

第二课 信用卡欺诈预测
数据预处理
导包
除了常规的导包,这里还有一行代码如下
pd.set_option('display.float_format', lambda x:'%.2f' % x)
作用如下

查看数据
这里查看就跟普通的差不多,不赘述了,提几个trick
- 描述性统计的时候可以转置,这样子看起来更好看
- 描述性统计的时候可以同时观察均值和标准差来判断数据的波动范围
特征工程
目标变量
也就是看是否有样本不均衡
特征衍生
发现Time(以秒为单位)这一个特征的离散型太强,没这个必要,因为交易的时候差几十秒几百秒可能根本看不出什么(另一个例子,统计全国人民吃早饭的时候,以小时为单位来划分就比以秒为单位来划分更靠谱,差几十秒吃早饭说明不了什么),所以我们进行离散化。使用代码data['Hour']=data['Time'].apply(lambda x:divmod(x,3600)[0])即可
特征选择
信用卡正常消费和盗刷对比
这里视频在画热力图,但是跟我们平常的热力图不同。我们按照样本类别画热力图,可以观察在正负样例中不同特征的特点(注意这个只是观察特征之间的特征,没有能够观察特征与标签的特点),如下
Xfraud = data.loc[data["Class"] == 1]
XnonFraud = data.loc[data["Class"] == 0]
correlationNonFraud = XnonFraud.loc[:, data.columns != 'Class'].corr()
mask = np.zeros_like(correlationNonFraud)
indices = np.triu_indices_from(correlationNonFraud) # 右上部分索引
mask[indices] = True
grid_kws = {"width_ratios": (1, 1, 0.05), "wspace": 0.2}
f, (ax1, ax2, cbar_ax) = plt.subplots(1, 3, gridspec_kw=grid_kws, figsize=(22, 9))
cmap = sns.diverging_palette(220, 8, as_cmap=True)
ax1 = sns.heatmap(correlationNonFraud, ax=ax1, vmin=-1, vmax=1,
cmap=cmap, square=False,
linewidths=0.5, mask=mask, cbar=False)
ax1.set_xticklabels(ax1.get_xticklabels(), size=16)
ax1.set_yticklabels(ax1.get_yticklabels(), size=16)
