

2.1.5 节省内存
首先来介绍一下可变对象和不可变对象
- 可变对象:整数,浮点数,字符串,元组等
- 不可变对象:列表,字典,集合等
然后看一下Python中内存分配的方式
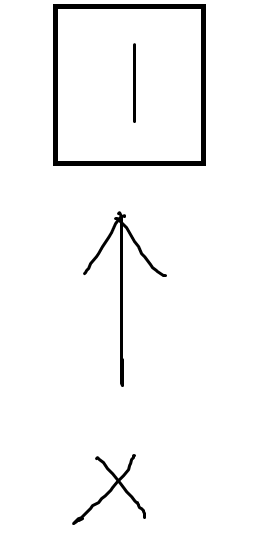
执行x=1会发生什么?此时,内存会分配一个地址给1,1是一个整型对象,而x是一个引用(不是对象!),指向1所在的位置,并不占用实际的内存空间,用图像表示如下
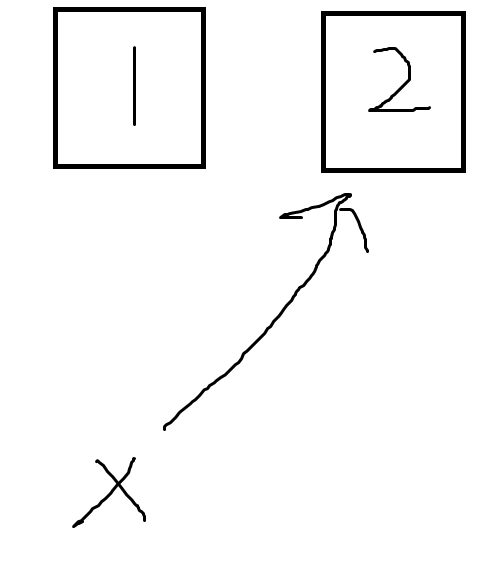
如果现在执行x=2会发生什么?由于1是不可变对象,所以1是没有动的,系统会给2分配一个内存,然后让x指向2,如下
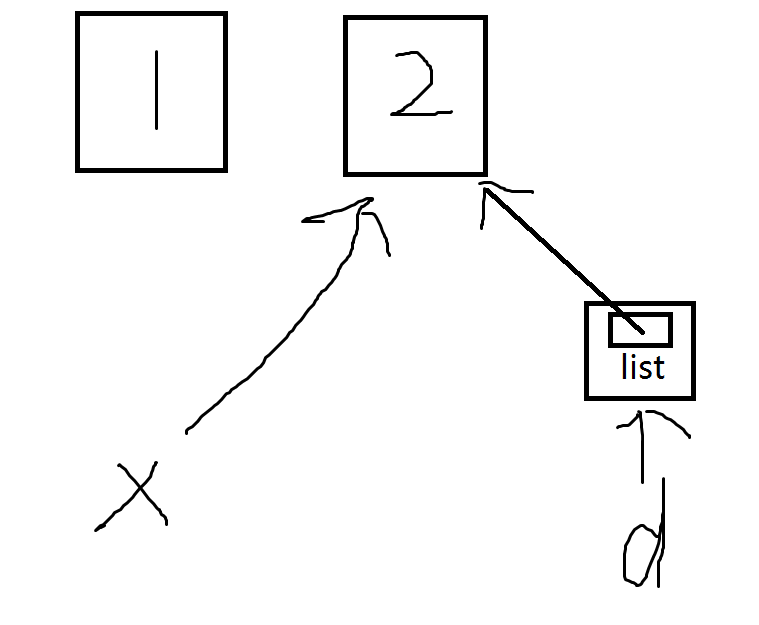
如果此时执行d=[x],那么示意图如下
所以此时x和d[0]的地址相同,但是x和d的地址不同(实际上x所指向的对象是一个整型,d所指向的对象是一个列表)
那么什么时候分配新的地址,什么时候不分配呢?
