Llama3技术文档
(paper来源于https://ai.meta.com/research/publications/the-llama-3-herd-of-models/)
Introduction
基础模型开发包含两个阶段:
- 预训练阶段(a pre-training stage)。以简单的任务如预测下一个字的方式大规模训练。
- 后训练阶段(a post-training stage)。调优为来指令跟随(follow instructions),对齐人类偏好(align with human preferences),提高特定能力(如编程和推理)
我们相信在高质量基础模型开发中有三个杠杆: - 数据。相对于之前版本,提高了数据数量和质量。Llama 3 15T Llama2 1.8T。
- 规模。405B旗舰模型。
- 复杂度控制。最大化稳定性,选择标准dense transformer而不是专家混合模型(a mixture-of-experts model)。采用相对简单的后训练策略,采用supervised finetuning (SFT), rejection sampling (RS), and direct preference optimization(DPO)而不是更加复杂的强化学习算法。
![]()
Llama3包含8B,70B和405B。
General Overview
Llama3
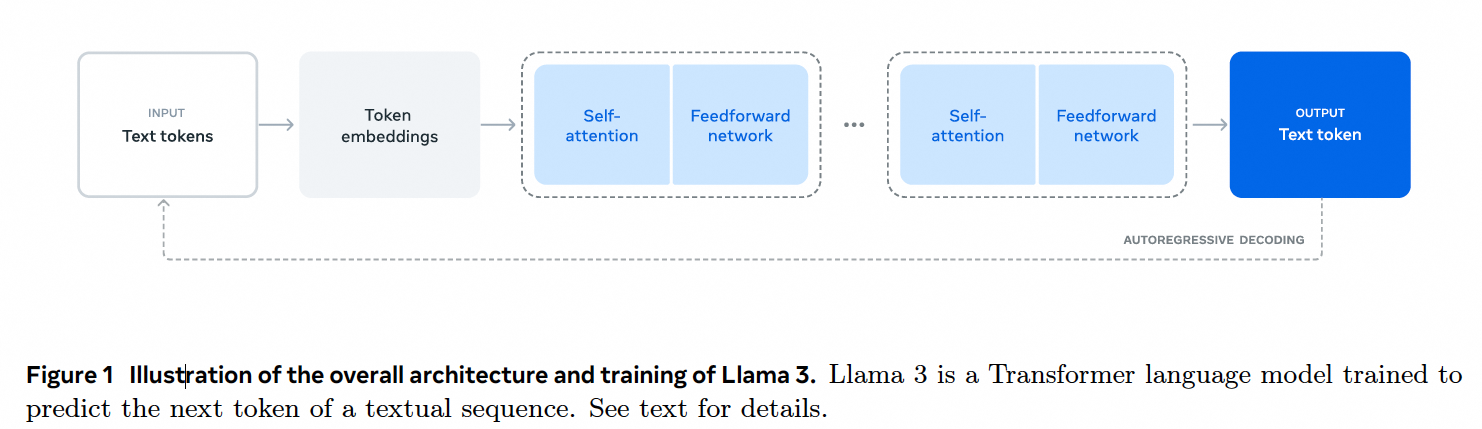
- pre-training。模型学习语言结构和大量知识。8K tokens窗口在15.6T上训练405B。后面8K增大到128K。
- post-training。多轮SFT和DPO。让模型跟随指令和成为期望的助手。
以上模型能有丰富的功能,回答问题,写代码,推理,使用工具。
另外使用组合方法添加了图像、视频和语音功能。研究了三个额外的阶段: - Multi-modal encoder pre-training(多模态编码器预训练).为图像和语音训练单独的编码器。图像是以图像-文本对方式训练,是模型学习图像和文本描述间关系。语音则是自监督方法,屏蔽部分输入,重建被屏蔽部分(完形填空)。
- Vision adapter training(视觉适配器训练).适配器是将预训练图像编码器集成到预训练的语言模型里面,主要有一系列cross-attention层组成。训练适配器时,会更新图像编码器,但不更新语言模型参数。还在图像适配器上使用视频-文本数据训练视频适配器,使模型能够跨帧聚合。
- Speech adapter training(语音适配器训练)。通过适配器将语音编码器集成到进来,适配器和编码器联合更新,但不更新语言模型。
![]()

Pre-Training
包含大规模训练语料管理和过滤、模型结构和大小、模型高效训练、训练方案。
预训练数据
收集截止2023年底,应用去重和清理机制,删除包含个人信息和成人内容。
网络数据
清洗过程:
- PII(personally identifiable information)和安全过滤。
- 文本提前和清洗。
- 重复数据清洗。包含URL-level de-duplication,Document-level de-duplication(使用global minHASH),Line-level de-duplication(ccNet).
