zookeeper集群
0,Zookeeper基本原理
ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower。当客户端Client连接到ZooKeeper集群,并且执行写请求时,这些请求会被发送到Leader节点上,然后Leader节点上数据变更会同步到集群中其他的Follower节点。
ZooKeeper采用一种称为Leader election的选举算法(也有称做:分布式选举算法-Paxos)的。在整个集群运行过程中,只有一个Leader,其他的都是Follower,如果ZooKeeper集群在运行过程中Leader出了问题,系统会采用该算法重新选出一个Leader,
ZooKeeper用于三台以上的服务器集群之中,只要还有超过半数的服务器在线,ZooKeeper就能够正常提供服务,过半,意味着实际能够有效参与选举的节点数量是奇书个数,否者不能有效的过半
Zookeeper逻辑图如下,
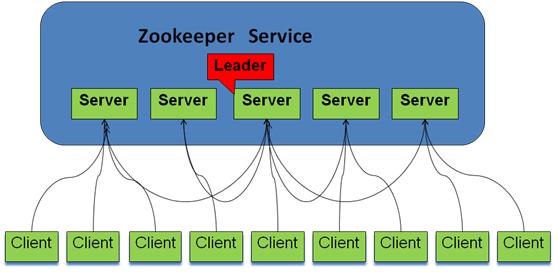
- 客户端可以连接到每个server,每个server的数据完全相同。
- 每个follower都和leader有连接,接受leader的数据更新操作。
- Server记录事务日志和快照到持久存储。
- 大多数server可用,整体服务就可用。
- Leader节点在接收到数据变更请求后,首先将变更写入本地磁盘,以作恢复之用。当所有的写请求持久化到磁盘以后,才会将变更应用到内存中。
- ZooKeeper使用了一种自定义的原子消息协议,在消息层的这种原子特性,保证了整个协调系统中的节点数据或状态的一致性。Follower基于这种消息协议能够保证本地的ZooKeeper数据与Leader节点同步,然后基于本地的存储来独立地对外提供服务。
- 当一个Leader节点发生故障失效时,失败故障是快速响应的,消息层负责重新选择一个Leader,继续作为协调服务集群的中心,处理客户端写请求,并将ZooKeeper协调系统的数据变更同步(广播)到其他的Follower节点。
1,系统环境配置
我这里使用的是在VMWare中安装centos7每个虚拟机都选择桥接模式。即可在网络中独立分配一个IP,每台机器单独设定一个IP。
- 配置hosts:vi /etc/hosts
123
192.168.137.122master192.168.137.123slave1192.168.137.124slave2
- 关闭防火墙 (很重要,不然会出现No rout to host异常)
123
systemctl status firewalld.service #检查防火墙状态systemctl stop firewalld.service #关闭防火墙systemctl disable firewalld.service #禁止开机启动防火墙
- 关闭SELINUX:vi /etc/selinux/config
123
#SELINUX=enforcing #注释掉#SELINUXTYPE=targeted #注释掉SELINUX=disabled #增加 - 4. 立即生效配置
setenforce 0 #使配置立即生效
2,java安装环境变量配置
略
3,配置无密钥的SSH访问
在此处为了方便,我将所有网内的节点机器都互相能SSH无密钥登录,可以理解为双向无密钥登录。
- 使用下列命令在每个虚拟机上都生成密钥
1
ssh-keygen -t rsa #生成密钥,一路回车即可,只适用于测试环境,正式环境请设定密码 - 每个节点机器的公钥传输到master机器上
12
scp ~/.ssh/id_rsa.pub master:~/.ssh/slave1.id_rsa.pub #在slave1中,将公钥文件传输至master机器上,并修改文件名为slave1.id_rsa.pubscp ~/.ssh/id_rsa.pub master:~/.ssh/slave2.id_rsa.pub #在slave2中,将公钥文件传输至master机器上,并修改文件名为slave2.id_rsa.pub - 在master机器上生成统一的authorized_keys
1234
cd ~/.sshcat id_rsa.pub >> authorized_keys #这个是master生成的公钥,就在本机cat slave1.id_rsa.pub >> authorized_keyscat slave2.id_rsa.pub >> authorized_keys完成后可以使用rm -f slave1.id_rsa.pub删除拷贝过来的秘钥文件
- 将统一的authorized_keys分发至每个节点
12
scp authorized_keys root@master1:~/.sshscp authorized_keys root@master2:~/.ssh
authorized_keys是公钥的字典文件,这样下来所有的,所有节点的authorized_keys文件中记录的秘钥都相同了,因为可以实现每个机器的ssh互通了。
4,Zookeeper集群安装
zookeeper安装非常简单,只要获取到 Zookeeper 的压缩包并解压到某个目录,修改一下配置即可。
- 下载zookeeper-3.4.8,使用下列命令解压到指定路径
1
tar -zxvf zookeeper-3.4.8.tar.gz <br>mv zookeeper-3.4.8/home/zookeeper #这里可以指定你喜欢的任意目录 - 修改环境变量:vi /etc/profile 加入下列内容
123
# set zookeeperpathexport ZOOKEEPER_HOME=/home/zookeeperexport PATH=$PATH:$ZOOKEEPER_HOME/bin - 使用下面命令复制配置文件(也可直接建立)
1
cp /home/zookeeper/conf/zoo_sample.cfg /home/zookeeper/conf/zoo.cfg - 使用 vi /home/zookeeper/conf/zoo.cfg 修改配置文件,具体内容如下:
1234567891011121314151617181920212223242526272829303132
# The number of milliseconds of each ticktickTime=2000# The number of ticks that the initial# synchronization phase can takeinitLimit=10# The number of ticks that can pass between# sending a request and getting an acknowledgementsyncLimit=5# the directory where the snapshot is stored.#donot use /tmpforstorage, /tmp here is just# example sakes.dataDir=/home/zookeeper/zkdatadataLogDir=/home/zookeeper/zklog# the port at which the clients will connectclientPort=2181# the maximum number of client connections.# increasethisifyou need to handle more clients#maxClientCnxns=60## Be sure to read the maintenance section of the# administrator guide before turning on autopurge.## http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance## The number of snapshots to retain in dataDir#autopurge.snapRetainCount=3# Purge task interval in hours# Set to"0"to disable auto purge feature#autopurge.purgeInterval=1server.1=master:2888:3888server.2=slaver1:2888:3888server.3=slaver2:2888:3888tickTime: zookeeper中使用的基本时间单位, 毫秒值.
dataDir: 数据目录. 可以是任意目录.
dataLogDir: log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置.
clientPort: 监听client连接的端口号.
nitLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。 - 创建myid文件:在zoo.cfg指定的dataDir目录下建立以服务器节点对应的myid文件,如master节点中,创建myid文件内容为1,slave1中创建myid文件内容为2...
- 使用下列命令将zoopeeper拷贝到其他节点
12
scp /home/zookeeper root@master1: /home/scp /home/zookeeper root@master2: /home/完成后,只需在其他节点上修改vi /etc/profile,以及对应的myid,即可
4,启动Zookeeper集群
- 在所有节点执行下列命令启动
12
cd /home/zookeeperbin/zkServer.sh start正常会显示如下状态

