

03 2025 档案
摘要:对于文本标注问题,如果不适用BERT,而是使用一般神经网络,那么应该长成下面这个样子 复习一下典型的神经网络反向传播的过程中求导的步骤 那个小圆圈是哈达姆积,想一下为什么可以这么转换 然后来看一下
摘要:这里还要用pandas读取数据集,是因为这里是结构化数据,无论是统计学习还是深度学习,结构化数据使用pandas读入肯定是好的,下面两个概念(结构化数据和非结构化数据)就可以记一下了
阅读全文
摘要:看下这个答案是怎么计算出来的 # shape不一样且大小不匹配的位置任意有一个张量为1 a = torch.arange(3).reshape((1,3,1)) b = torch.arange(9).reshape((3,1,3)) a, b, a+b 我们一维一维拓展 对a: 维度2: a[0]
阅读全文
摘要:上一课讲了词嵌入实际上是把单词嵌入到高维空间中,然而我们展示的时候只能通过降维在二维平面中展示,如下 但是实际上高维空间中的接近与二维平面中的接近不同,高维空间中的接近可以从多个维度进行接近,所以高维向量可以同时接近多个向量 现在一般的做法是训练嵌入向量,那么可不可以直接采用计数的方法呢?也就是如下
阅读全文
摘要:下面这一段代码直接沾到Pycharm里面去运行的话是不能运行成功的,这是因为我们不知道执行什么,应该加上我们要执行的东西,这样子代码就知道执行什么东西了(在这里就是执行我们定义的方法hello_world),如下 有了app.run()之后就知道运行什么了 我们在命令行中输入下面的命令(说到命令行,
阅读全文
摘要:对于文字的意义,语言学家有很多种定义。其中一种定义运用在自然语言处理中非常有用,这种意义的定义见下 分布式语义就是看上下文词来决定单词的意义。于是我们可以利用词向量来衡量两个词之间的相似程度,词的意义被分散在词向量的每一维中 词嵌入之所以叫词嵌入,是因为我们给每个单词分配一个向量的做法就是将每个单词
阅读全文
摘要:在PyTorch中,当设置nn.LSTM的bidirectional参数为True时,输出包含以下三个部分: 1. 输出张量(output) 形状:(seq_len, batch, num_directions * hidden_size) seq_len:序列长度。 batch:批量大小。 num
阅读全文
摘要:在层序softmax中,不是只有叶子节点才代表一个词元吗?那么为什么计算条件概率的时候要去看非叶子节点?非叶子节点代表什么?为什么非叶子节点有词向量?对此,deepseek的解释如下 在层序Softmax(Hierarchical Softmax)中,非叶子节点虽然不直接代表词元,但它们通过构建二叉
阅读全文
摘要:现在考虑BERT的输入。一般来说NLP里面的输入都是成对的,比如机器翻译,有一个源句子还有一个目标句子。那么这里如何让输入是两个句子呢?我们只用拼接起来就好了,如下 <cls>表示classification,sep表示句子分隔符(separation);Segment Embeddings就是用来
阅读全文
摘要:BERT的任务是构建一个通用的模型,那么在NLP里面,语言模型(看一些词,预测下一个词)显然是最通用的,所以我们将BERT训练成一个语言模型,即带掩码的语言模型。但是Transformer是双向的,而语言模型是单向的,这显然就不能直接训练,于是这就是我们带掩码的原因。<mask>就是我们要填写的词,
阅读全文