ax1.set_title('Normal', size=20)
correlationFraud = Xfraud.loc[:, data.columns != 'Class'].corr()
sns.heatmap(correlationFraud, vmin=-1, vmax=1, cmap=cmap, ax=ax2,
square=False, linewidths=0.5, mask=mask, yticklabels=True, cbar_ax=ax3,
cbar_kws={'orientation': 'vertical', 'ticks': [-1, -0.5, 0, 0.5, 1]})
ax2.set_title('Fraud')
执行的结果如下
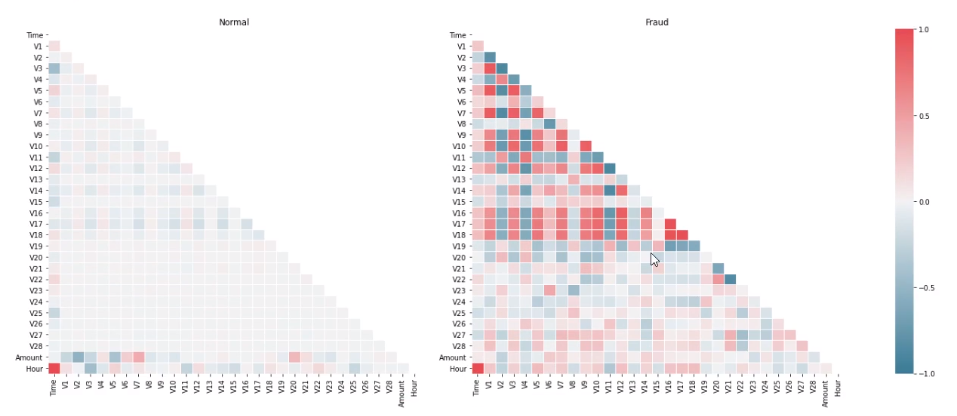
其实就强调一个点,就是热力图的颜色是cmap,这个看起来非常清楚
那么对这个热力图的分析是:从上图可以看出正常信用卡中,没什么相关性,而信用卡被盗刷的事件中,部分变量之间的相关性更明显。其中变量V1、V2、V3、V4、V5、V6、V7、V9、V10、V11、V12、V14、V16、V17和V18以及V19之间的变化在信用卡被盗刷的样本中呈性一定的规律。特征V8、V13、V15、V20、V21、V22、V23、V24、V25、V26、V27和V28规律不明显!是否有规律就看是否存在较多的红色和蓝色块
交易金额和交易次数
代码如下
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(16, 6))
ax1.hist(data['Amount'][data['Class'] == 1], bins=30)
ax1.set_title('Fraud')
plt.yscale('log')
ax2.hist(data['Amount'][data['Class'] == 0], bins=100)
ax2.set_title('Normal')
plt.xlabel('Amount($)')
plt.ylabel('count')
plt.yscale('log')
画出的图如下
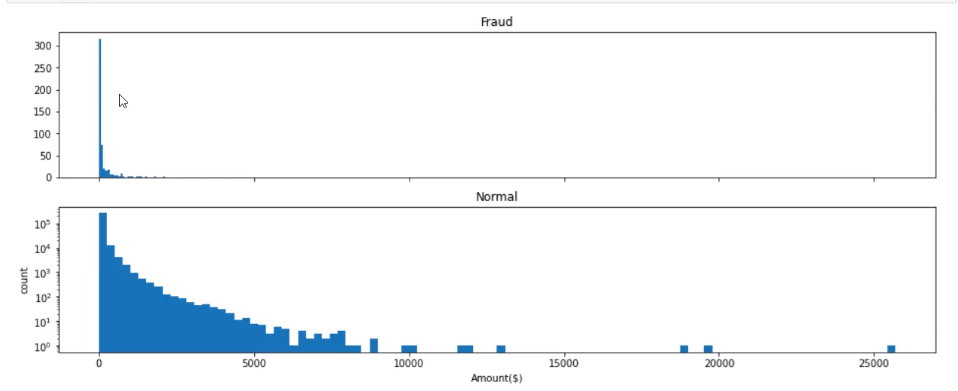
这里注意的是一定要用plt.yscale('log'),如果不用的话就像下面这个样子
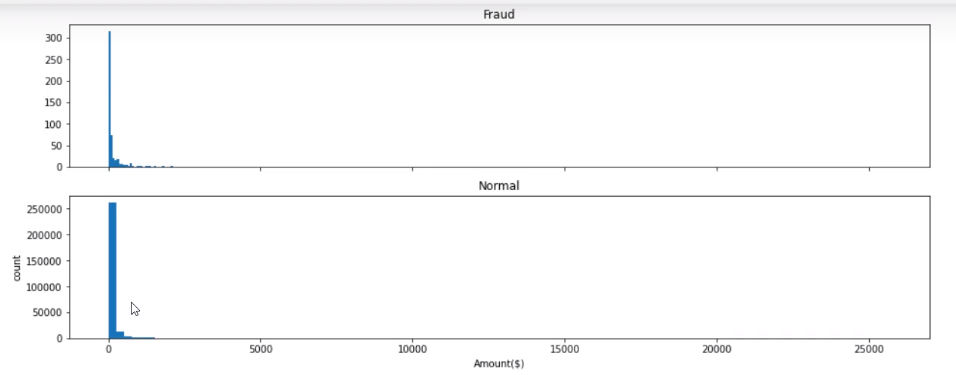
因为刻度的范围实在是太大了,如果不用的话,就会挤在一起,看不出差别来了
上面的输出说明:信用卡被盗刷发生的金额与信用卡正常用户发生的金额相比呈现散而小的特点,这说明信用卡盗刷者为了不引起信用卡卡主的注意,更偏向选择小金额消费。
信用卡消费时间分析
代码如下
sns.factorplot(x='Hour', data=data, kind='count', palette='ocean', size=6, aspect=3)
