module random
-
random.random() [0,1) 内的float pseudo randomizer
-
random.sample()
-
random.uniform() [a,b] or [a,b) depending on rounding
-
random.randint()
-
random.shuffle()
module collections
-
namedtumple
from collections import namedtuple
Rectangle=namedtuple('Rectangle_class',('length','width'))
vv=Rectangle(11,13)
print(vv.length,vv.width)
print(vv[0],vv[1])
-
defaultdict
from collections import defaultdict
v=defaultdict(int,name='bud',age=29)
print(v)
print(v['addr'])
print(v['bow'])
print(v)
def c():
return 'vvvvv'
bb=defaultdict(lambda :'bbb',name='bud',age=22)
print(bb['addr'])
print(bb['bow'])
print(bb)
3.Counter
from collections import Counter
bb='zxczxcvbnadas'
print(Counter(bb))
print(Counter(bb).most_common(3))
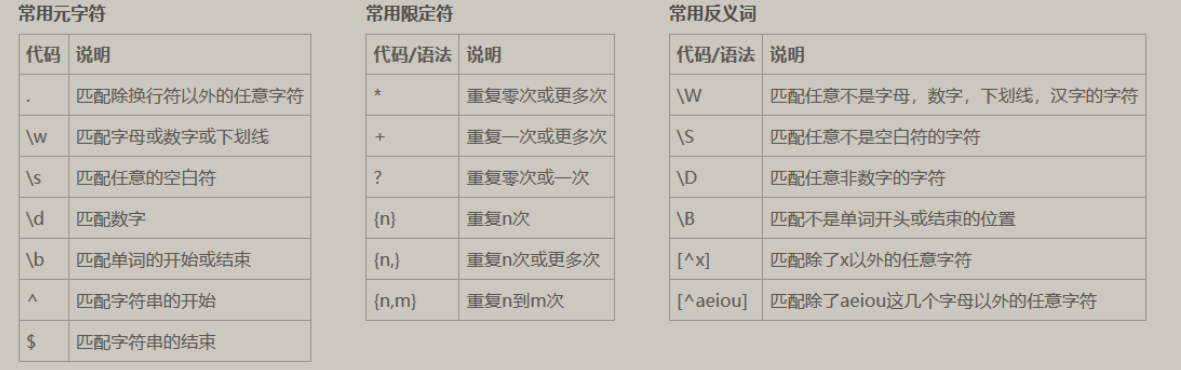
module re
quantifier
-
{n}
-
{n,}
-
{n,m}
-
?
-
+
-
*
-
使用quantifier注意界定范围,经常和()连用
metacharacter
\d [0-9] digit
\D [^\d] [^0-9] non-digit
\w [0-9A-Za-z]
\W [^\w] [^0-9A-Za-z]
\s [ \t\n]
\S [^ \t\n]
\t tab
\n
[]
[^]
^ $
|
()
matching decimal
-
\d+(\.\d+)? -
greedy match & back-track algorithm
\d{3,}6
non-greedy match
\d{3,}?6 ? follows quntifier
1\d??3
133 -> 13 在133这种情况下优先选择13进行匹配
-
.*?X 遇到X就停
-
.*X 最后一个X停止
-
[1-9]\d{14}(\d{2}[\dx])?
-
^([1-9]\d{14}|[1-9]\d{16}[\dx])$
取整数
import re
ret=re.findall(r"\d+\.\d+|(\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret)
ret=filter(lambda v:v,ret)
# ret=[v for v in ret if v]
print(list(ret))
分组命名
import re
exp='<br>flasvlxcv</br>fasdf</a>'
bud=re.search(r'<(?P<tag>\w+)>(.*?)</(?P=tag)>',exp)
print(bud)
print(bud.group())
bow=re.search('<(\w+)>(.*?)</\\1>',exp)
print(bow)
(?P<name>regex) (?P=name)
re.split
import re
dip=re.split('\d+',"eva345egon456yuan")
print(dip)
print(re.split('(\d+)',"eva345egon456yuan"))
print(re.split('\d(\d)\d',"eva345egon456yuan"))
print(re.split('\d(\d)\d',"eva345egon456yuan",1))
import re
dip=re.findall(r'www.(bai|jd).com','www.jd.com')
print(dip)
print(re.split('[ab]','afasmb234'))
print(re.sub('\d','&','eva3egon4yuan4',2))
print(re.subn('\d','$','eva3egon4yuan4',1))
dim=re.compile('\d{3}')
print(dim.search('abc123eeee').group())
dye=re.finditer('\d','ds3sy4784a')
print(dye)
print(dye.__next__)
print(dye.__next__())
print(next(dye))
for v in dye:
print(v.group())
import re
dip=re.compile('\d+')
print(dip.findall('zxc23423vxcvxc354'))
print(dip.search('zxc23423vxcvxc354'))
dim=re.finditer('\d+','zx123bvdf234df23')
print('__iter__' in dir(dim) and '__next__' in dir(dim))
# for v in dim:
# print(v)
for v in dim:
print(v.group())
reptile
import json,re,requests
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
def getPage(vv):
print(vv)
response=requests.get(vv,headers=headers)
print(response,type(response))
return response.text
def parsePage(vv):
# print(vv)
dip=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">\
(?P<title>.*?)</span>.*?<span class="rating_num".*?>(?P<rating_num>.*?)\
</span>.*?<span>(?P<comment_num>.*?)</span>',re.S)
dim=dip.finditer(vv)
for bb in dim:
yield {
'id':bb.group('id'),
'title':bb.group('title'),
'rating_num':bb.group('rating_num'),
'comment_num':bb.group('comment_num'),
}
def main(num):
url='https://movie.douban.com/top250?start=%s&filter=' % num
# print(url)
response_html=getPage(url)
# print(reponse_html)
bow=parsePage(response_html)
print(bow)
f=open('vv',encoding='utf-8',mode='wt')
for xx in bow:
print(xx,type(xx))
data=json.dumps(xx,ensure_ascii=False)
print(type(data),xx==data)
f.write(data+'\n')
if __name__ == '__main__':
count=0
for x in range(10):
main(count)
count+=25

 浙公网安备 33010602011771号
浙公网安备 33010602011771号