摘要:在我们已经训练好BERT后,BERT就可以对输入的每一个词元返回抽取了上下文信息的特征向量(也就是对于任意一个词元,将这个词元当做查询,所有词元当做键值对) 一些任务如下 这里将<cls>的特征向量传递给全连接层的原因就是因为<cls>本来就是用来分类的,所以肯定传这个。当然也可以传其他的,反正我们
阅读全文
摘要:想想吴恩达讲的CV里面,复用其他网络的结构,只在最后一层加入一个全连接层,对这个全连接层进行微调,也就是如下过程 那么CV里面可以这么用,NLP里面当然也可以这么用,如下 我们只需要调整这个新增加的简单输出层即可 BERT说白了,就是只有编码器的Transformer 他有两个版本,见下 block
阅读全文
摘要: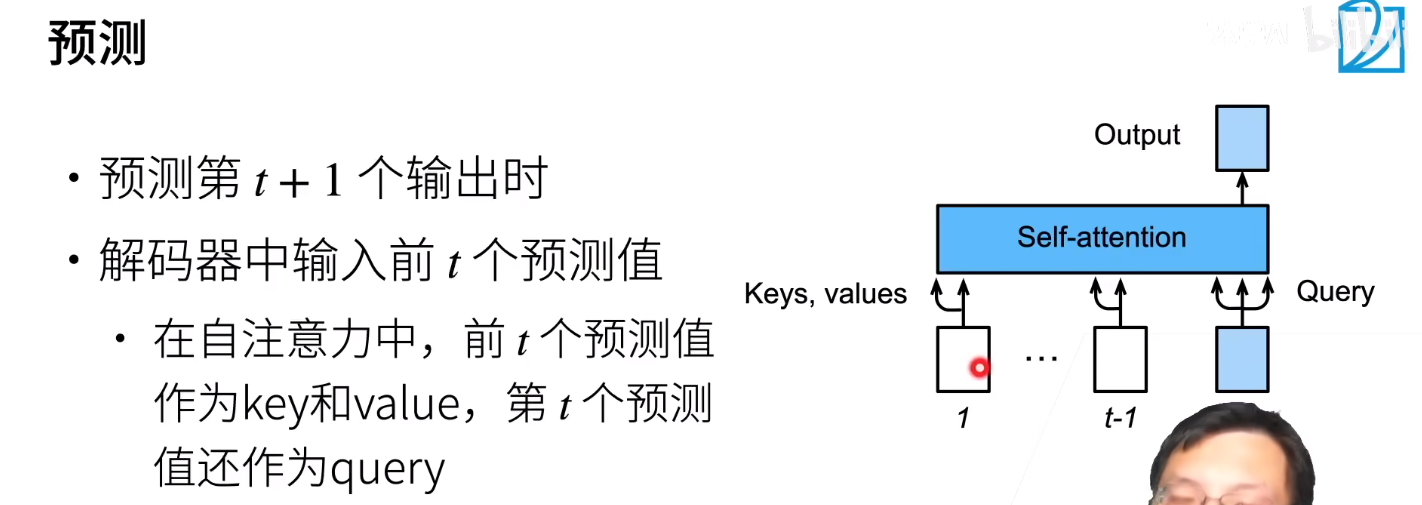
阅读全文
摘要:注意,我们这里必须要将输入的前两维(batch_size和num_steps)结合起来,而不能将后两维(num_steps和dimension)结合起来,因为这里num_steps是变化的(num_steps是我们指定的超参数,指定之后编码器-解码器的确只能处理固定长度的序列,因为有truncate
阅读全文
摘要:CNN怎么做序列?实际上之前已经接触过了,就是把序列当成没有高只有宽的图片而已 将书上讲的复杂度汇总如下 CNN 计算复杂度:进行一次卷积计算,由于卷积层大小为
摘要:作业题目:请设计一份问卷,分别针对软件工程师和高年级同学,调查他们在设计、开发软件系统时通常会面临的困难和困惑,并调研其解决问题的途径和方法。 目录软件工程师版问卷一、基本信息二.设计痛点三、开发痛点四、解决方案高年级学生版问卷一、基本信息二.设计痛点三、开发痛点四、解决方案 软件工程师版问卷 一、
阅读全文
摘要:最后一段话各个句子的意思: ELMo将来自预训练的双向长短期记忆网络的所有中间层表示组合为输出表示:ELMo(Embeddings from Language Models)通过双向长短期记忆网络(BiLSTM)生成上下文敏感的词表示,其核心思想是结合双向LSTM所有层的中间表示,形成动态的词向量。
阅读全文
摘要:最后一段最后一句话的含义及示例说明: 核心问题:交叉熵损失在处理大型语料库中的罕见共现事件时,会赋予它们过高的权重,导致模型过度关注这些不常见的情况,从而影响整体性能。 具体解释 在跳元模型中,损失函数为: \[-\sum_{i \in V} \sum_{j \in V} x_{ij} \log q
阅读全文
摘要:HTTP 请求中的 PUT 和 POST 方法均可用于向服务器提交数据,但它们在语义、用途和幂等性上有本质区别。以下是两者的关键差异: 1. 语义与用途 PUT 作用:用于完整替换服务器上某个已知 URI 对应的资源。 场景:客户端明确知道目标资源的 URI(例如 /users/123),并希望将数
阅读全文
摘要:跳元模型的似然函数选择为:
摘要:' '.join(list(token))是将token中的每个元素用空格给连接起来。比如' '.join(['f', 'a', 's', 't', '_']) → 'f a s t _' split()函数的默认行为是按照任意空白字符(包括空格、制表符、换行符等)进行分割,并且会自动处理连续的空格
阅读全文
摘要:
阅读全文
摘要:首先来看看二元交叉熵的损失公式 然后再来看看nn.functional.binary_cross_entropy_with_logits的用法 然后来讲一下
摘要:一些本人的理解如下: 事件
