python的多线程 ThreadPoolExecutor
from concurrent.futures import ThreadPoolExecutor,wait
import time
executor = ThreadPoolExecutor(max_workers = 2)
# 线程要执行的函数
def func(i):
time.sleep(0.5)
print(i)
if i%2 == 1:
return '奇数'
else:
return '偶数'
# 把线程加入线程字典
thread_list = [executor.submit(func, i) for i in range(5)]
# 取得线程执行结果 如果用result取结果,不用wait也会等所有线程执行完,如果没有使用到线程例如result()取结果,done()查看子线程是否已经执行完,那么不会等子线程执行完,如果要等子线程执行完,就要用wait
for thread in thread_list:
print("线程名:",thread)
print('thread.result()= :',thread.result())
# wait的功能:等待所有线程执行完
# print(wait(thread_list))
print('所有线程执行完 end......')
执行结果:

from concurrent.futures import ThreadPoolExecutor,wait import time executor = ThreadPoolExecutor(max_workers = 2) # 线程要执行的函数 def func(i): time.sleep(0.5) if i%2 == 1:return {'status':1,'msg':'奇数'} else:return {'status':0,'msg':'偶数'} # 用 map函数 更精简的取所有子线程执行结果: for thread_exec_res in executor.map(func,list(range(10))): print('子线程执行结果',thread_exec_res)
执行结果:
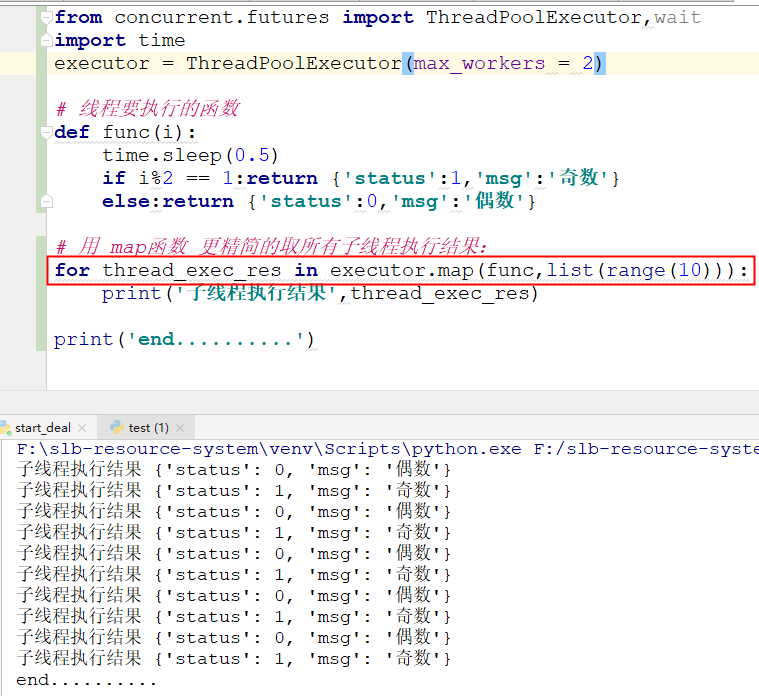
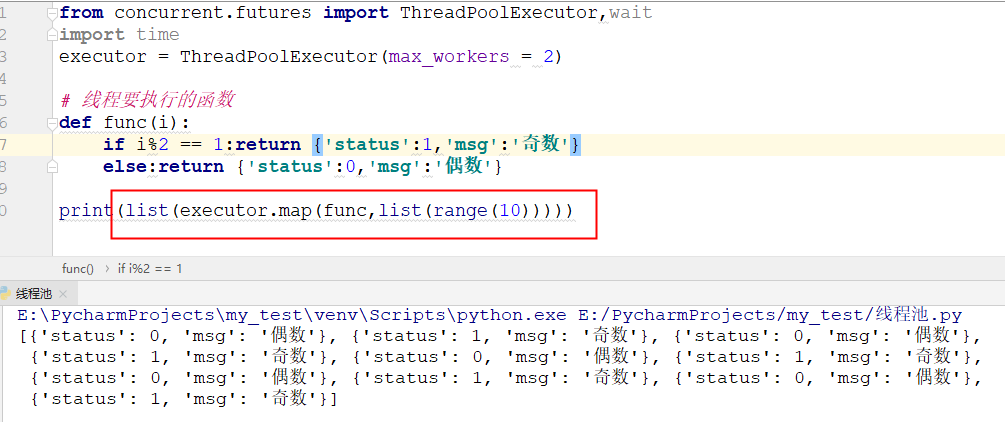
list(map(......))将所有线程执行结果放在列表中:
print(list(executor.map(func,list(range(10)))))
↓↓
![]()
设置超时时间:
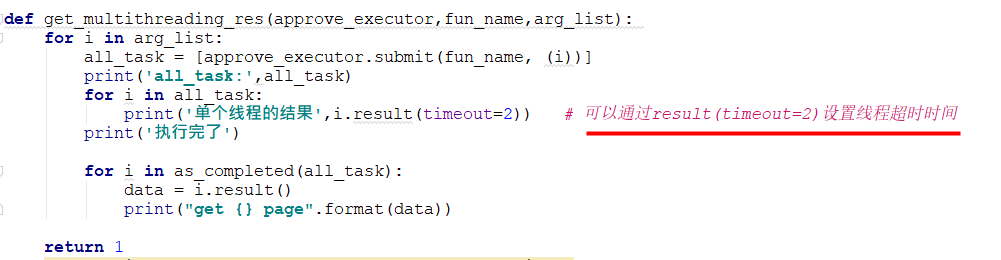