- 使用jps命令查看系统进程

- 使用下列命令检查运行状态
1
bin/zkServer.sh -status如显示一下状态表示启动失败
具体失败原因可阅读zookeeper/zookeeper.out文件查阅 如显示一下状态表示启动成功

查看其余节点,整个包括集群中各个结点的角色会有一个leader,其他都是follower。
我们通过more zookeeper.out检查启动输入日志,会发现有下列异常
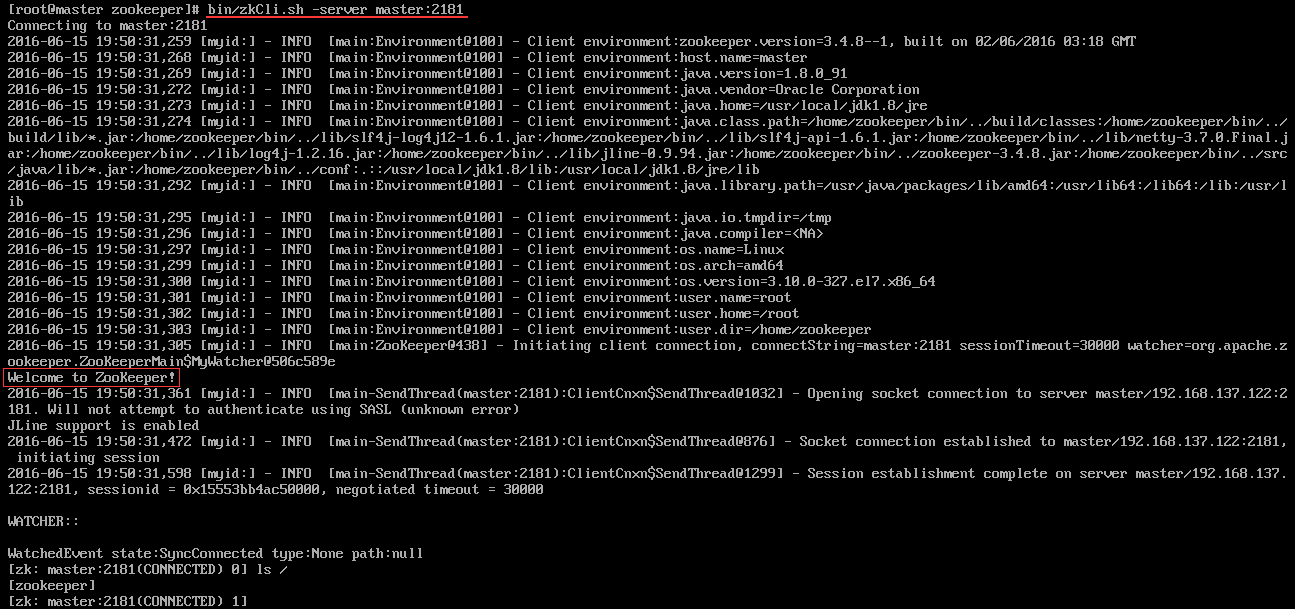
我启动的顺序是master>slave1>slave2,由于ZooKeeper集群启动的时候,每个结点都试图去连接集群中的其它结点,先启动的肯定连不上后面还没启动的,所以上面日志前面部分的异常是可以忽略的。通过后面部分可以看到,集群在选出一个Leader后,最后稳定了。 其他结点可能也出现类似问题,属于正常。 - 客户端连接测试: 对于客户端来说,ZooKeeper是一个整体(ensemble),无论连接到那个节点,实际上都在独享整个ZooKeeper集群的服务,所以,我们可以在任何一个结点上建立到服务集群的连接
5,参考
- zookeeper项目使用几点小结 http://agapple.iteye.com/blog/1184023
- ZooKeeper架构设计及其应用要点 http://shiyanjun.cn/archives/474.html
- ZooKeeper原理及使用 http://blog.csdn.net/xinguan1267/article/details/38422149
- Zookeeper 的学习与运用 http://blog.jiguang.cn/push_zookeeper_study_usage/
- Zookeeper-Zookeeper leader选举 http://www.cnblogs.com/yuyijq/p/4116365.html
- zookeeper原理 http://cailin.iteye.com/blog/2014486
http://www.cnblogs.com/ejiyuan/p/5587700.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号