在 Python 中,是否分配新内存取决于对象的类型(可变性)和具体操作方式。以下是不同场景下的内存分配规则,尤其针对张量(如 NumPy 数组、PyTorch 张量)和其他常见数据结构:
1. 分配新内存的情况
(1) 运算符操作生成新对象
- 示例:
Y = X + Y # 会生成新的对象,Y 指向新内存 Z = X * 2 # 新对象,分配新内存 - 原因:运算符(如
+,-,*)会隐式调用对象的__add__、__mul__等方法,返回一个新对象。
(2) 不可变对象的修改
- 数据类型:字符串(
str)、元组(tuple)、整数(int)、浮点数(float)。 - 示例:
s = "hello" s += " world" # 新字符串对象,分配新内存;注意 += 本来是原地操作符,但是这里优先遵循字符串是不可变对象,所以必须分配新内存 t = (1, 2) t += (3,) # 新元组对象,分配新内存
(3) 显式调用构造函数或函数
- 示例:
import numpy as np a = np.array([1, 2]) b = np.array(a) # 显式复制,分配新内存 c = a.reshape((2, 1)) # 视图(不分配新内存) d = a.copy() # 显式复制,分配新内存
这里讲一下这个c = a.reshape((2, 1)),示意图如下

此时a和c的地址显然不同,但是a[0]和c[0][0]的地址相同。注意a和c只是引用,图中有外边框的才是对象
2. 不分配新内存的情况
(1) 原地操作(In-place Operations)
- 运算符:使用
+=、*=等原地运算符。 - 方法:调用对象的原地方法(如
list.append(),numpy.ndarray.__iadd__)。 - 示例:
# Python 列表 lst = [1, 2] lst += [3] # 原地修改,不分配新内存(等效于 list.extend) # NumPy 数组 a = np.array([1, 2]) a += 1 # 原地修改,不分配新内存 # PyTorch 张量 import torch y = torch.tensor([1, 2]) y.add_(x) # 原地操作(带下划线的函数),不分配新内存
(2) 视图(View)或切片
