BEV detection(自底向上)小结
LLS
https://zhuanlan.zhihu.com/p/589146284
BEVDet
提出一种优雅可行可扩展的范式,包含4个部分:image-view encoder, view transformer from image view to BEV, bev encoder, head.
pipeline
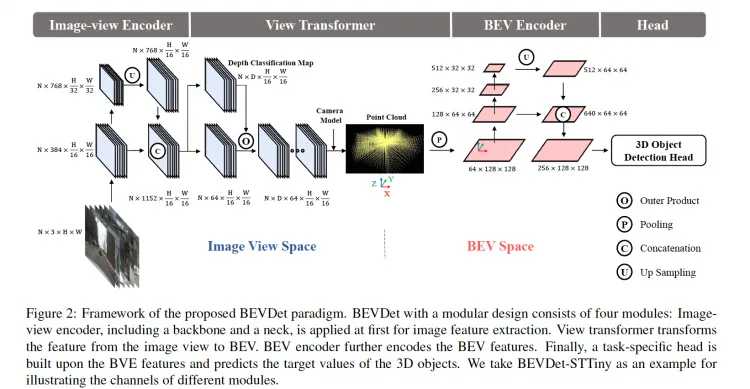
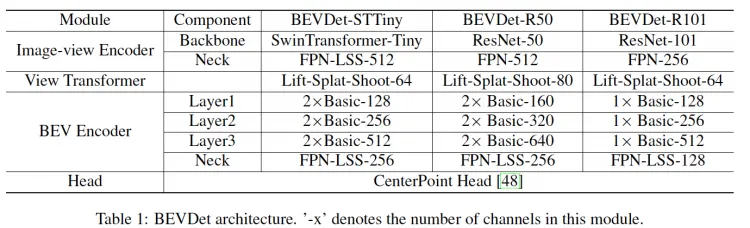
module
