

第一课 泰坦尼克号预测
导入数据
将训练数据与测试数据合并
查看数据
描述性统计查看是否有异常值
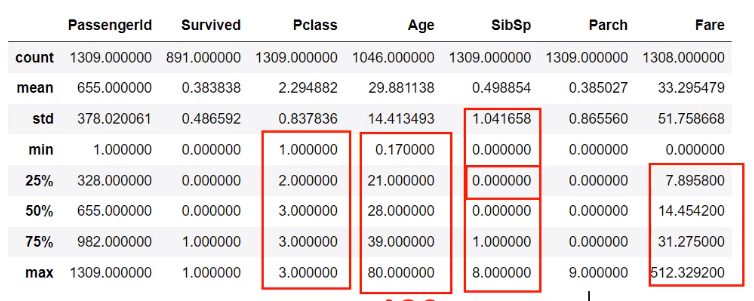
看看各个数据是否偏态,最值是否异常
查看特征与标签之间的关系

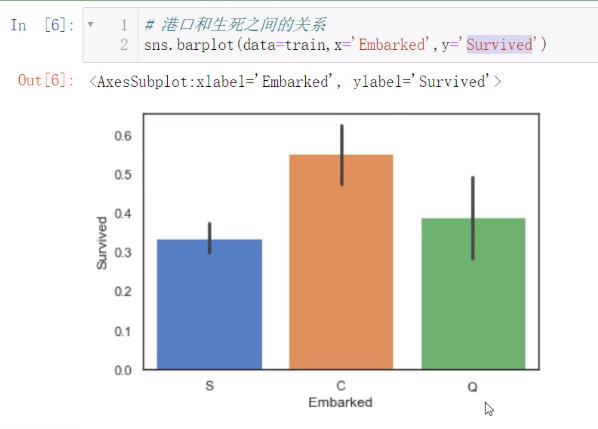
在泰坦尼克号这里,不要局限于查看绝对数量,还要算生存率

然后可以发现在
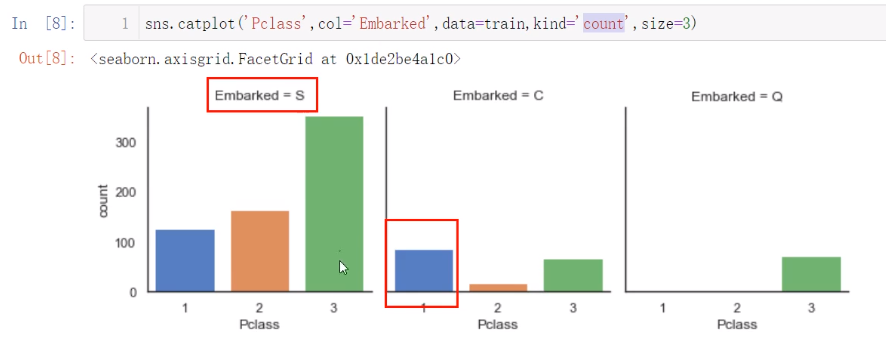
可以发现确实是如我们所想
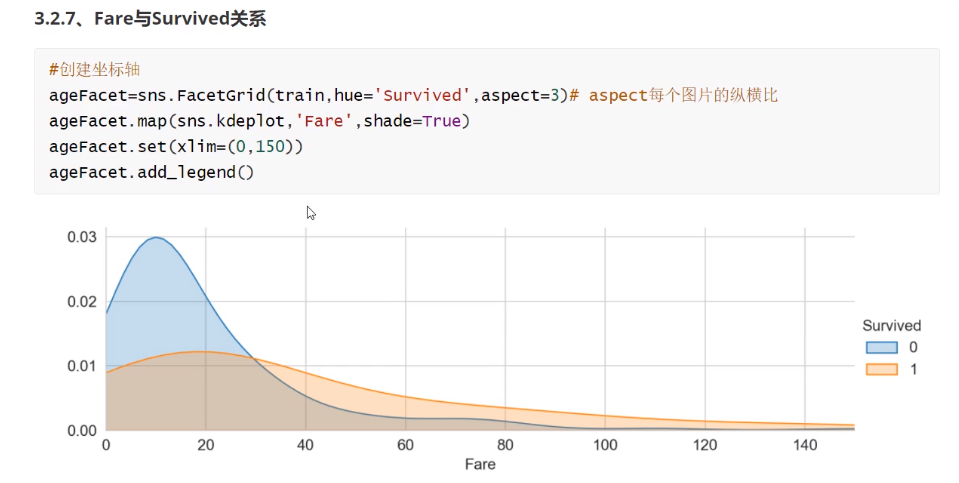
剩下的都类似,就不赘述了
查看标签是否有偏态
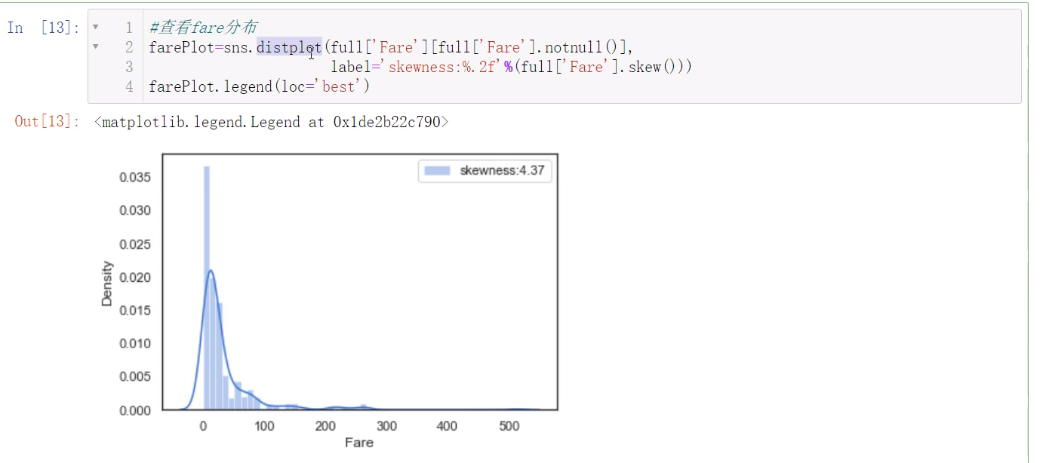
然后采用np.log1p变换即可
数据预处理
填充缺失值
这里的填充还是注意,要划分组。比如填写价格时,发现缺失的样本是三等舱,于是将三等舱的价格平均填上去。但是对于登船口,我们发现不好推断,所以就直接填众数就好了
还要注意一下,这里Cabin这个特征缺失太多了,以前的方法是直接删掉,教程是填充了一个U,实际上DS给出的做法才是正确的,如下