- NumPy/PyTorch:切片或某些操作返回原数据的视图(共享内存)。
- 示例:
a = np.array([[1, 2], [3, 4]]) b = a[0, :] # 视图,共享内存 c = a.T # 转置视图(不复制数据) # 修改视图会影响原数据 b[0] = 10 print(a) # 输出 [[10, 2], [3, 4]]
(3) 可变对象的直接修改
- 数据类型:列表(
list)、字典(dict)、集合(set)。 - 示例:
lst = [1, 2] lst.append(3) # 原地修改,不分配新内存 dct = {"a": 1} dct["b"] = 2 # 原地修改
3. 关键区别:运算符 vs. 原地方法
| 操作类型 | 示例 | 是否分配新内存 |
|---|---|---|
运算符(+, *) |
Y = X + Y |
✅ |
原地运算符(+=) |
Y += X |
❌(对可变对象) |
| 普通方法 | Y = Y.add(X) |
✅ |
| 原地方法(带下划线) | Y.add_(X) |
❌ |
下面的例子接最开始
此时如果执行d[0]+=1会怎么样?如下
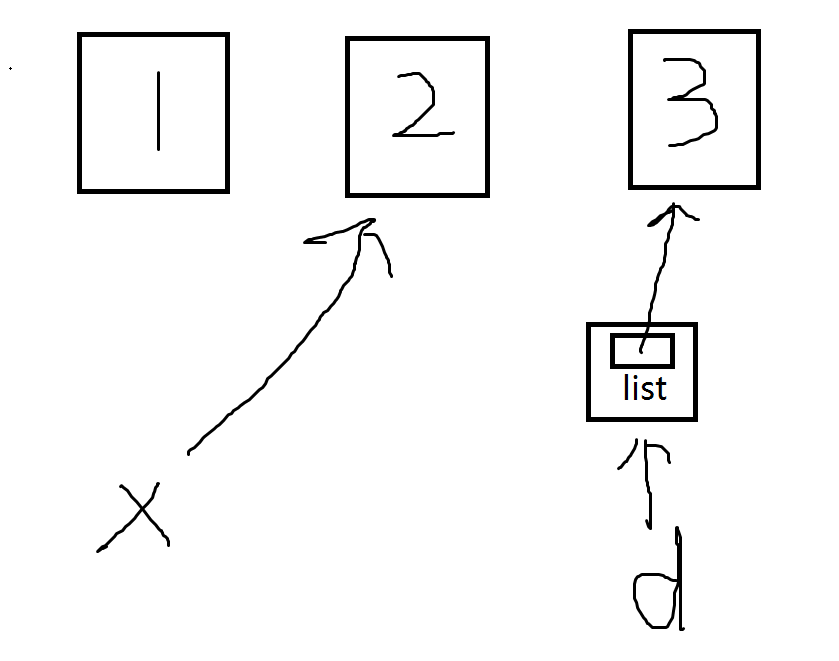
由于2是整型,是不可变对象,所以即使执行原地操作,仍然会分配新内存
现在假设kernel清空,并且执行x=np.array([1,2])后执行c=[x],那么示意图如下
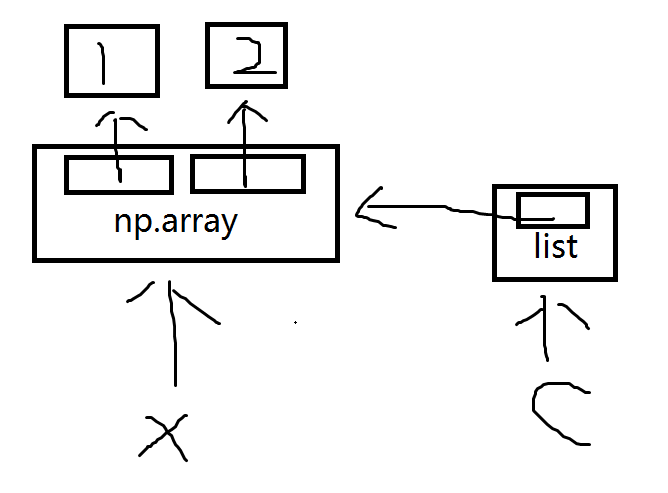
所以id(c)不等于id(x),但是id(c[0])等于id(x)
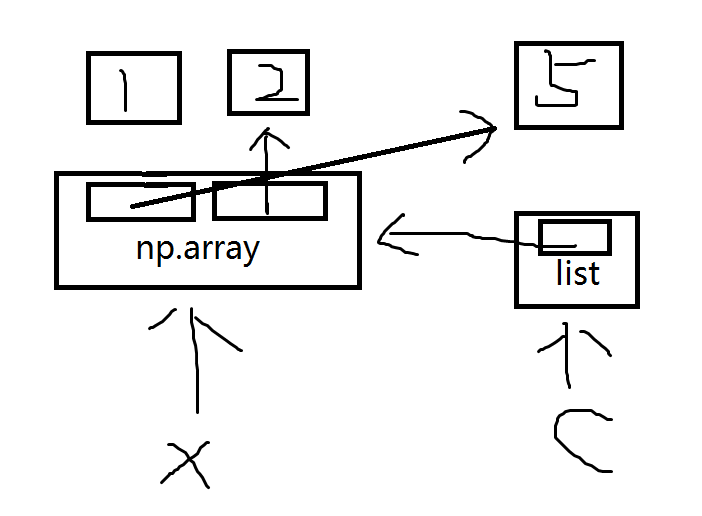
如果执行c[0][0]=5,那么示意图如下
接下来考虑一下for循环是在干嘛。对于如下代码
x=1
c=[x]
for i in range(len(c)):
c[i]+=1
循环开始前如下
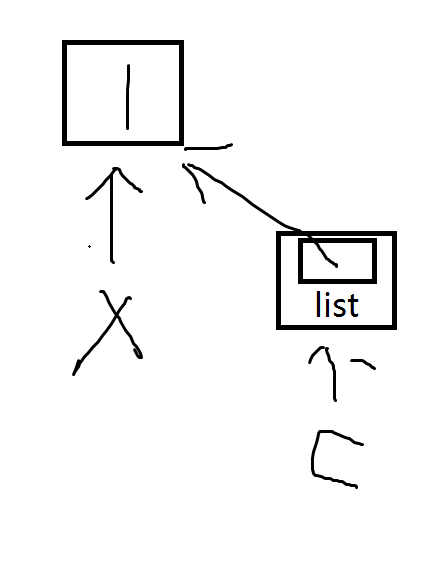
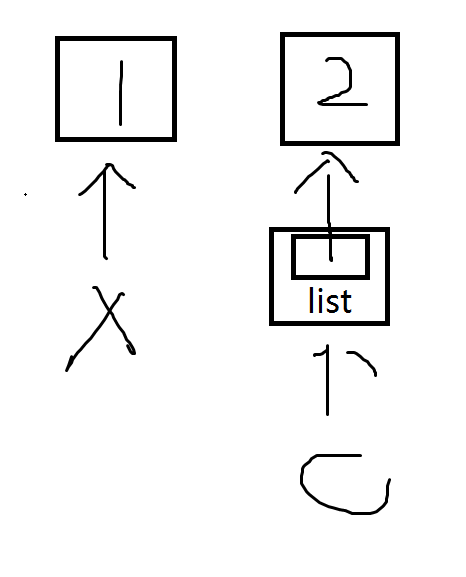
循环结束后如下
那如下代码呢?
