Linux 服务器监控
http://www.cnblogs.com/chenmh/p/5072704.html
标签:iostat/free/top/dstat
概述
文字主要讲述使用linux自带的几个命令监控io、CPU、磁盘、内存、服务器整体信息等。
IO监控
iostat命令
主要用于监控系统设备的IO负载情况
查看命令帮助
iostat --help [ -c ] [ -d ] [ -N ] [ -n ] [ -h ] [ -k | -m ] [ -t ] [ -V ] [ -x ] [ -z ][ <设备> [...] | ALL ] [ -p [ <设备> [,...] | ALL ] ]
iostat
Linux 2.6.32-71.el6.x86_64 (localhost.localdomain) 2015年12月24日 _x86_64_(1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.98 0.00 0.80 3.04 0.00 94.18
%user:进程处于用户状态所占CPU时间百分比
%nice: 改变过优先级的进程的占用CPU的百分比.
%system:进程处于内核状态所占CPU时间百分比
%iowait:CPU等等IO操作所占用的CPU百分比,当磁盘IO比较大的时候该值会增加。
%steal:分配给虚拟机占用的CPU百分比
%idle:CPU空闲时间的百分比
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 17.78 128.39 1107.66 9968098 86000772
tps: 每秒钟发送到的I/O请求数(可以理解成每秒磁盘IO处理的请求,这样可能更好理解)Blk_read /s: 每秒读取的block数Blk_wrtn/s: 每秒写入的block数
Blk_read: 读入的block总数
Blk_wrtn: 写入的block总数
-c参数:
分成CPU的状态,也就是上面的CPU部分
-d参数
分析磁盘设备状态,也就是上面的Device部分。
-n参数
分析文件系统的状态
Filesystem: rBlk_nor/s wBlk_nor/s rBlk_dir/s wBlk_dir/s rBlk_svr/s wBlk_svr/s ops/s rops/s wops/s
[-N或者-h]参数
和直接运行iostat的区别主要是device部分,这里显示的是设备每秒的读写、读写字节情况,默认是kB
avg-cpu: %user %nice %system %iowait %steal %idle
2.06 0.00 0.82 3.09 0.00 94.03
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 18.20 65.63 556.45 5169933 43834154
kB_read/s:每秒从设备读的KB数
kB_wrtn/s:每秒写入设备的KB数
kB_read:每秒从设备读的KB字节
kB_wrtn:每秒写入设备的KB字节
[ -k | -m ]参数
是单位,分别是KB和MB,默认单位是KB,用来做磁盘分析的时候使用
例如iostat -d -M(以MB作为单位显示)
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 18.65 0.06 0.55 5102 43654
-t参数
显示的时候打印出时间
2015年12月24日 09时39分31秒
avg-cpu: %user %nice %system %iowait %steal %idle
2.07 0.00 0.83 3.17 0.00 93.94
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 18.59 131.96 1128.88 10450530 89403980
[-v或-Z]参数
暂时没发现什么特别的功能
-x参数
最详细的显示CPU和设备信息
avg-cpu: %user %nice %system %iowait %steal %idle
2.06 0.00 0.83 3.16 0.00 93.96
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 1.58 125.86 2.49 16.04 131.51 1124.71 67.80 0.41 22.29 2.69 4.98
其中CPU部分没有什么变化,这里主要来看device部分:
rrqm/s:将读入请求合并后,每秒发送到设备的读入请求数.
wrqm/s:将写入请求合并后,每秒发送到设备的写入请求数.
r/s:每秒发送到设备的读入请求数.
w/s:每秒发送到设备的写入请求数.
rsec/s:每秒从设备读入的扇区数.
wsec/s:每秒向设备写入的扇区数.
rkB/s:每秒从设备读入的数据量,单位为K.
wkB/s:每秒向设备写入的数据量,单位为K.
avgrq-sz:发送到设备的请求的平均大小,单位是扇区.
avgqu-sz:发送到设备的请求的平均队列长度.
await:I/O请求平均执行时间.包括发送请求和执行的时间.单位是毫秒.
svctm:发送到设备的I/O请求的平均执行时间.单位是毫秒.
%uti:在I/O请求发送到设备期间,占用CPU时间的百分比.用于显示设备的带宽利用率.
当这个值接近100%时,表示设备带宽已经占满.
-P参数
分析指定的设备:例如sda,sdb
iostat -p sda
avg-cpu: %user %nice %system %iowait %steal %idle
2.05 0.00 0.82 3.13 0.00 93.99
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 18.40 130.78 1116.56 10472250 89406772
sda1 0.01 0.07 0.00 5232 28
sda2 16.72 118.34 1089.36 9476202 87228408
sda3 0.36 12.36 27.20 989616 2178336
常见的用法:
显示设备和CPU状态,每秒打印一次,并显示时间
iostat -x -k -t 1
显示设备和CPU状态,每秒显示一次,显示10次,并显示时间
iostat -x -k -t 1 10
显示设备sda和CPU状态,每秒显示一次,显示10次,并显示时间
iostat -x -k -t -p sda 1 10
CPU监控
mpstat
mpstat命令主要用来分析CPU的性能,并且可以分析单个cpu的性能状态。
mpstat -P ALL
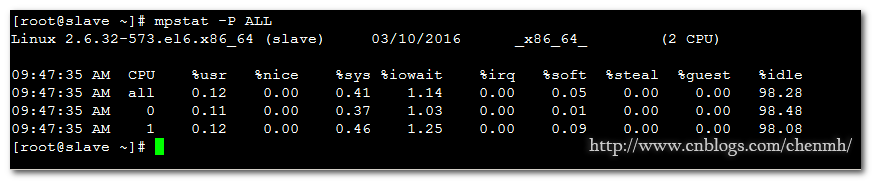
%user:进程处于用户状态所占CPU时间百分比
%nice: 改变过优先级的进程的占用CPU的百分比.
