185 注意力模型
我们利用
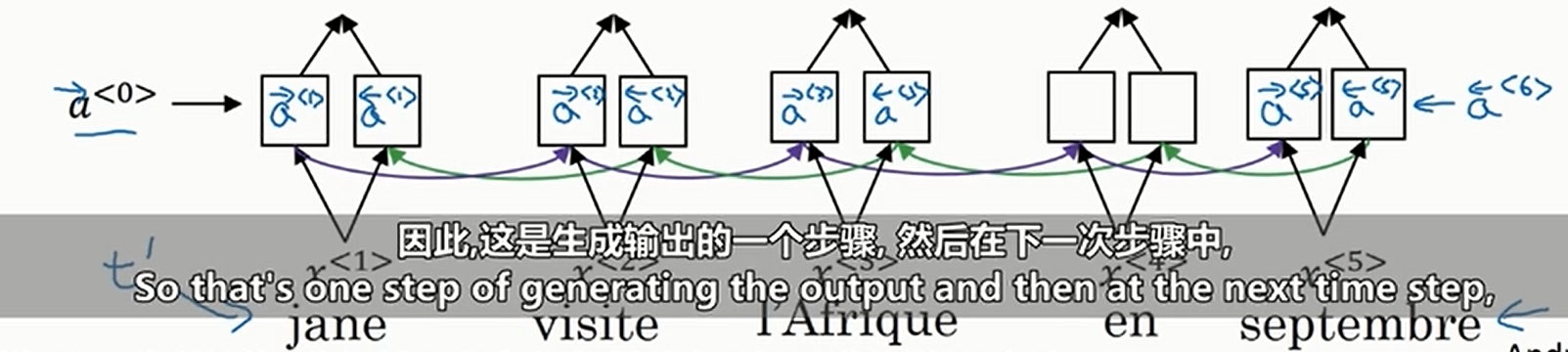
然后预测的时候我们使用普通的RNN,但是这个RNN的输入取决于源句子的每一个单词的加权和。我们用
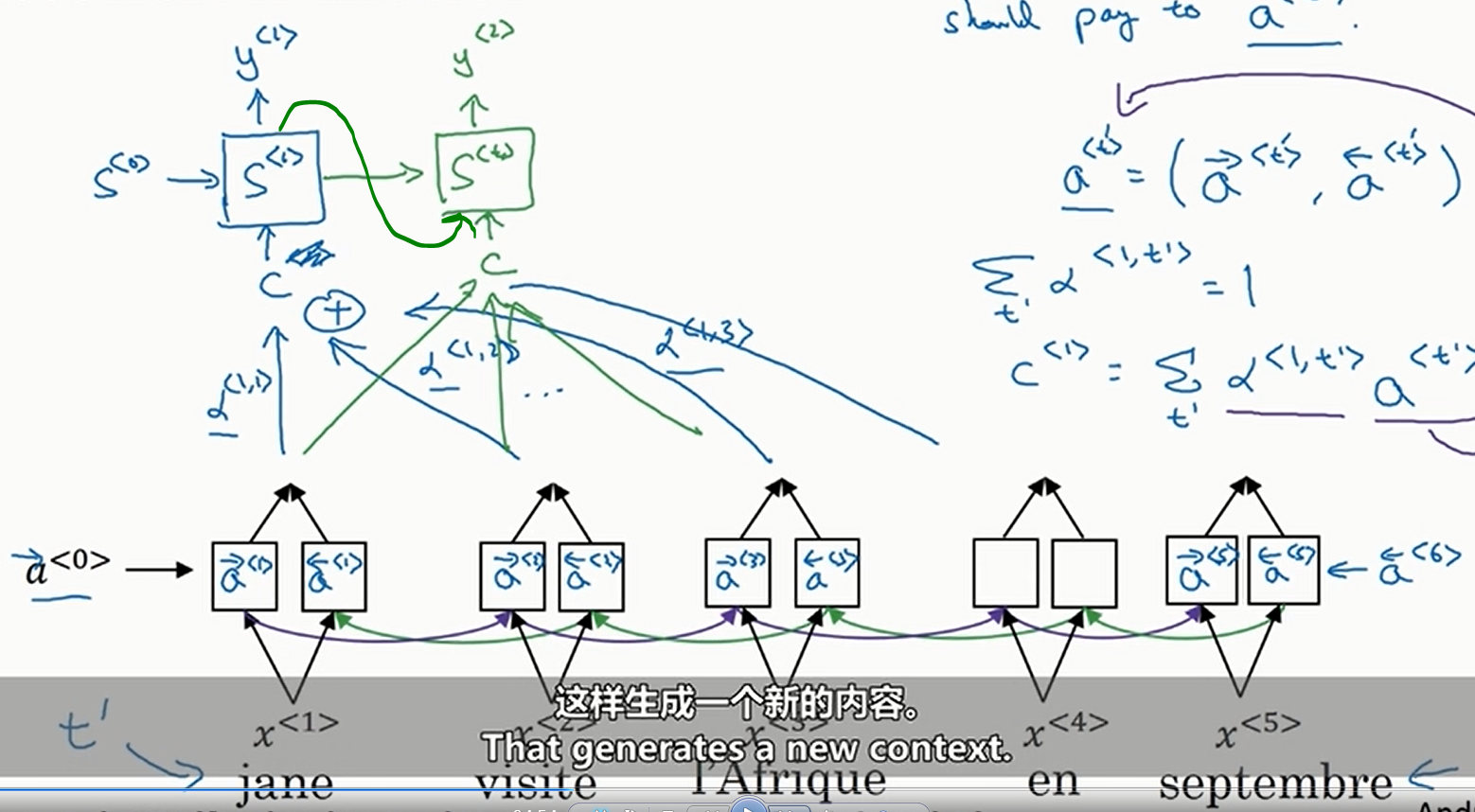
其中
那么怎么学习注意力权重呢?实际上,如下
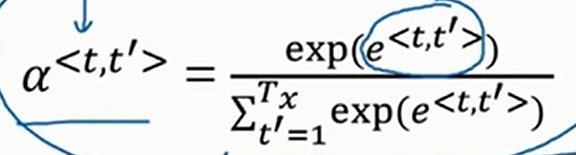
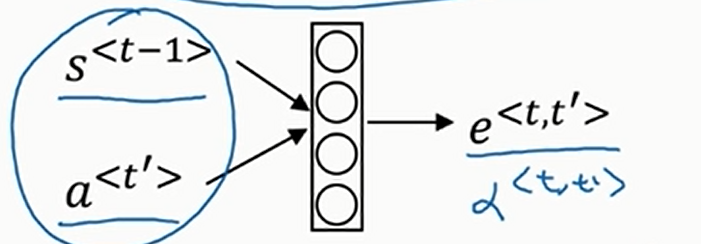
那么
这就让注意力机制有了一个缺点,就是运行该算法需要二次时间或者二次成本(注意力权重参数个数等于输入句子的长度乘以输出句子的长度
可以画出热力图如下

不难看出,相对应的输入和输出单词的注意力权重很高


我们利用
然后预测的时候我们使用普通的RNN,但是这个RNN的输入取决于源句子的每一个单词的加权和。我们用
其中
那么怎么学习注意力权重呢?实际上,如下
那么
这就让注意力机制有了一个缺点,就是运行该算法需要二次时间或者二次成本(注意力权重参数个数等于输入句子的长度乘以输出句子的长度
可以画出热力图如下
不难看出,相对应的输入和输出单词的注意力权重很高


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2024-02-19 Sasha and the Wedding Binary Search Tree
2024-02-19 Sasha and the Casino
2024-02-19 Sasha and a Walk in the City
2024-02-19 CF思维题集合
2024-02-19 Sasha and the Drawing
2024-02-19 天气预报
2024-02-19 导弹防御系统