7.5.1 训练深层网络
当网络很深的时候会出现下面的问题

梯度消失是一般情况,所以上面讨论的是梯度消失的情况(每一层的梯度都很小,很多个很小的数相乘就会导致底部的层梯度比上面的层的梯度小);梯度爆炸是另外一回事
之所以会导致上面这种情况是因为不同层之间数据分布是有差别的。所以一个简单的想法就是我给数据的分布固定住
之所以不直接使用均值为\(0\)方差为\(1\)的分布而是要再加\(\gamma\)和\(\beta\),是因为可能前者不是很适合(让网络自己学总是没错的);但这个样子又会导致一个问题,就是\(\gamma\)和\(\beta\)可以导致一个不同的分布,最后还是会导致不同层的分布不同,这怎么办?实际上我们限制两者的变化不要过于猛烈就好了
批量归一化的作用范围见下

上面两种方法是二选一;之所以要作用在激活函数之前,可以想一下如果我们作用在激活函数之后,\(\text{ReLu}\)把所有的值都变成正数之后,我们归一化又会把一些值重新变为负数就很奇怪(更严格的说,激活函数是非线性变化,而归一化是线性变化,线性变化肯定在非线性变换之前)
全连接层和卷积层不同的见下

卷积层那里,通道相当于特征
书上称样本均值和方差是噪音的原因就是我们每次是提取的小批量来进行计算的,小批量与总体分布肯定不同的,所以噪音是比较严重的(这也可能是批量规范化很有用的原因:通过在每个小批量中加入噪音来控制模型复杂度;而不是最初论文作者说的控制内部协变量偏移;所以没必要与丢弃法一起使用