y=[[1,2,3],[4,5,6]]
for i in y:
i+=[1] # 注意这里不能写成i+=1,列表是不可以广播的
print(i)
print(y)
输出是
[1, 2, 3, 1]
[[1, 2, 3, 1], [4, 5, 6]]
[4, 5, 6, 1]
[[1, 2, 3, 1], [4, 5, 6, 1]]
那如下代码呢?
z=[[1,2,3],[4,5,6]]
for i in z:
i=i+[1]
print(i)
print(z)
输出是
[1, 2, 3, 1]
[[1, 2, 3], [4, 5, 6]]
[4, 5, 6, 1]
[[1, 2, 3], [4, 5, 6]]
那如下代码呢?
import numpy as np
x=np.array([[1,2,3],[4,5,6]])
for i in x:
i+=1 #这里广播了一下
print(i)
print(x)
输出是
[2 3 4]
[[2 3 4]
[4 5 6]]
[5 6 7]
[[2 3 4]
[5 6 7]]
值得一提的是,如果对上面的代码的循环换成如下循环
for idx, val in enumerate(x):
print(id(x[idx]) == id(val))
那么输出全是False,我也不知道为什么
最后再来说一下函数的创建。对于如下代码
def add_end(L=[]):
L.append('END')
return L
执行完毕后,示意图如下
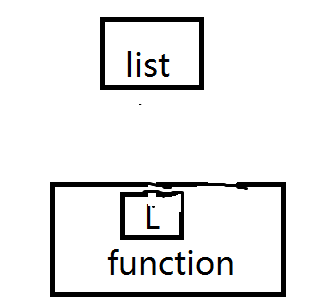
也就是说表示这个函数的对象以及默认参数已经存在了。注意L是一个引用,没有占用实际内存,并且此时并没有指向默认参数,之后调用的时候才会指向默认参数
如果执行f=add_end,那么示意图如下
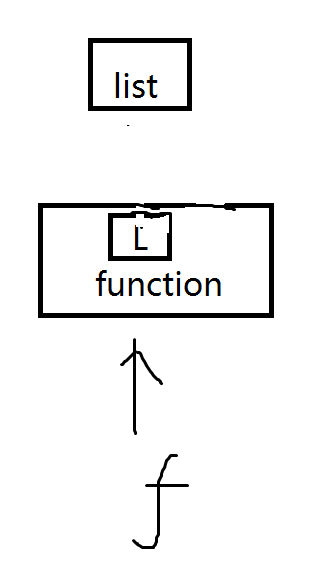
如果再执行如下代码
g=add_end
id(f)==id(g)
那么示意图如下
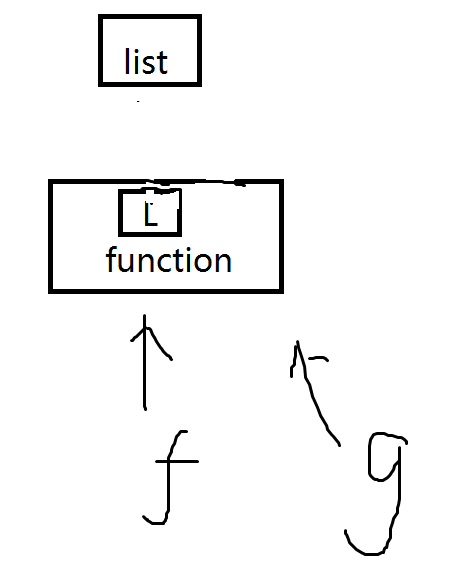
输出是True
此时可以去看一下这里说的大坑,注意到如果没有给函数传参数的话,L指向的就是最开始的那个已经创建的空列表
如果执行如下代码
a=add_end()
b=add_end()
id(a)==id(b)
那么输出是True
如果此时再执行
m=[1,2,3]
n=[4,5,6]
c=add_end(m)
d=add_end(n)
id(c)==id(d)
那么输出是False,其中c和m是[1, 2, 3, 'END'],d和n是[4, 5, 6, 'END']
此时如果再执行add_end(),那么输出是['END', 'END', 'END']
可以想一下为什么有上面的结果


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2024-02-19 Sasha and the Wedding Binary Search Tree
2024-02-19 Sasha and the Casino
2024-02-19 Sasha and a Walk in the City
2024-02-19 CF思维题集合
2024-02-19 Sasha and the Drawing
2024-02-19 天气预报
2024-02-19 导弹防御系统