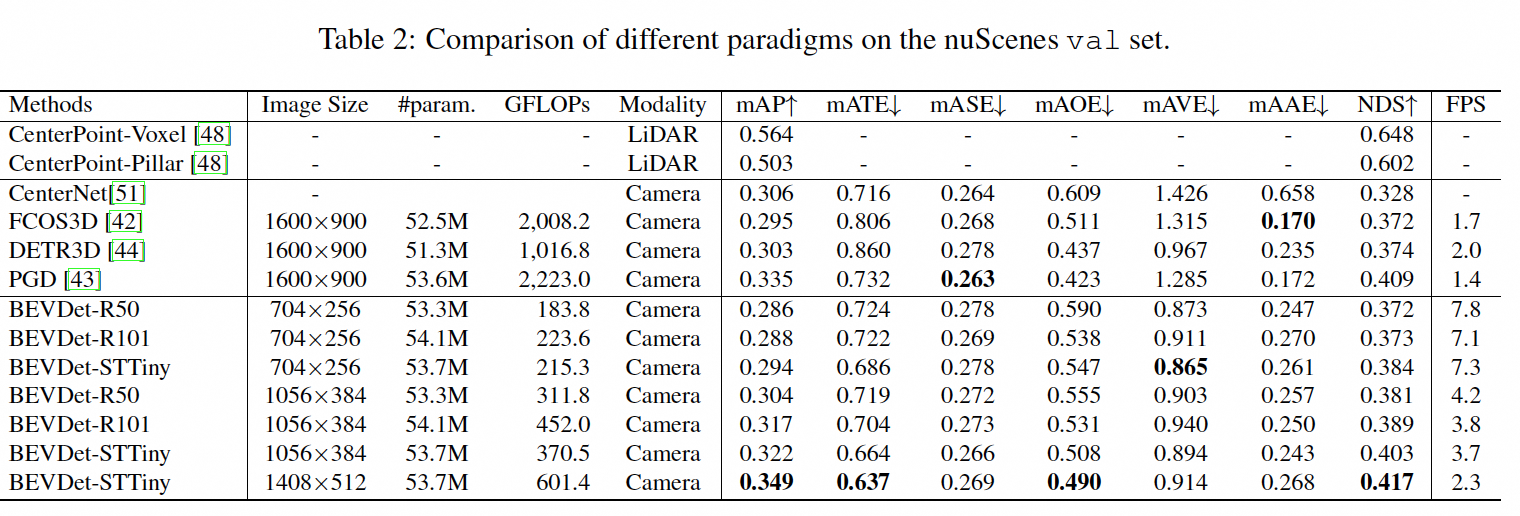
Augmentation
防止过拟合,不光对图片做增强,还对bev feature做flipping, scaling, rotating(同时作用view transformer 和 3d targets)。
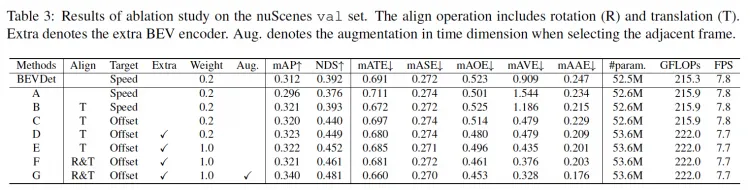
ablation
IDA 图像增强
BDA bev特征增强
BE BEV encoder

BEVDet4D
bevdet4d 将bevdet从只有空间信息的3d工作空间提高到时空的4d工作空间。
