14.8.5 预训练任务
BERT的任务是构建一个通用的模型,那么在NLP里面,语言模型(看一些词,预测下一个词)显然是最通用的,所以我们将BERT训练成一个语言模型,即带掩码的语言模型。但是Transformer是双向的,而语言模型是单向的,这显然就不能直接训练,于是这就是我们带掩码的原因。<mask>就是我们要填写的词,相当于完形填空,此时就不是预测未来了,所以看双向信息是没问题的
那么书上的<mask>那一段到底是为什么要这么换呢?
在BERT的掩蔽语言模型训练中,“要预测一个掩蔽词元而不使用标签作弊”指的是:
如果直接将被掩盖的词元保留在输入中(例如,输入是原句“this movie is great”,而标签是“great”),模型可能会直接“偷看”输入中的原词元来预测,而非真正学习上下文关系。这种依赖输入中的原始词元信息的行为称为“标签作弊”。
为了避免这种情况,BERT采用以下方法:
- 始终用“<mask>”替换被掩盖的词元(如将“great”替换为“this movie is <mask>”)。
- 此时,输入中不再包含被掩盖词元的原始信息,迫使模型必须通过双向上下文(如“this movie is”和周围词元)来推断被掩盖的词元。
但为了避免模型过度依赖“<mask>”标记(因为实际下游任务中不会有“<mask>”),BERT进一步引入:
- 80%时间用“<mask>”
- 10%时间用随机词元(如“this movie is drink”)
- 10%时间保留原词元(如“this movie is great”)
这种策略既防止了标签作弊(通过掩盖原词元),又通过随机噪声增强了模型的鲁棒性,使其更专注于上下文推理而非标记本身。
在BERT的掩蔽语言模型训练中,“过度依赖<mask>标记” 指模型在训练过程中可能形成以下依赖模式:
- 仅在有<mask>标记时进行预测:若训练时所有被掩盖的词元都被替换为<mask>(如“this movie is <mask>”),模型可能仅在输入中存在<mask>时激活预测能力,而忽略上下文的全局推理。也就是模型可能只有在看到
<mask>标记的时候才努力预测,剩下的情况就水一水 - 无法泛化到真实场景:实际下游任务(如文本分类、问答)中,输入文本不会包含<mask>标记。若模型仅通过<mask>触发预测逻辑,在无<mask>的输入中将难以有效推理。
为何需要避免这种依赖?
BERT通过以下策略打破模型对<mask>的机械性依赖:
- 80%时间使用<mask>:确保模型主要学习通过上下文推断被掩盖的词元。
- 10%时间替换为随机词元(如“this movie is drink”):
- 迫使模型区分错误词元(如“drink”与上下文不匹配),强化上下文理解。
- 10%时间保留原词元(如“this movie is great”):
- 防止模型因完全看不到原词元而过度拟合<mask>模式,同时让模型学会“不总是需要修改输入”。
核心目标
通过引入随机性和保留原词元,模型被强制关注全局上下文,而非仅依赖<mask>标记的存在。这种设计使BERT在预训练后能灵活适应各类下游任务(即使没有<mask>),真正实现“通过上下文理解语义”的能力。
