
题目:论文查重
描述如下:设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
要求输入输出采用文件输入输出,规范如下:
- 从命令行参数给出:论文原文的文件的绝对路径。
- 从命令行参数给出:抄袭版论文的文件的绝对路径。
- 从命令行参数给出:输出的答案文件的绝对路径。
注意:答案文件中输出的答案为浮点型,精确到小数点后两位
解答
思路
首先我找了一下知网的查重率计算,知网认为连续的13字相似就可判定为重复,查重总重复率=重复字数/总字数*100%。
然后我找了一下文本查重的算法,有如下几个:
- 余弦定理计算文本相似度:\(cosA=<a,b>/|a||b|\)
详细的内容点这里:查重算法 - SimHash算法:SimHash算法
大概分为5个步骤:分词、hash、加权、合并、降维 - Jaccard index:Jaccard系数的计算方式为:交集个数和并集个数的比值
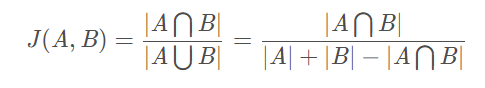
- TF-IDF原理:一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降
\[词频(TF)=某个词在文章中出现的次数/文章的总词数
\]
查完之后 啥也不会 获益良多,在此过程中不断接受新知识的洗礼,这就是传说中的递归学习?
计算模块接口的设计与实现过程
最终我采用了余弦定理计算文本相似度,大概思路如下:
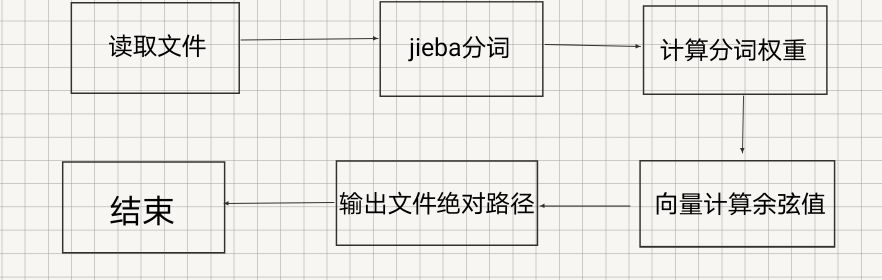
然后就开始疯狂面向GitHub、面向百度、面向同学编程之路。
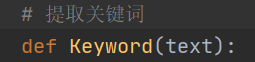
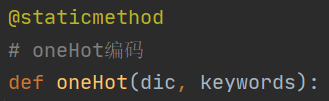
写了一个类:

里面包含的函数如下(具体代码见GitHub):


计算模块接口部分的性能改进
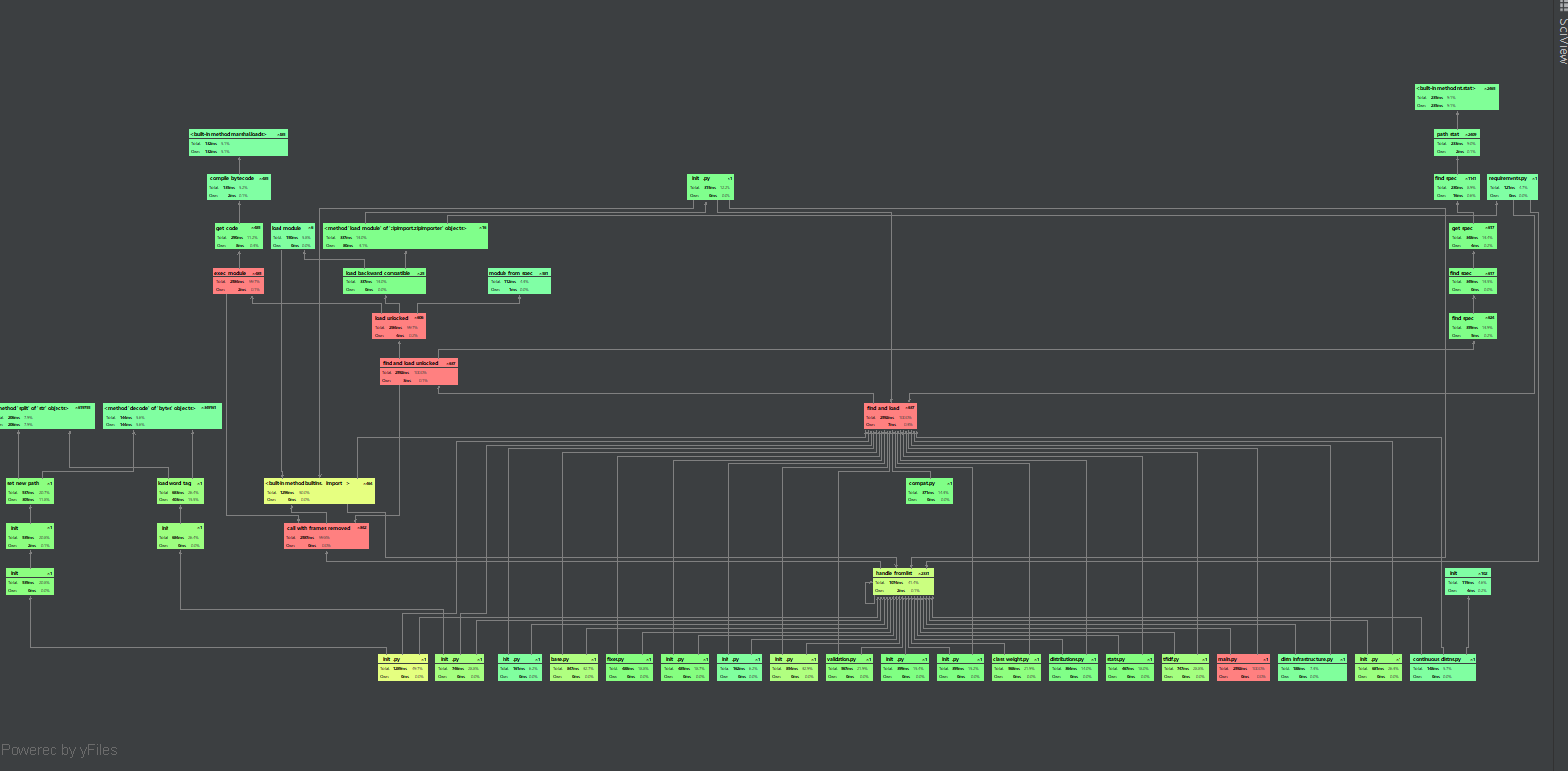
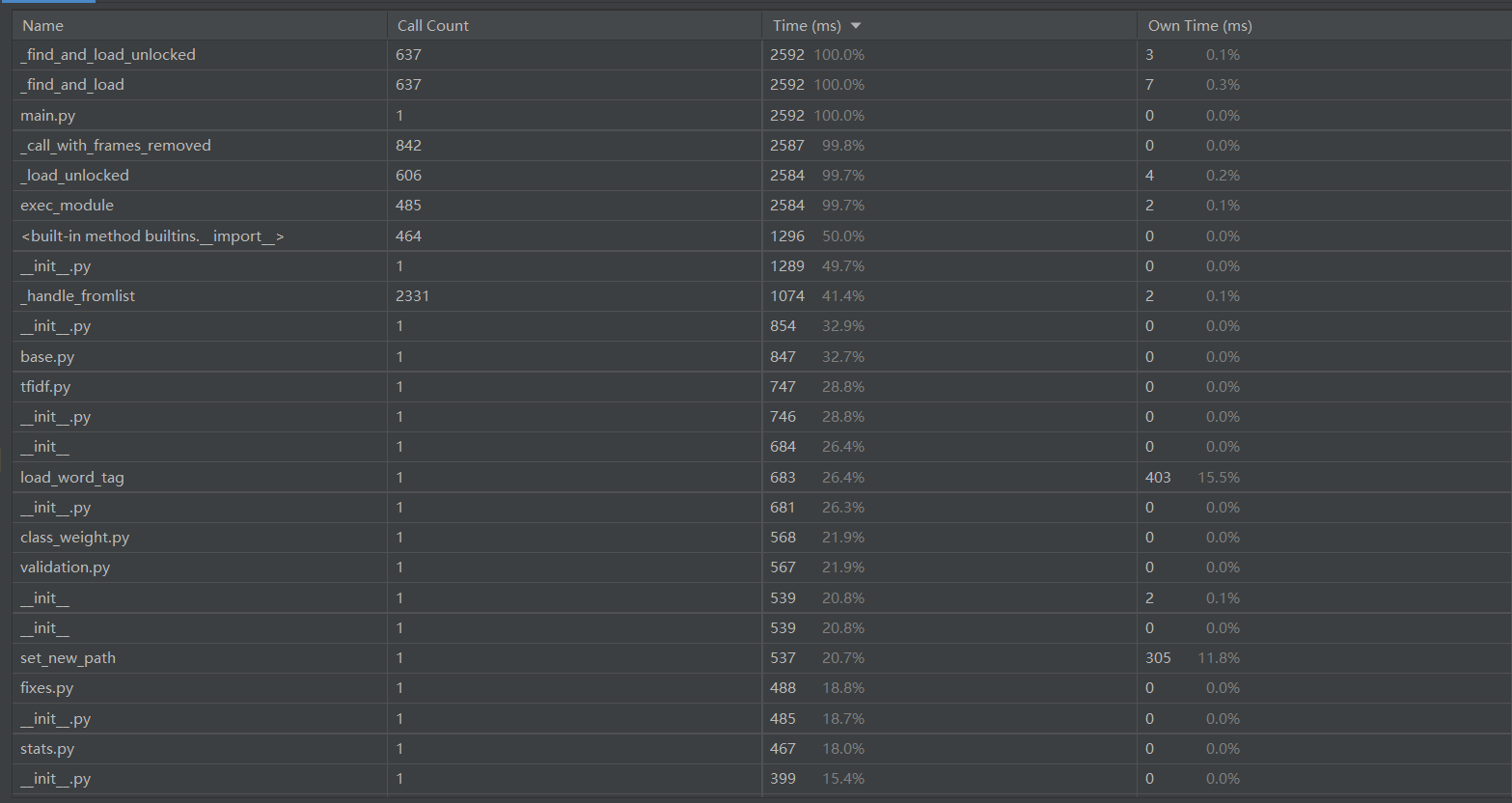
计算模块部分单元测试展示
单元测试代码如下:
import unittest
import jieba
import jieba.analyse
# 用于分词
from sklearn.metrics.pairwise import cosine_similarity
# sklearn中的 cosine_similarity 可直接计算余弦相似度
import sys
# 用于读取命令行参数
class CosineSimilarity(object):
def __init__(self, text1, text2):
self.s1 = text1
self.s2 = text2
@staticmethod
# 提取关键词
def Keyword(text):
cut = [i for i in jieba.cut(text, cut_all=True) if i != '']
keywords = jieba.analyse.extract_tags(",".join(cut), topK=200, withWeight=False)
# 提取关键词,按照权重返回前topK个关键词
return keywords
@staticmethod
# oneHot编码
def oneHot(dic, keywords):
vector = [0] * len(dic)
# 初始化全0向量
for keyword in keywords:
vector[dic[keyword]] += 1
return vector
@staticmethod
# 计算余弦相似度
def calculate(s1_code, s2_code):
try:
sample = [s1_code, s2_code]
sim = cosine_similarity(sample)
# sim[0][1]为 s1 与 s2 的相似度
return sim[0][1]
except Exception as e:
print(e)
return 0.0
# 除0处理
@staticmethod
def constructHash(keywords): # 构造哈希表
dic = {}
hash_value = 0
for keyword in keywords: # 哈希表赋值
dic[keyword] = hash_value
hash_value += 1 # 每个词对应的哈希值从数字0开始递增
return dic
def main(self):
keywords1 = self.Keyword(self.s1)
keywords2 = self.Keyword(self.s2)
# 分别提取文本的关键词
keywords = set(keywords1).union(set(keywords2))
# set去重 关键词取并
dic = self.constructHash(keywords)
s1_code = self.oneHot(dic, keywords1)
s2_code = self.oneHot(dic, keywords2)
# oneHot编码
sim_value = self.calculate(s1_code, s2_code)
return sim_value
# 返回相似度
class MyTest(unittest.TestCase):
def tearDown(self) -> None:
print("test over!")