输出如下
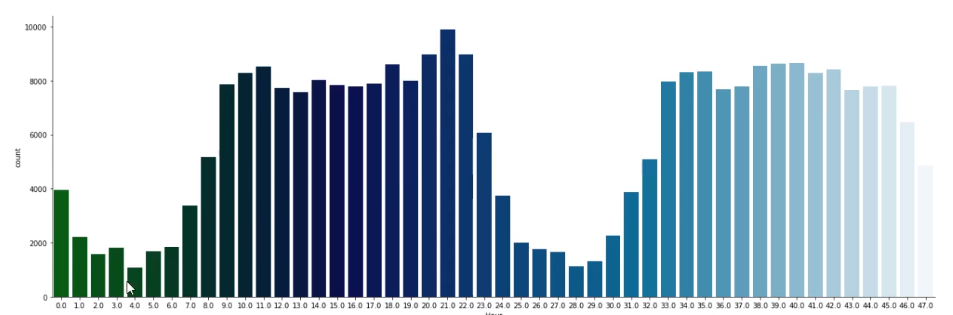
从图中容易看出高频使用信用卡的时间区间。这里视频中没干的一件事我觉得可以干的就是可以分析一下信用卡盗刷时间
交易金额和交易时间的关系
代码如下
f, (ax1, ax2) = plt.subplots(2, 1, sharex=True, figsize=(16, 6))
cond1 = data['Class'] == 1
ax1.scatter(data['Hour'][cond1], data['Amount'][cond1])
ax1.set_title('Fraud')
cond2 = data['Class'] == 0
ax2.scatter(data['Hour'][cond2], data['Amount'][cond2])
ax2.set_title('Normal')
输出如下
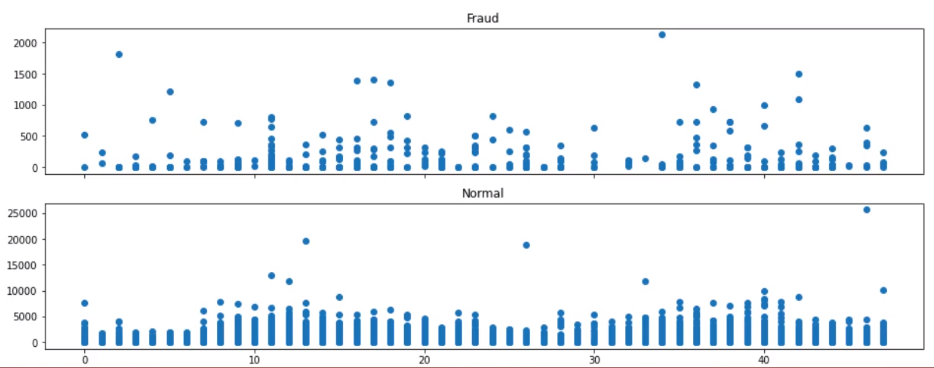
看不出什么东西来,算了。当然也可以验证我们之前的猜测:盗刷的金额不敢太大
这里视频还做了分析一下信用卡盗刷时间,完成了之前的遗憾,代码如下
sns.catplot(x='Hour', kind='count', data=data[cond1], height=9, aspect=2)
输出如下
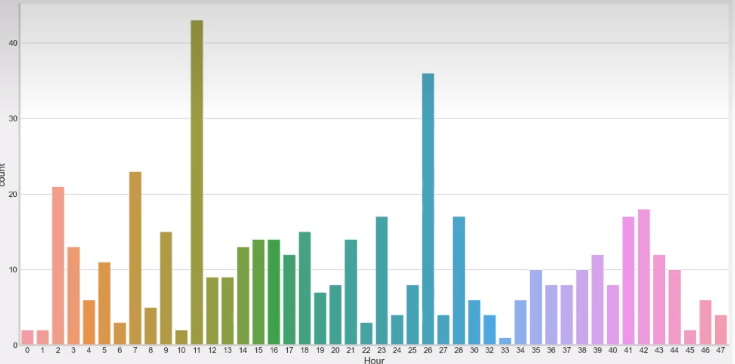
分析如下:从上图可以看出,在信用卡被盗刷样本中,离群值发生在客户使用信用卡消费更低频的时间段。信用卡被盗刷数量案发最高峰在第一天上午11点达到43次,其余发生信用卡被盗刷案发时间在晚上时间11点至第二天早上9点之间,说明信用卡盗刷者为了不引起信用卡卡主注意,更喜欢选择信用卡卡主睡觉时间和消费频率较高的时间点作案;同时,信用卡发生被盗刷的最大值也就只有2,125.87美元。
特征分布(非常重要,帮助筛选特征)
他这个是比较新的分析数据的维度。思路是这样的:由于我们现在有两个标签,所以如果一个特征在不同的标签下的分布明显不同,那么这个特征就非常有用。代码如下
plt.rcParams['font.family'] = 'STKaiti'
v_feat = data.iloc[:, 1:29].columns
plt.figure(figsize=(16, 4 * 28))
cond1 = data['Class'] == 1
cond2 = data['Class'] == 0
gs = gridspec.GridSpec(28, 1) # 子视图
for i, cn in enumerate(v_feat):
ax = plt.subplot(gs[i])
sns.distplot(data[cn][cond1], bins=50) # 欺诈