注意,在BERT引入的三种方法中,无论是哪种方法,模型始终都知道要预测的词的位置(比如上文举的例子的三种情况,模型知道预测的词分别是<mask>,drink和great)
掩蔽语言模型有一个小拓展,叫Span Corruption.简单来说,就是MLM只会遮一个词,但是Span Corruption会连续遮一段。BERT当然可以使用Span Corruption来进行预训练,也就是SpanBERT
那么在掩蔽语言模型中,模型到底学会了什么?这个其实就从表面上看就行了
- 语义
比如让模型预测Stanford University is located in ___ California.,模型就可以学会斯坦福大学的位置
比如让模型预测I went to the ocean to see the fish, turtles, seals, and ___,模型就可以学会各种海洋生物
比如让模型预测The woman walked across the street, checking for traffic over ___ shoulder.就可以学会shoulder属于谁,而且在填入her之后模型还可以知道The woman就是her,her就是The woman - 语法
比如让模型预测I put ___ fork down on the table.,模型就可以学会限定词语法 - 推理
比如让模型预测Overall, the value I got from the two hours watching it was the sum total of the popcorn and the drink. The movie was ___,就可以让模型进行情感分析
比如让模型预测Iroh went into the kitchen to make some tea. Standing next to Iroh, Zuko pondered his destiny. Zuko left the ___,就可以让模型知道这个世界的物理运行规则(就是不能瞬间移动,离开的只能是之前在的地方)
比如让模型预测I was thinking about the sequence that goes 1, 1, 2, 3, 5, 8, 13, 21, ___,就可以让模型学会找规律
那么除了语言模型,另一个预训练任务就是下一个句子预测

这两个数据一个是正例一个是负例
预训练任务除了书上讲的两个,实际上可以直接训练一个语言模型,这个样子更简单,而且依然不用标注,如下
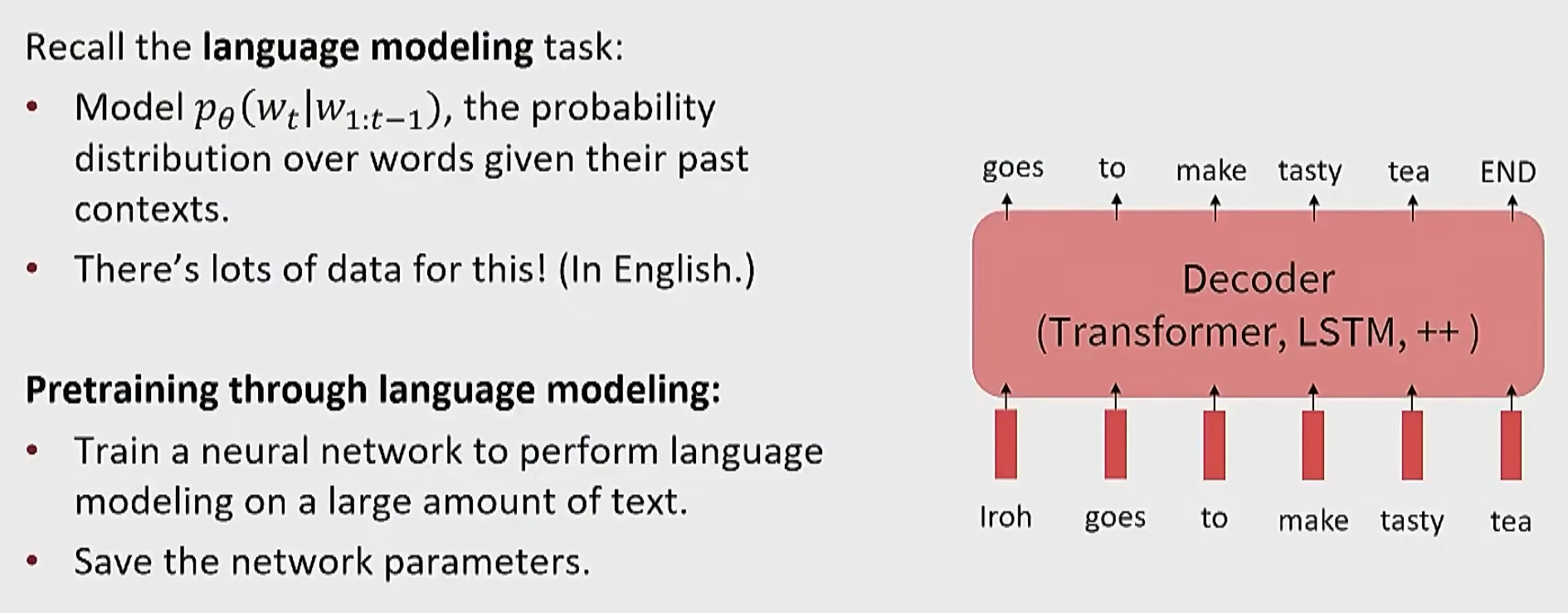
那么为什么采用预训练+微调的模式,而不是随机参数初始化+大量下游任务的训练数据?实际上,预训练的数据规模远远大于下游任务的训练数据,而且协变量偏移问题要少得多(因为前者是直接从整个互联网上面获得数据,而后者是人工标注的,这肯定没办法比)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号