602011771号