还有一些特征可以用随机森林填写,可以在这里做,也可以在特征创造完了之后做
特征工程
特征创造
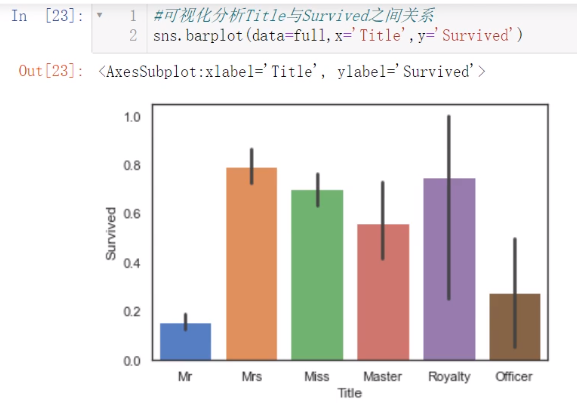
将Name中提取出Title.头衔也有很多种,我们也可以再进行浓缩一下,浓缩完了之后查看新特征与生存与否的关系
然后还可以提取家庭成员的数量
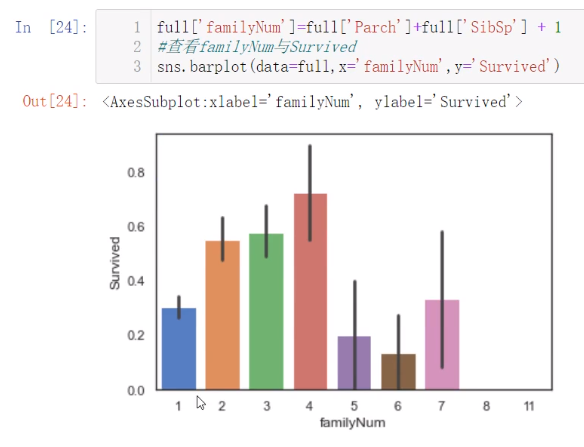
查看新特征与标签的关系,然后继续浓缩

