

Spark- word Count案例
1. 新建项目
新建 idea Maven项目工程, 并创建子工程,pom.xml文件中引入spark依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>dintalk-classes</artifactId> <groupId>cn.dintalk.bigdata</groupId> <version>1.0.0</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>spark-core</artifactId> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.1.1</version> </dependency> </dependencies> </project>
2.准备数据文件
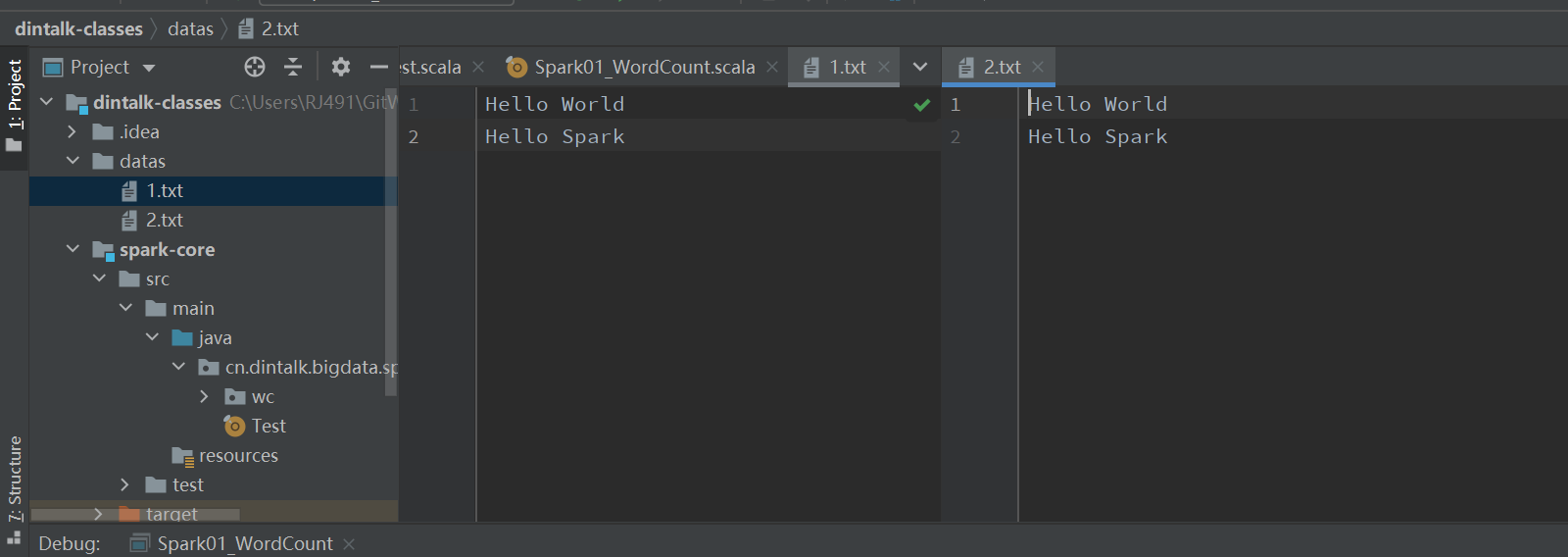
3.代码编写
3.1第一种写法
package cn.dintalk.bigdata.spark.core.wc import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Spark01_WordCount { def main(args: Array[String]): Unit = { // application -> spark 框架 // 1. 建立 和 Spark框架的连接 // JDBC 有 connection , Spark 有 SparkContext val sparkConf= new SparkConf() .setMaster("local") .setAppName("wordCount") val sc = new SparkContext(sparkConf) // 2. 执行业务操作 // 2.1 读取文件, 获取一行一行的数据 val lines: RDD[String] = sc.textFile("datas") // 2.2 将行数据进行切分,形成一个一个的单词 val words: RDD[String] = lines.flatMap(_.split(" ")) // 2.3 将数据按照单词进行分组,便于统计 val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word) // 2.4 对分组后的数据进行转换 // (hello,hello,hello), (word,word) -> (hello,3),(word,2) val wordCount: RDD[(String, Int)] = wordGroup.map { case (word, list) => { (word, list.size) } } // 2.5 将转换结果采集到控制台输出 val tuples: Array[(String, Int)] = wordCount.collect() tuples.foreach(println) // 3. 关闭连接 sc.stop() } }
package cn.dintalk.bigdata.spark.core.wc import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Spark02_WordCount { def main(args: Array[String]): Unit = { // application -> spark 框架 // 1. 建立 和 Spark框架的连接 // JDBC 有 connection , Spark 有 SparkContext val sparkConf= new SparkConf() .setMaster("local") .setAppName("wordCount") val sc = new SparkContext(sparkConf) // 2. 执行业务操作 // 2.1 读取文件, 获取一行一行的数据 val lines: RDD[String] = sc.textFile("datas") // 2.2 将行数据进行切分,形成一个一个的单词 val words: RDD[String] = lines.flatMap(_.split(" ")) val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1)) val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne .groupBy(t => t._1) val wordCount: RDD[(String, Int)] = wordGroup.map { case (word, list) => { list.reduce( (t1, t2) => { (t1._1, t1._2 + t2._2) } ) } } // 2.5 将转换结果采集到控制台输出 val tuples: Array[(String, Int)] = wordCount.collect() tuples.foreach(println) // 3. 关闭连接 sc.stop() } }
package cn.dintalk.bigdata.spark.core.wc import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Spark03_WordCount { def main(args: Array[String]): Unit = { val sparkConf= new SparkConf() .setMaster("local") .setAppName("wordCount") val sc = new SparkContext(sparkConf) val lines: RDD[String] = sc.textFile("datas") val words: RDD[String] = lines.flatMap(_.split(" ")) val wordToOne: RDD[(String, Int)] = words.map((_, 1)) val wordCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _) val tuples: Array[(String, Int)] = wordCount.collect() tuples.foreach(println) sc.stop() } }