def get_multithreading_res(approve_executor,fun_name,arg_list): for i in arg_list: all_task = [approve_executor.submit(fun_name, (i))] print('all_task:',all_task) for i in all_task: print('单个线程的结果',i.result(timeout=2)) # 可以通过result(timeout=2)设置线程超时时间 print('执行完了')
第二种方法设置超时时间:
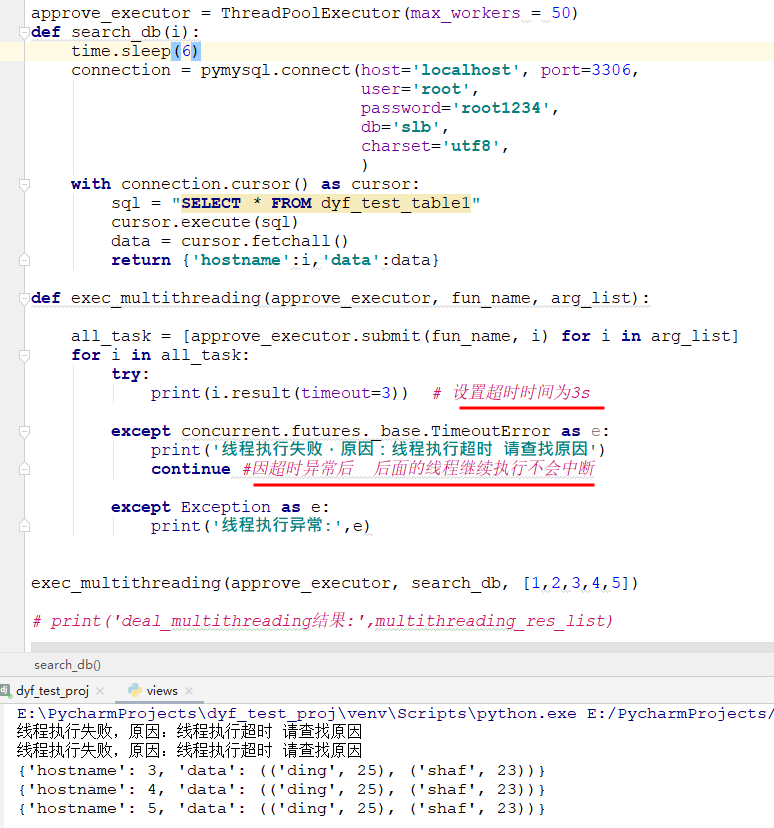
approve_executor = ThreadPoolExecutor(max_workers = 50) def search_db(i): time.sleep(6) connection = pymysql.connect(host='localhost', port=3306, user='root', password='root1234', db='slb', charset='utf8', ) with connection.cursor() as cursor: sql = "SELECT * FROM dyf_test_table1" cursor.execute(sql) data = cursor.fetchall() return {'hostname':i,'data':data} def exec_multithreading(approve_executor, fun_name, arg_list): all_task = [approve_executor.submit(fun_name, i) for i in arg_list] for i in all_task: try: print(i.result(timeout=3)) # 设置超时时间为3s except concurrent.futures._base.TimeoutError as e: print('线程执行失败,原因:线程执行超时 请查找原因') continue #因超时异常后 后面的线程继续执行不会中断 except Exception as e: print('线程执行异常:',e) exec_multithreading(approve_executor, search_db, [1,2,3,4,5])

 浙公网安备 33010602011771号
浙公网安备 33010602011771号