线性表的链式存储——线性表的链式存储结构
1,基于顺序存储结构插入或删除元素时候会涉及大量元素移动,非常影响效率,本文着手解决这个问题;
2,链式存储结构为了弥补顺序存储结构效率上的问题;
3,链式存储的定义:

1,为了表示每个数据元素与其后继元素之间的逻辑关系,数据元素除了存储本身的信息外,还需要存储其直接后继的信息;
2,幼儿园排队:每个小朋友记住他前面的小朋友是谁,这样可以轻易的排队;
4,一定要分清 p->next 是左值还是右值,左值时表示节点内存储的位置,右值时表示节点对象;
5,链式存储逻辑结构:
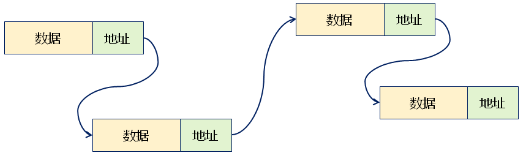
1,基于链式存储结构的线性表中,每个节点都包含数据域和指针域:
1,数据域:存储数据元素本身;
2,指针域:存储相邻节点地址;
6,专业术语:
1,顺序表:
1,基于顺序存储结构的线性表;
2,链表:
1,基于链式存储结构的线性表:
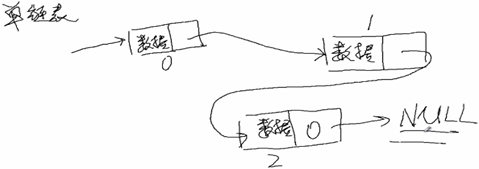
1,单链表:每个节点只包含直接后继的地址信息;
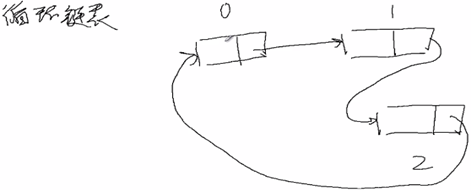
2,循环链表:单链表中的最后一个节点的直接后继为第一个节点;
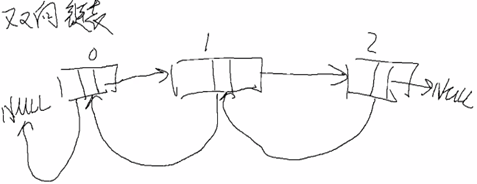
3,双向链表:单链表中的结点包含直接前驱和后继的地址信息;
4,双向循环链表
7,不同类型链表:
1,单链表见:
2,循环链表:
3,双向链表见:
8,链表中的基本概念:
1,头结点:
1,链表中的辅助节点,包含指向第一个数据元素的指针;
2,没什么用,但实际工程中,发现增加头结点代码变简单了、维护性变好了,所以其仅仅辅助我们简化代码,其不包含任何信息,仅仅包含一个指向直接后继的地址;指向的是线性表中的第零个元素;
2,数据节点:
1,链表中代表数据元素的节点,表现形式为:(数据元素,地址);
3,尾结点:
1,链表中的最后一个数据节点,包含的地址信息为空;
2,决定了链表的性质:
1,空,为单链表;
2,第一个节点,为循环链表;
3,随机值,非法链表;
9,单链表中的结点定义:
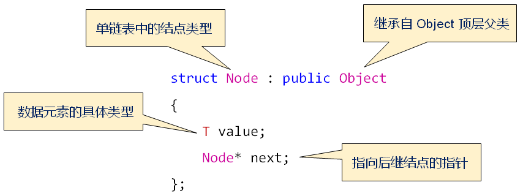
10,单链表中的内部结构:

1,头结点在单链表中的意义:
1,辅助数据元素的定位,方便插入和删除操作,因此,头结点不存储实际的数据元素;
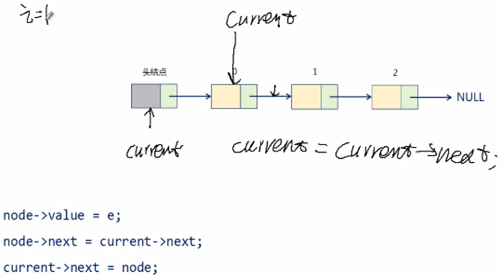
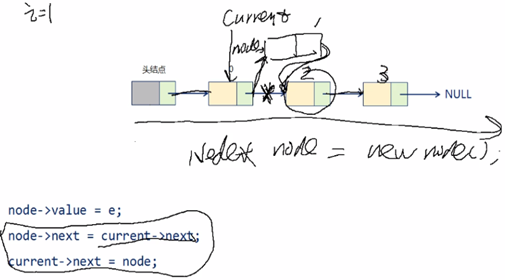
11,在目标位置处插入数据元素:
1,从头结点开始,通过 current 指针定位到目标位置(插入到 i 节点,就移动 i 次;不能随机存取,这是链表缺点);
2,从堆空间申请新的 Node 节点;
3,执行操作(一定要明白指针的左值和右值的含义):
node->value = e;
node->next = current->next;
current->next = node;
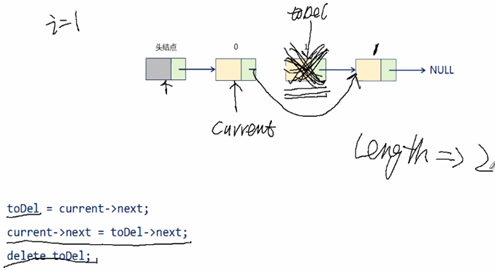
12,在目标位置处删除数据元素:
1,从头结点开始,通过 current 指针定位到目标位置(不能随机存取,这是链表缺点);
2,使用 toDel 指针指向需要删除的节点(保证删除后链表可用);
3,执行操作:
toDel = current->next;(这里是位置上被传递了要删除的对象)
current->next = toDel->next;(删除之前要先指向要删除后面的结点)
delete toDel;
也可以:
current->next = current->next->next;
delete current->next;
13,小结:
1,链表中的数据元素在物理内存中无相邻关系;
2,链表中的节点都包含数据域和指针域;
3,头结点用于辅助数据元素的定位,方便插入和删除操作;
4,插入和删除操作需要保证链表的完整性;