%system:进程处于内核状态所占CPU时间百分比
%iowait:CPU等等IO操作所占用的CPU百分比,当磁盘IO比较大的时候该值会增加。
%steal:分配给虚拟机占用的CPU百分比
%idle:CPU空闲时间的百分比
内存监控
free命令
free total used free shared buffers cached Mem: 32830608 32501660 328948 0 285540 10956472 -/+ buffers/cache: 21259648 11570960 Swap: 16383992 216520 16167472
free:内存中剩余未被使用的空间大小
buffers:文件缓存大小,linux本身就是一个文件型系统,所以linux会为每个文件进行缓存用来加速文件的查找。
cached:页缓存,所有以页为单位的缓存都会被缓存到这来,所以从这里其实也可以大概看出服务器的内存使用情况,因为大部分的内存都是以页进行缓存的
total=used+free
total=(-buffers/cache)+(+buffers/cache)
-/+ buffers/cache:反应的是内存的实际使用情况
-buffers/cache:21259648=used-buffers-cached,这部分也是真正被使用掉的内存
+buffers/cache:11570960=(free+buffers+cached),这部分是可以直接拿来用的内存,所以看内存的剩余可用情况可以参考+buffers/cache
查看文件/etc/proc/ meminfo
注意:还需要关注swap:used,如果swap:used使用很高那么可能需要考虑内存是否够用。
磁盘监控
df命令
查看文件cat /etc/proc/diskstats
进程监控
top命令
例:查看mysql用户进程
top -u mysql
top - 11:45:50 up 1 day, 23:39, 1 user, load average: 0.04, 0.01, 0.00 Tasks: 185 total, 2 running, 183 sleeping, 0 stopped, 0 zombie Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 99.5%id, 0.1%wa, 0.0%hi, 0.0%si, 0.0%st Mem: 32864496k total, 4749428k used, 28115068k free, 167268k buffers Swap: 1048572k total, 0k used, 1048572k free, 259776k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND mysql 20 0 27.5g 3.8g 8236 S 0.3 12.1 7:56.92 mysqld
top这行信息可以参考下面的uptime的解释。load average分别表示5分钟内的、10分钟内的、15分钟内排队的进程数,只要第一个数字即5分钟内的负载不大于5,系统就是健康的
tasks:185个进程总数,2个正在运行的进程,183个睡眠的进程,0个停止的进程,0个僵尸进程
cpu:0.1%us(用户占用), 0.2%sy(系统占用), 0.0%ni, 99.5%id(空闲), 0.1%wa(等待输入输出的CPU时间百分比), 0.0%hi, 0.0%si, 0.0%st
Mem: 32864496k total(总内存), 4749428k used(已使用内存), 28115068k free(未使用的内存), 167268k buffers(内核缓存)
Swap: 1048572k total(交换区总大小), 0k used(已使用), 1048572k free(未使用), 259776k cached(缓冲的交换区总量)
PID:进程ID
USER:用户
PR:优先级
NI:nice值。负值表示高优先级,正值表示低优先级
S:进程状态(R:运行,S:睡眠,T:停止,Z:僵尸进程,D:不可中断的睡眠状态)
%CPU:占用的CPU百分比
%MEM:占用的内存百分比
TIME+:累计占用的CPU时间
COMMAND:命令
进程信息只列举了一些重要的字段,其它的字段如果想了解可以去查看资料。
这里有每个进程的文件:/etc/proc
注意:在top里面除了关注每个进程的内存使用情况,还需要关注的就是{load average: 0.04, 0.01, 0.00}进程负载情况。
系统负载
uptime命令
10:18:23 up 22:43, 3 users, load average: 0.00, 0.00, 0.79
- 当前时间 10:18:23
- 系统已运行的时间 22小时43分钟
- 当前在线用户 3 user
- 平均负载:0.00, 0.00, 0.79最近1分钟、5分钟、15分钟系统的负载
查看文件
cat /proc/loadavg
0.00 0.00 0.70 1/317 41562
除了前3个数字表示平均进程数量外,后面的1个分数,分母表示系统进程总数,分子表示正在运行的进程数;最后一个数字表示最近运行的进程ID
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
一般来说,每个CPU内核当前活动进程数不大于3,则系统运行表现良好!当然这里说的是每个cpu内核,也就是如果你的主机是四核cpu的话,那么只要uptime最后输出的一串字符数值小于12即表示系统负载不是很严重.当然如果达到20,那就表示当前系统负载非常严重,估计打开执行web脚本非常缓慢.
uptime部分摘自:http://www.cnblogs.com/kaituorensheng/p/3602812.html
vmstat命令
该命令可以用来分析整个服务器的基本情况,包括内存、交换分区、IO、system、cpu
vmstat

网络流量监控
可以使用nload工具来做网络流量监控,该工具可以动态的显示流入和流出的网络流量
yum -y install nload

总结
linux系统自带的这几个命令做为日常监控使用还是挺不错的,当然还有很多第三方工具也很不错,比如监控IO的dstat工具,后面有时间会单独讲一下dstat工具的使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号