def test_add(self):
print("orig_0.8_add.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_add.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_del(self):
print("orig_0.8_del.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_del.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_dis_1.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_dis_3.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_dis_7.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_dis_10.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_dis_15.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_rep(self):
print("orig_0.8_rep.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_rep.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_mix(self):
print("orig_0.8_mix.txt 相似度")
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/sim_0.8/orig_0.8_mix.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
if __name__ == '__main__':
unittest.main()
构建思路
测试代码在本地完成,读取文件夹下的所有文件名,接着读入原文和修改过的文章,创建一个CosineSimilarity对象,调用对象的calculate方法,最后对结果保留两位小数并写入输出文件。
测试结果
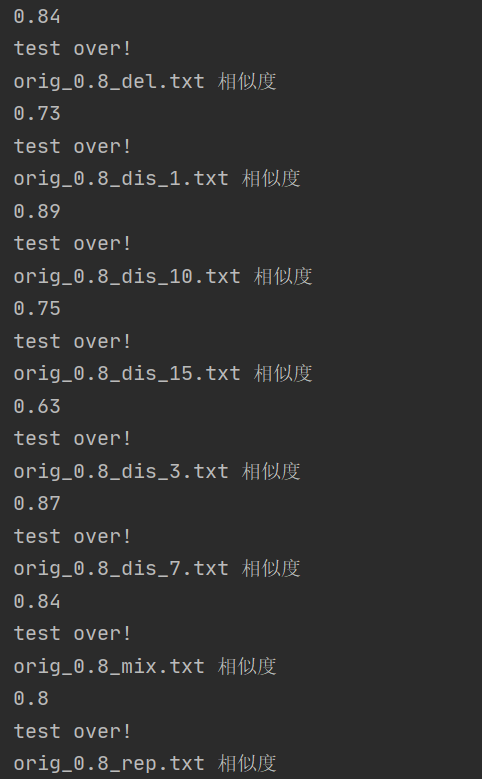
覆盖率

(具体覆盖率报告导不出来就很难受QAQ!)
计算模块部分异常处理说明
我觉得有三种异常:①两个文本都是空文本 ②两个文本内容一模一样 ③路径异常
代码如下:
def test_empty(self):
print("源文本和抄袭文本均为空的情况")
with open("D:/python_work/pycharmWork/ChaChong/tt.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/empty.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
def test_same(self):
print("源文本和抄袭文本内容完全相同的情况")
with open("D:/python_work/pycharmWork/ChaChong/same1.txt", "r", encoding='UTF-8') as fp:
origin = fp.read()
with open("D:/python_work/pycharmWork/ChaChong/same2.txt", "r", encoding='UTF-8') as fp:
copy = fp.read()
similarity = CosineSimilarity(origin, copy)
similarity = round(similarity.main(), 2)
print(similarity)
PSP表格

心得总结
- 一开始就是炸裂的开场,感觉无从下手,各种要求看都看不懂。在大佬的交流中听到了一些方法,然后学会了在博客上、GitHub上学习,学习先提交了博客的大佬们的解题思路,拥抱开源代码(开源代码天下一!!!)。
- 在这过程中我学会了使用GitHub,对Python有了更加深入的了解、认识和应用,Python🐮就完事了。
- 以后得多学习算法,多看大佬代码,不然就只会写农民代码。
- 与诸位共勉!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号