

173 词转换成向量形式
介绍一下

我们获得单词的嵌入向量后,就放入神经网络中去跑,再利用
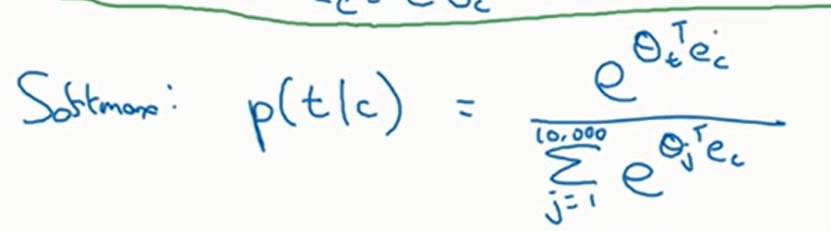
损失函数就是交叉熵损失函数
上面的算法在训练嵌入矩阵这一块的效果非常好,但是存在一个问题,就是计算速度太慢,主要瓶颈是分母的求和计算
一个解决方法是不使用
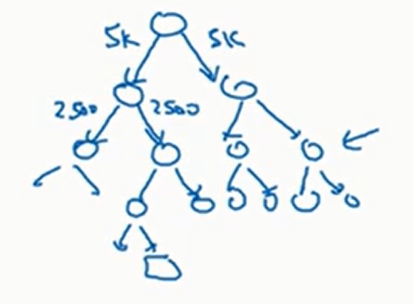
比如说现在要预测,根节点有一个二元分类器告诉我们输出的单词在前面五千个词和后面五千个词的概率,我们选择概率更大的节点,然后重复上述过程
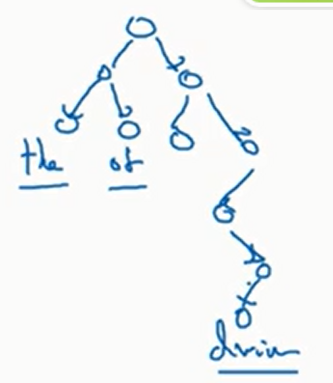
注意分层
再介绍一下负采样法。此时我们新定义训练集。我们像上面一样抽取
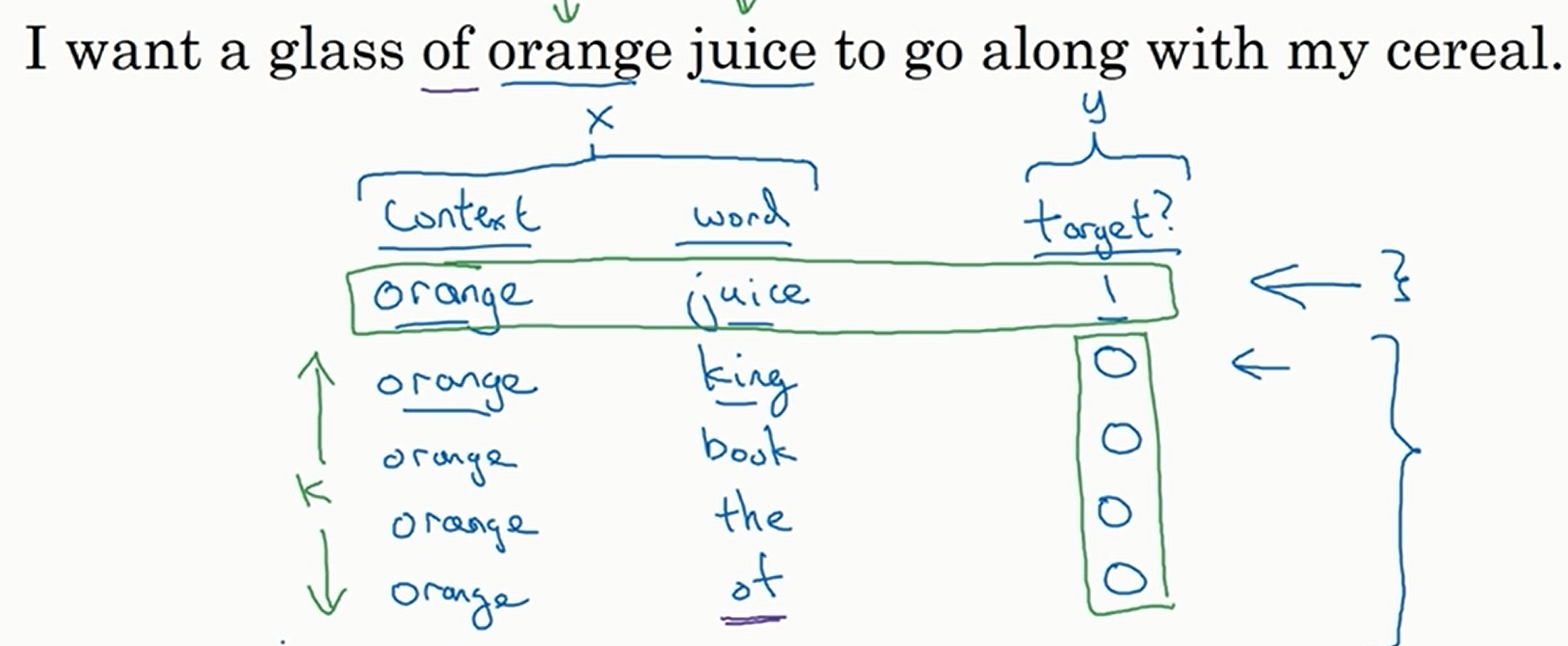
然后将
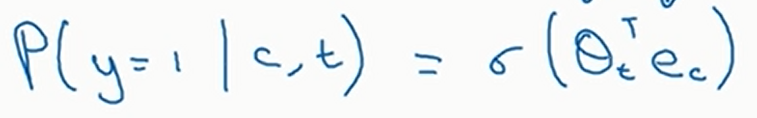
假设
那么随机抽取应该如何抽取呢,也就是说应该以什么分布去抽取呢?均匀分布显然那不太好,但是如果按照出现频率来抽取,也会得到很多and,the等词。论文作者使用的是如下分布来做一个折中
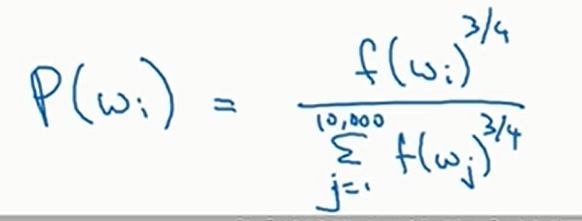
其中
嵌入矩阵其实有很多已经训练好了的开源的,可以直接下载


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2024-02-16 序列统计
2024-02-16 糖果盒
2024-02-16 何老板请客4
2024-02-16 何老板请客2
2024-02-16 何老板请客1
2024-02-16 体操队形1
2024-02-16 体操队形