pipeline
以bevdet为基础进行扩展,将前一帧特征和当前帧特征进行融合,融合前需要进行时空对齐和concate
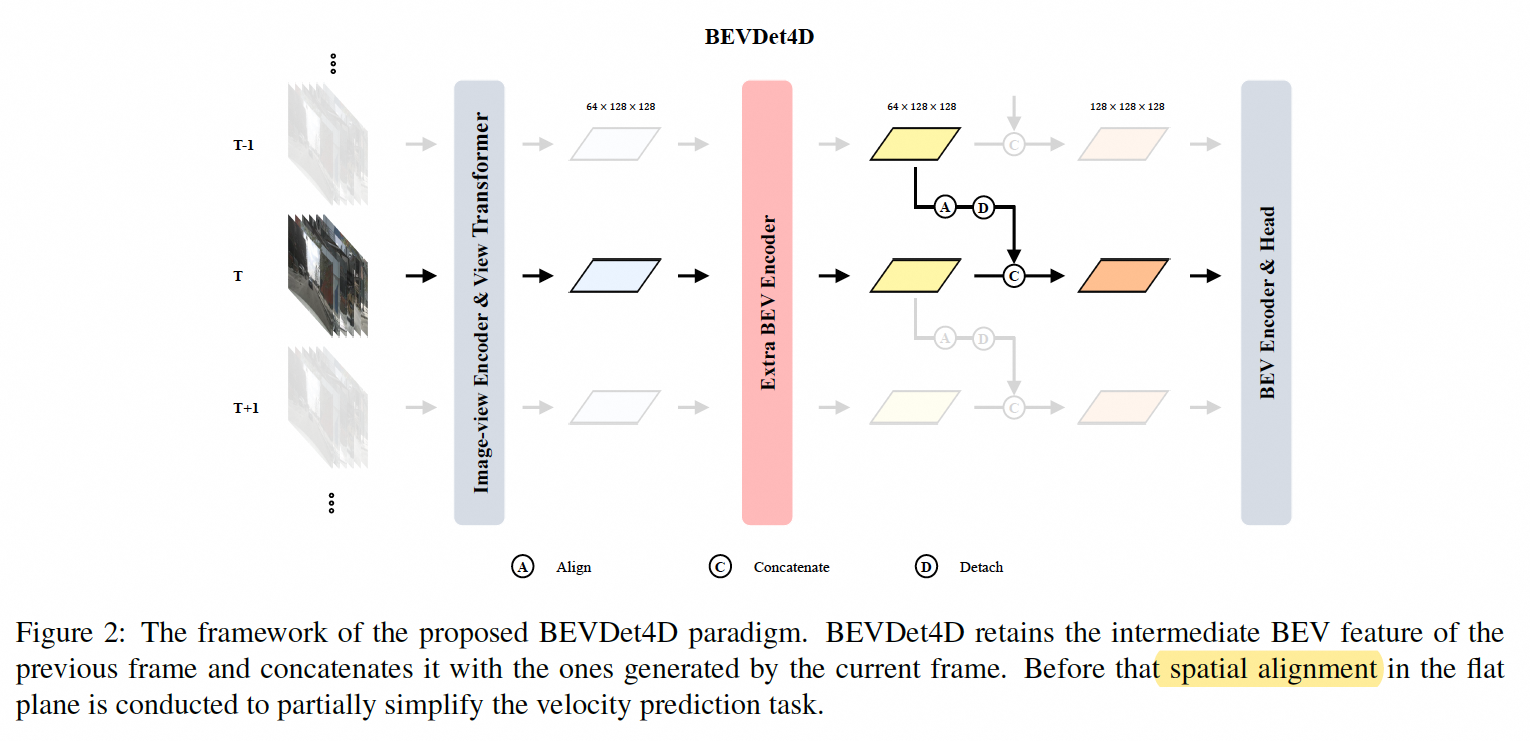
spatial alignmnet
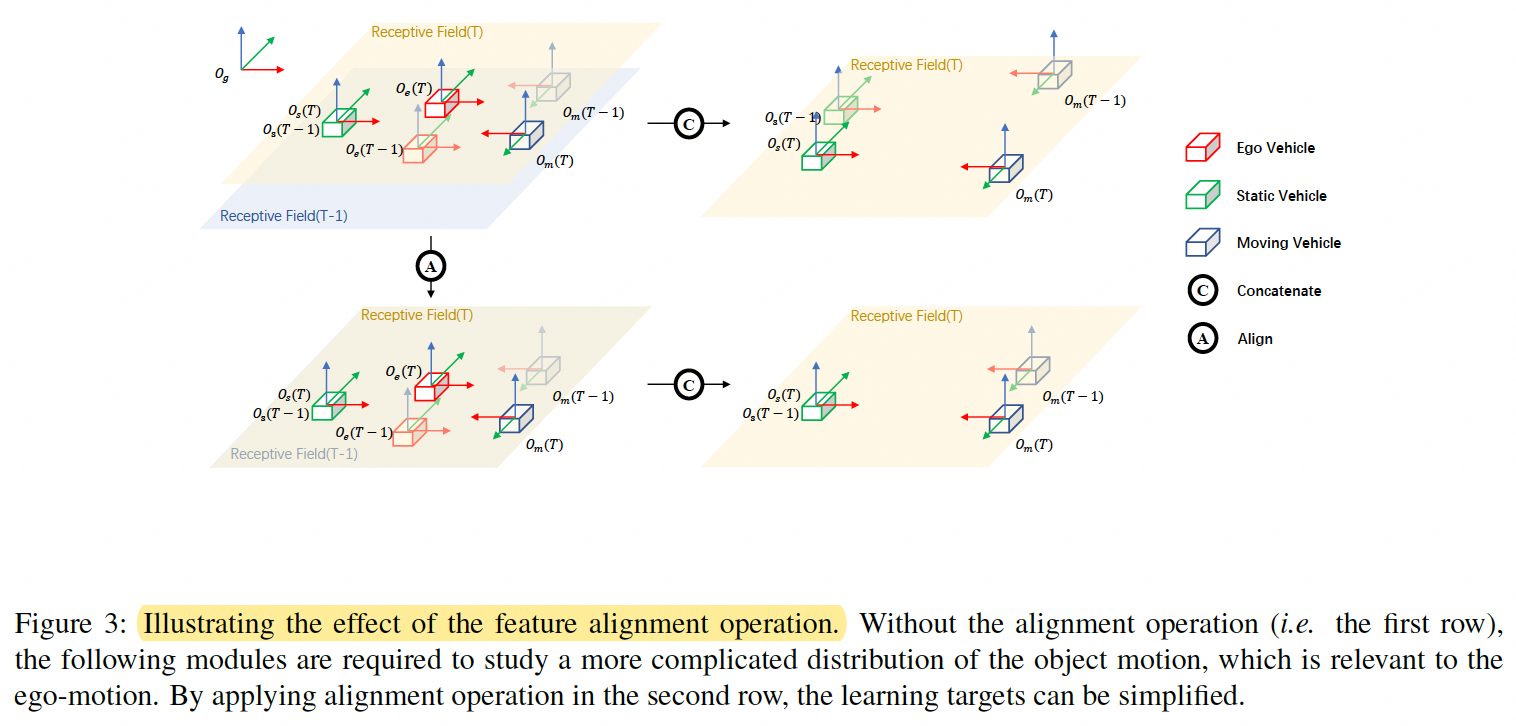
ablation
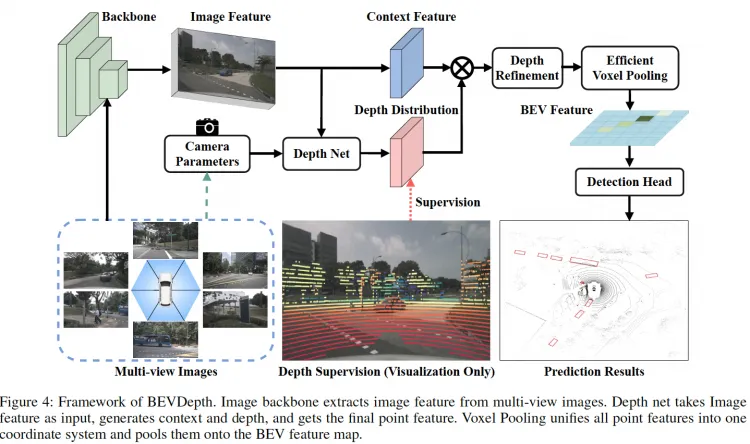
BEVDepth
https://zhuanlan.zhihu.com/p/547509776
module