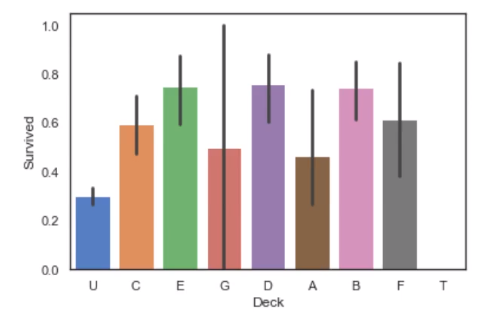
Cabin应该也很有关系,提取出首字母,画出与标签的关系如下
票号看起来没啥关系,实际上多个人合购的话票号是一样的,所以有如下代码
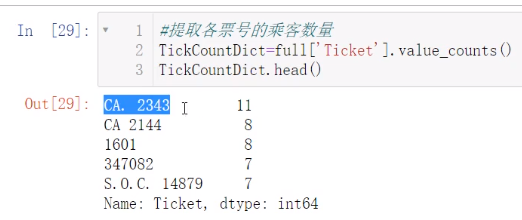
发现有重合,于是可以统计如下
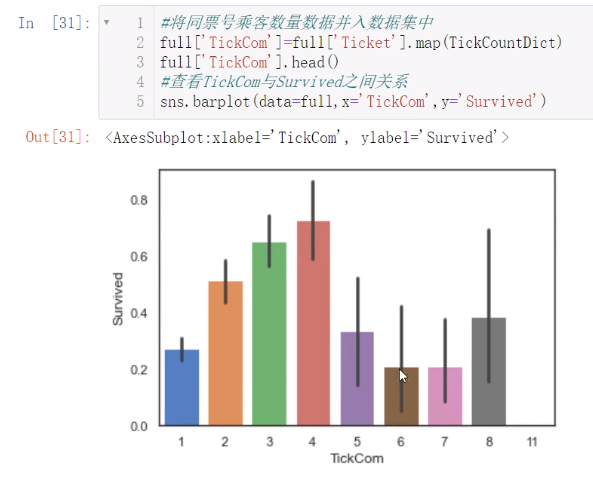
这个是按照频率而不是票号统计的

用随机森林填写Age缺失值,先找出相关系数,筛选出相关性较大的各个特征。注意corr只能计算数值,而Title显然跟年龄的关系很大,所以还要先建立独热编码
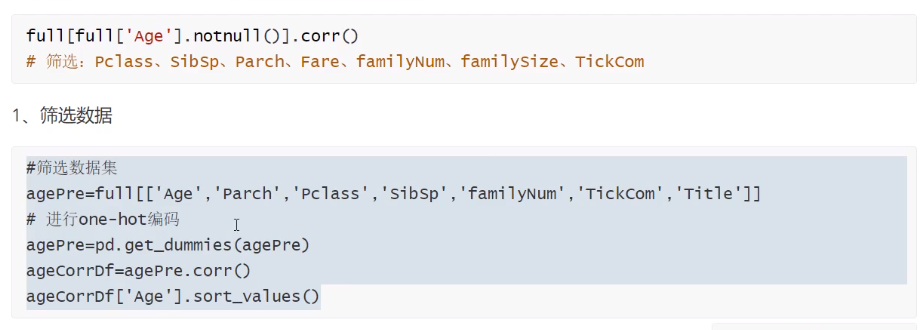
只不过这里推测实在是太难了,没有出生日期,随便怎么推断都很难,所以这里填写的准确率只有
同组识别


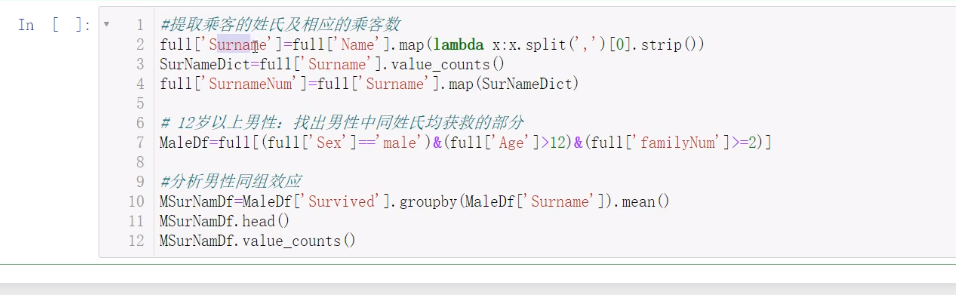

这个修改数据说的是,比如将年龄改小等等。这样子是为了更符合数据规律,但是感觉修改数据不太好,可以直接分组创造新特征吧

注意修改数据,一定是修改的生存率为

筛选子集


建模
建模的思路比较清奇:首先选择一大堆模型,不调惨去跑数据,然后选择排名靠前的几个数据,再利用网格搜索。这样子直接把xgboost抛弃了。。。建议别学
视频的最后三个还没看,将ROC啥的,有空看了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2024-02-12 Asteroids G
2024-02-12 猫和狗
2024-02-12 超级英雄
2024-02-12 信与信封问题
2024-02-12 将他们分好队
2024-02-12 田忌赛马