归一化还有如下的知识点,看到时候整合一下
标准化的过程见下
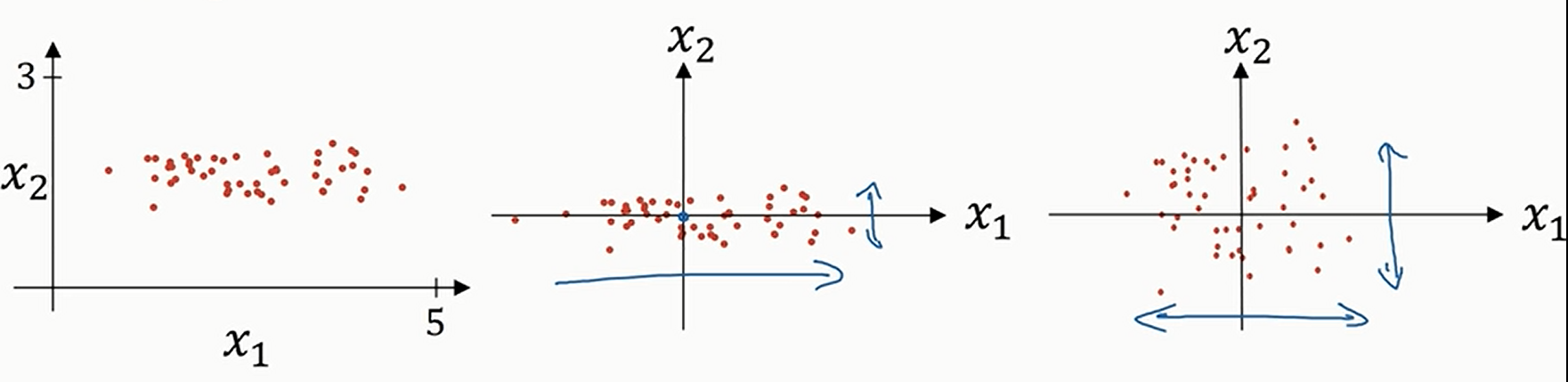
注意,标准化选取的均值\(\mu\)和标准差\(\sigma\)是按照训练集来选择的,但是我们也要对验证集和测试集进行标准化,我们不能(按照验证集或测试集)重新计算\(\mu\)和\(\sigma\),而是要用之前计算的训练集的\(\mu\)和\(\sigma\)进行标准化
进行标准化的原因:如果特征之间的数据范围相差很大(比如对于\(x_1∈\left[-1,1\right],x_2∈\left[-1000,1000\right]\)),那么损失函数就可能很扁,如下
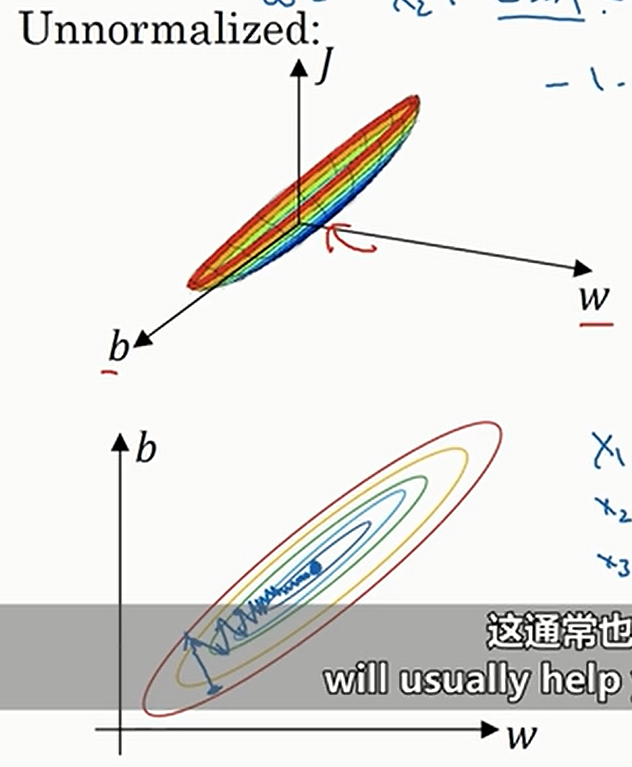
这个时候跑梯度下降的话,就有可能要多很多次才能到最小点,因为初始点的梯度方向不一定指向最小点
如果标准化了之后,损失函数就是圆的了,此时任何一个点的梯度方向都指向最小点,于是可以直接向最小点进行迭代,如下
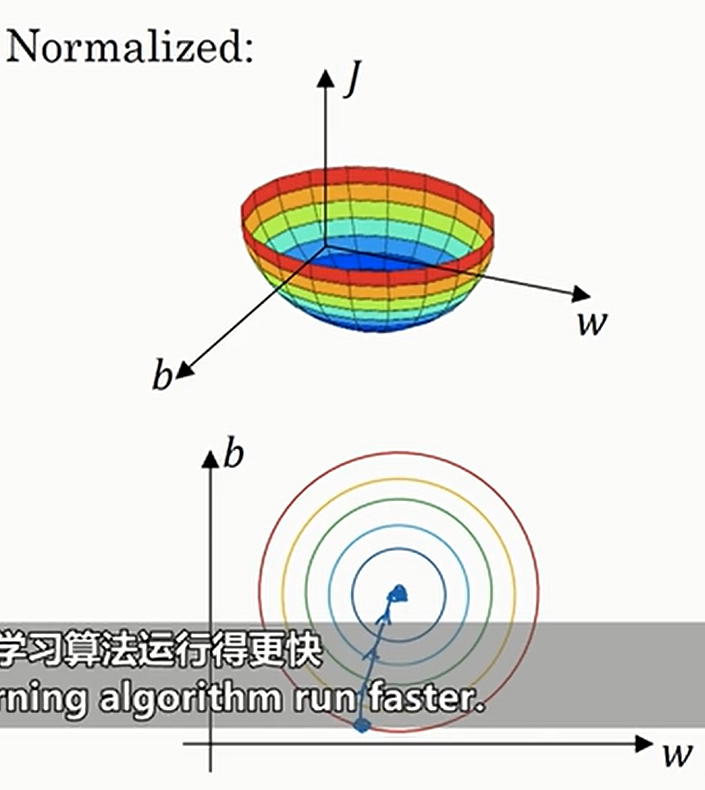
也就是说,如果数据之间的范围相差不大,那其实是否标准化不太重要;只不过一律标准化总是没问题的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号