sns.distplot(data[cn][cond2], bins=100) # 正常消费
ax.set_title('特征概率分布图' + cn)
然后我们将选择在不同信用卡状态下的分布有明显区别的变量。因此剔除变量V8、V13、V15、V20、V21、V22、V23、V24、V25、V26、V27和V28变量。这也与我们开始用相关性图谱观察得出结论一致。同时剔除变量Time,保留离散程度更小的Hour变量。
特征缩放
就是使用StandardScaler而已,但是如果我们只对一部分特征进行归一化应该怎么做?用data_new[col]=StandardScaler.fit_transform(data_new[col])即可
特征重要性
就是随机森林建完模之后画plt.bar和plt.step,效果如下
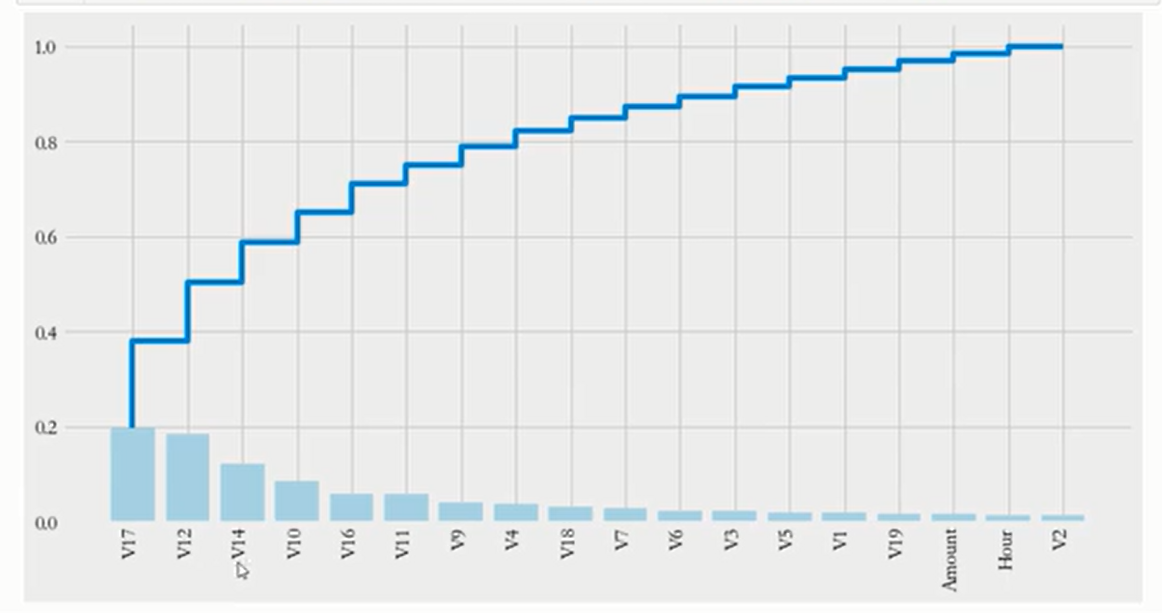
接下来建模就重点关注前面几个特征就好了
模型训练
过采样
使用SMOTE,不是简单的复制,而是使用近邻规则进行上采样。近邻规则:比如某个特征的范围是X,y=SMOTE().fit_resample(X,y),跟SMOTE().fit_sample没区别,只是更新版本的sklearn会用前者
算法建模
交叉验证
视频使用的是网格搜索,但是网格搜索不是按照
from sklearn.metrics import make_scorer, roc_auc_score
from sklearn.model_selection import GridSearchCV
# 创建AUC评估器(自动处理多分类)
auc_scorer = make_scorer(roc_auc_score,
needs_proba=True, # 需要概率预测
multi_class='ovo') # 多分类策略
# 配置GridSearchCV
grid = GridSearchCV(
estimator=your_model,
param_grid=param_grid,
scoring=auc_scorer, # 使用AUC评分
cv=5,
n_jobs=-1
)
# 训练模型(需确保y是正确编码的类别标签)
grid.fit(X, y)
模型评估
精确度-召回率曲线
这个比较新,可以看看视频,跟ROC是一个东西
ROC曲线
各评估指标的对比
这个是说在同一个图中将不同的评价指标画出来,如下



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2024-02-16 序列统计
2024-02-16 糖果盒
2024-02-16 何老板请客4
2024-02-16 何老板请客2
2024-02-16 何老板请客1
2024-02-16 体操队形1
2024-02-16 体操队形