第一课 通用流程
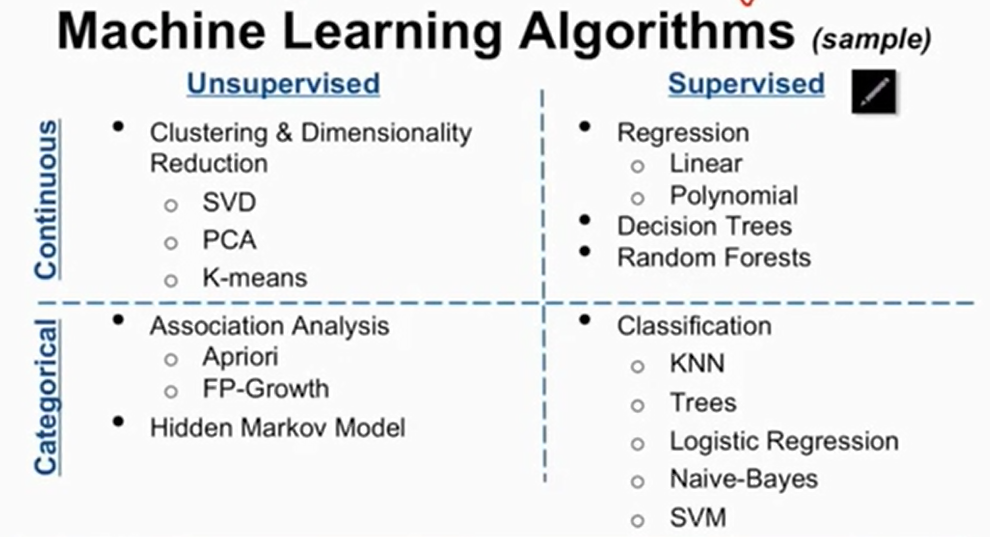
其中\(\text{KNN}\)使用已经很少了,\(\text{SVM}\)在中小型数据集上表现很好

了解场景和目标
这个主要是说可以看看有没有类似的问题,然后可以借鉴那个问题的参数
了解评估准则
比如\(\text{SVM}\),可能以准确率,精确率,召回率等等作为评估准则
认识数据
一般指可视化数据,高维数据可以用\(\text{t-SNE}\)可视化
数据预处理
数据清洗
- 不可信的样本丢掉。比如一个牙刷花了二十万买,这显然就是假数据
- 缺省值非常多的字段考虑不用,缺省值很少的字段进行填充,缺省值不多不少的可以将其作为一个独立的类型使用独热编码
数据采样
- 上/下采样。以负样本更多为例,前者指将正样本重复很多次,后者指删除很多负样本
- 保证样本均衡。除了上下采样,还可以对正样本赋予更大的权重,甚至还可以使用\(\text{Bagging}\).比如正负样本比例为\(1:10\),那么我们训练十个分类器,每个分类器的训练集是\(1:1\)的正负样本,最后再集成
特征工程
特征处理
数值型
类别型
时间类
可以以不同的时间长度作为单位时间。这里相当于将连续型变量离散化了
文本型
统计型
组合特征
特征选择
过滤法
包装法
嵌入法
模型融合
Bagging
sklearn中有Bagging的类,可以直接问AI.原理跟随机森林是一样的。分类做投票,回归取平均
Stacking
这个简单来说,就是最终的预测器以基预测器的输出结果作为特征去训练,如下
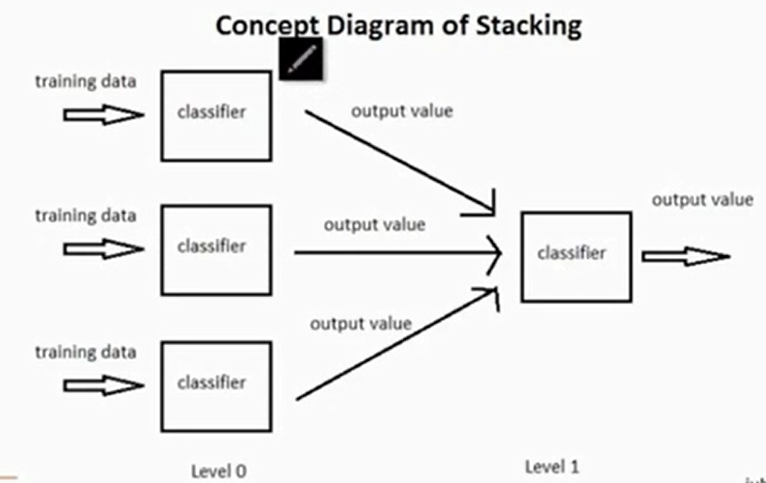

跟神经网络有点像

 浙公网安备 33010602011771号
浙公网安备 33010602011771号