启发式过滤Heuristic filtering
删除低质量文档、异常值和重复文档。 - 使用n-gram coverage ratio删除重复行。
- dirty word 统计过滤成人网站。
- 使用token分布的Kullback-Leibler divergence,过滤分布包含异常标识的文档。
Model-based quality filtering模型指令过滤
代码和推理数据
多语言数据
数据混合比例
为了获得高质量的语言模型,需要仔细确定不同数据源的比例。
- Knowledge classification.开发一个分类器对数据分类,过多的要进行下采样。
- Scaling laws for data mix. 在混合数据上训练小模型进行实验,最终确定下来50%常识,25%数学和推理,17%编码,8%多语言。
退火数据
模型结构
与Llama2相比改动:
- GQA(grouped query attention)with 8 key-value heads。提高推理速度和减少缓存。
- 128K字典。
- RoFE 频率参数提高到50万,支持长上下文。
Scaling Laws缩放法则
高效训练
16K H100 GPU
4D并行包含tensor并行,pipeline并行,context并行,数据并行。
可靠性和运营
每天至少一次训练中断
训练方案
预训练分为三个阶段,1初始化预训练。2.长上下文预训练。3.退火。
初始化预训练
AdamW
base_lr 8x10-5
a linear warm up of 8,000 steps
a cosine learning rate schedule decaying to 8x10-7 over 1,200,000 steps
早期小batchsize提高稳定性,后面改用大batch提高效率
长上下文预训练
8K到128K 分为六个阶段逐步进行
退火
后40M数据训练时,lr线性减到0,并对高质量数据上采样
Post-Training
modeling
先用前面预训练好的checkpoint和偏好数据训练reward model
再SFT预训练好模型
DPO做进一步调整
聊天对话格式
奖励模型
SFT
DPO
对比PPO发现,DPO需要的计算更少且性能更好
模型平均Model Averaging
最后,对每个RM、SFT或者DPO模型平均。
迭代轮次Iterative Rounds
上述进行6轮,每轮都从新模型中采样合成的数据。
后处理数据Post-training Data
偏好数据
SFT数据
Data Processing and Quality Control
使用基于模型的技术来删除低质量训练样本
- 主题分类,粗和细
- 质量评分
- 难度评分
- 重复语义删除。RoBERT聚类。
Capabilities能力
代码,多语言,数据推理,长上下文,工具使用,事实性Factuality,操纵性
- 代码。通过培训代码专家(a code expert),生成合成SFT数据,通过系统提示改进格式和创建过滤器来删除不良样本。
- 多语言。
- 推理。推理是执行多步步骤计算并得到正确答案的能力。
- 长上下文。SFT中必须调整方案(recipe)去平衡短和长上下文能力。人类标注很困难,主要依靠合成数据。最终观察到长上下文0.1%和原始短上下文数据混合可以优惠短、长上下文性能。
- 工具使用。单步工具()和多步工具(ReAct)。
- 事实性。训练后让模型知道它知道什么。开发了一种知识探索技术(a knowledge probing technique)。
- 操作性。相应长度,格式,语气和角色/个性等。
结果
评估预训练模型和后训练模型以及安全性。
预训练模型
基准(Standard Benchmarks)
评估类别:1.常识推理。2知识。3.阅读理解。4.数据、推理和问题解决。5.长上下文。6.代码。7.对抗评价。8.综合评价。

模型鲁棒性
对抗性基准
污染性分析(Contamination Analysis)
后训练模型
常识和指令跟随基准(General Knowledge and Instruction-Following Benchmarks)
MMLU和MMLU-Pro
IFEval
能力考试
编码基准
使用pass@N指标
HumanEval,MBPP
多语言基准
数据和推理基准
长上下文基准
工具使用表现
评测集
人类评价,使用人工评估来测试模型的工具使用能力,重点是代码执行。
人类评估
人工打分
安全性
评估llama3以安全和负责人方式生成内容的能力,同时最大限度提供有用信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号