1.Explicit Depth Supervision。显式深度监督。利用点云做监督训练深度预测模块。
2.Camera-aware Depth Prediction。相机级别深度预测。考虑不同相机可能fov不同,将相机的内参和外参加入网络。
将内参MLP操作后,类似SE机制加入网络,起到reweight的作用。
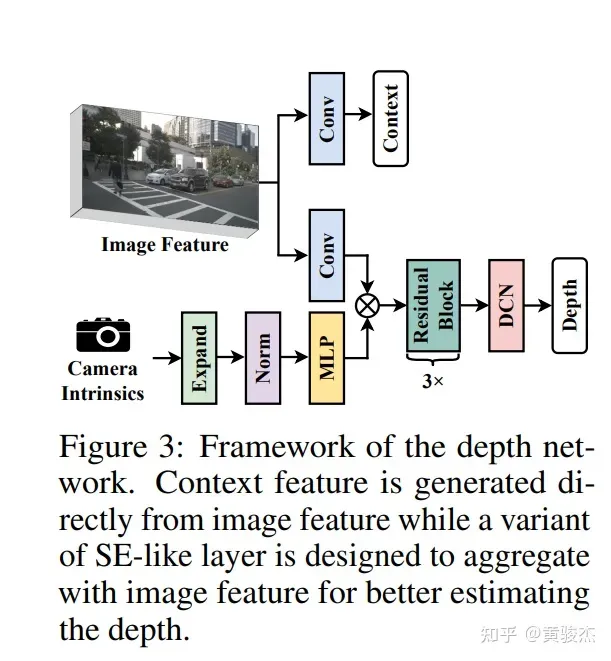
3.Depth Refinement Module。
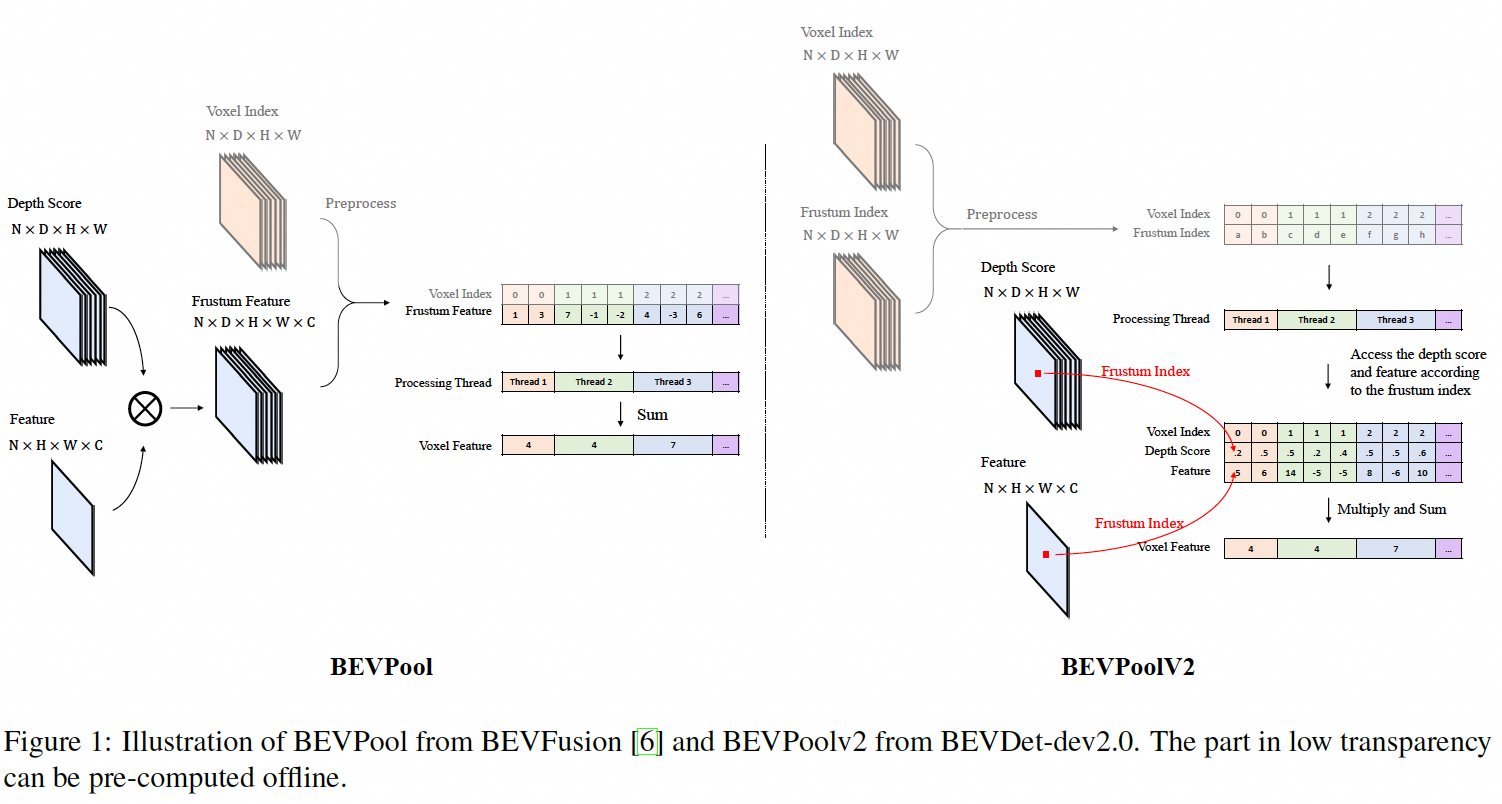
BEVPoolV2
在工程上优化view transformer 视锥特征
BEVFusion
https://www.bilibili.com/video/BV1ix4y1f7mX/?vd_source=ce2a79a81ce4664d23986d5dd13fe96e
有两篇北大阿里和MIT(https://zhuanlan.zhihu.com/p/654781992 https://github.com/mit-han-lab/bevfusion)
大差不差MITstar最多

 浙公网安备 33010602011771号
浙公网安备 33010602011771号