4.log4j控制日志输出
4.1resources目录下新建log4j.properties并 配置
log4j.rootLogger=ERROR, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=../log/agent.log log4j.appender.R.MaxFileSize=10240KB log4j.appender.R.MaxBackupIndex=1 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%n
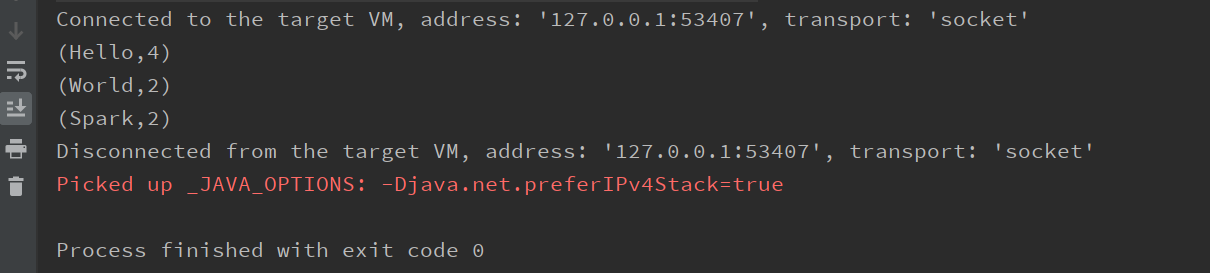
4.2验证日志输出
无多余日志的输出
作者:Mr.SongHui
欢迎转载,但必须给出原文链接,并保留此段声明。
粉丝福利:
【腾讯云·年末有礼】云产品限时秒杀,云服务器1核2G,首年128元
【腾讯云】海外1核2G服务器低至2折,半价续费券限量免费领取!
【腾讯云】专属福利,新客户无门槛领取总价值高达2860元代金券,每种代金券限量500张,先到先得
【腾讯云】热卖云产品3折起,云服务器、云数据库特惠,服务更稳,速度更快,价格更优
【腾讯云】腾讯云服务器安全可靠高性能,多种配置供您选择
【腾讯云】助力中小微企业上云,满足轻量级Web应用需求,云服务器钜惠 166元/年起
【腾讯云】云数据库全场年购3折起,新用户上云6个月仅需10元
【腾讯云】腾讯云数据库性能卓越稳定可靠,为您解决数据库运维难题
【腾讯云】腾讯云图,像PPT一样简单的数据可视化工具。5元搞定数据可视化,模板丰富,拖拖拽拽就能做出好看的可视化大屏
【腾讯云】流量包低至0.12元/GB , 结合在线教育、电商直播、社交直播场景,提供IM+直播+点播音视频组合优惠
【腾讯云】Redis单机版特惠2.1折起,为缓存业务量身定制,新用户8元起购
【腾讯云】专业版APP加固特惠5折起,可享免费兼容性测试
【腾讯云】专属福利,新客户无门槛领取总价值高达2860元代金券,每种代金券限量500张,先到先得
【腾讯云·年末有礼】云产品限时秒杀,云服务器1核2G,首年128元
【腾讯云】海外1核2G服务器低至2折,半价续费券限量免费领取!
【腾讯云】专属福利,新客户无门槛领取总价值高达2860元代金券,每种代金券限量500张,先到先得
【腾讯云】热卖云产品3折起,云服务器、云数据库特惠,服务更稳,速度更快,价格更优
【腾讯云】腾讯云服务器安全可靠高性能,多种配置供您选择
【腾讯云】助力中小微企业上云,满足轻量级Web应用需求,云服务器钜惠 166元/年起
【腾讯云】云数据库全场年购3折起,新用户上云6个月仅需10元
【腾讯云】腾讯云数据库性能卓越稳定可靠,为您解决数据库运维难题
【腾讯云】腾讯云图,像PPT一样简单的数据可视化工具。5元搞定数据可视化,模板丰富,拖拖拽拽就能做出好看的可视化大屏
【腾讯云】流量包低至0.12元/GB , 结合在线教育、电商直播、社交直播场景,提供IM+直播+点播音视频组合优惠
【腾讯云】Redis单机版特惠2.1折起,为缓存业务量身定制,新用户8元起购
【腾讯云】专业版APP加固特惠5折起,可享免费兼容性测试
【腾讯云】专属福利,新客户无门槛领取总价值高达2860元代金券,每种代金券限量500张,先到先得
[需要广告托管服务的朋友请留步哦]


 浙公网安备 33010602011771号
浙公网安备 33010602011771号