

第三课 Rossman销售预测
加载数据
处理缺失数据
发现只有测试数据的Open有十一个空的(训练数据没有)。由于很少,我们直接将其找出,如下
cond = test['Open'].isnull()
test[cond]
输出结果如下
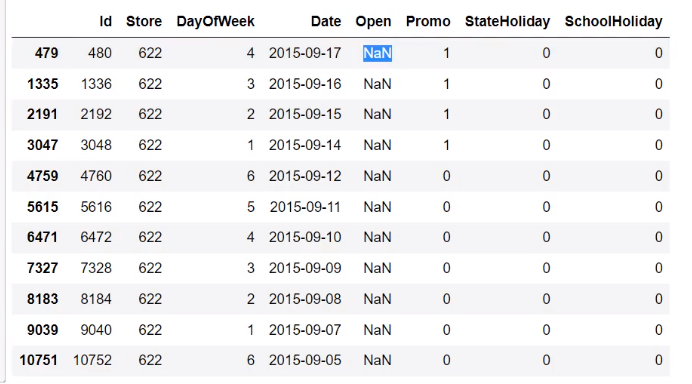
然后我们去找出训练数据中商店1
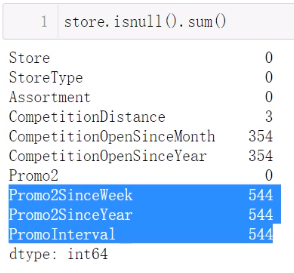
注意这道题目还多了一个数据,是商店的数据,于是还要处理这个数据,如下
进行变量命名方便后续处理
v1 = 'CompetitionDistance'
v2 = 'CompetitionOpenSinceMonth'
v3 = 'CompetitionOpenSinceYear'
v4 = 'Promo2SinceWeek'
v5 = 'Promo2SinceYear'
v6 = 'PromoInterval'
感觉v2和v3,v4,v5和v6是同时缺失的,我们可以用如下代码查看一下

这验证了我们的猜想。那么接下来就是如何填充这个缺失值。显然直接用中位数或者均值却填写有失偏颇,然后视频就用
划分训练集和验证集
之所以把这个单独作为一个标题,是因为这个视频的操作比较新。他先提取出销售额大于unique()即可),发现全部都是八九月份,然后从先前的关系发现六七月份跟八九月份的销售额很类似,所以划分验证集的时候选择六七月份的数据作为验证集
合并数据集
这里因为多了一个商店的数据,所以将这个数据合并到训练集和测试集中去,如下
cond = train['Sales'] > 0
train = train[cond] # 过滤了销售额小于0的数据
train = pd.merge(train, store, on='Store', how='left')
test = pd.merge(test, store, on='Store', how='left')
特征工程
创造特征(是否在促销活动期间),哑变量转换(下面的代码要先将字符串转换成数字,我觉得没必要可以直接哑变量转换)
for data in [train, test]:
# 修改时间
data['year'] = data['Date'].apply(lambda x: x.split('-')[0]).astype(int)
data['month'] = data['Date'].apply(lambda x: x.split('-')[1]).astype(int)
data['day'] = data['Date'].apply(lambda x: x.split('-')[2]).astype(int)
# 店铺有一个字段:PromoInterval,string类型,无法进行建模
# IsPromoMonth 是否进行了促销
month2str = {1: 'Jan', 2: 'Feb', 3: 'Mar', 4: 'Apr', 5: 'May', 6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep',
10: 'Oct', 11: 'Nov', 12: 'Dec'}
data['monthstr'] = data['month'].map(month2str)
# convert 是转换函数
convert = lambda x: 0 if x['PromoInterval'] == 0 else 1 if x['monthstr'] in x['PromoInterval'] else 0
# 这个月是否为促销月
data['IsPromoMonth'] = data.apply(convert, axis=1)
# 将存在字符串类型转换成数字:StoreType, Assortment, StateHoliday
mappings = {'0': 0, 'a': 1, 'b': 2, 'c': 3, 'd': 4}
data['StoreType'].replace(mappings, inplace=True)
data['Assortment'].replace(mappings, inplace=True)
data['StateHoliday'].replace(mappings, inplace=True)
然后删除一些特征,代码如下
display(train.shape,test.shape)
df_train = train.drop(['Date','monthstr','PromoInterval','Customers','Open'],axis = 1)
df_test = test.drop(['Date','monthstr','PromoInterval','Open','Id'],axis = 1)
display(df_train.shape,df_test.shape)
对训练集删除Customers这个特征的原因是测试集没有这个特征,所以我们建模的时候不能用这个特征
然后查看一下标签的分布,发现是正态分布但是有偏态,所以直接取对数即可
构建模型
定义损失函数
使用均方根百分比误差,定义如下
代码如下
def rmspe(y, yhat):
return np.sqrt(np.mean((1 - yhat/y)**2))
但是注意,这里我们对标签取了对数的(数据太小不利于梯度下降,速度太慢),所以要用下面的函数
def rmspe_xg(y, yhat): # 放大镜
y = np.expm1(y)
yhat = np.expm1(yhat.get_label()) # DMatrix数据类型,get_label获取数据
return 'rmspe', rmspe(y, yhat)
Kaggle上面很多回归问题最终的score是0.多少,就是用的上面的公式
模型训练
代码见下
params = {'objective':'reg:linear',
'booster':'gbtree',
'eta':0.03,
'max_depth':10,
'subsample':0.9,
'colsample_bytree':0.7,
'silent':1,
'seed':10}
num_boost_round = 6000
dtrain = xgb.DMatrix(X_train, y_train)
dtest = xgb.DMatrix(X_test, y_test) # 保留的验证数据
print('模型训练开始……')
evals = [(dtrain,'train'), (dtest,'validation')]
xgb.train(params, # 模型参数
dtrain, # 训练数据
num_boost_round, # 轮次,决策树的个数
evals=evals, # 验证,评估的数据
early_stopping_rounds=100,
feval=rmspe_xg, # 模型评估的函数
verbose_eval=True) # 打印输出log日志,每次训练详情
对feval的定义如下

输出如下

模型优化
这里是一个trick,不是调参,而是将预测值与真实值相比较,发现大部分预测值偏高,于是将预测值微调,即将预测值乘以一个


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2024-02-19 Sasha and the Wedding Binary Search Tree
2024-02-19 Sasha and the Casino
2024-02-19 Sasha and a Walk in the City
2024-02-19 CF思维题集合
2024-02-19 Sasha and the Drawing
2024-02-19 天气预报
2024-02-19 导弹防御系统