单词
考虑暴力怎么做。一个很自然的想法就是枚举每个模式串,并将当前枚举到的模式串作为文本串,然后内层循环再依次枚举模式串,看每个模式串在文本串中出现了多少次
发现上述过程与AC自动机的匹配很像,于是建立AC自动机,将每个串都放在AC自动机上跑query,当前跑到的u就代表这个串的一个前缀,然后让j=u一直跳fail,给途中经过的每个点都加上一,表示当前跑的这个串的前缀对j所表示的串有贡献。这个样子一定不重不漏
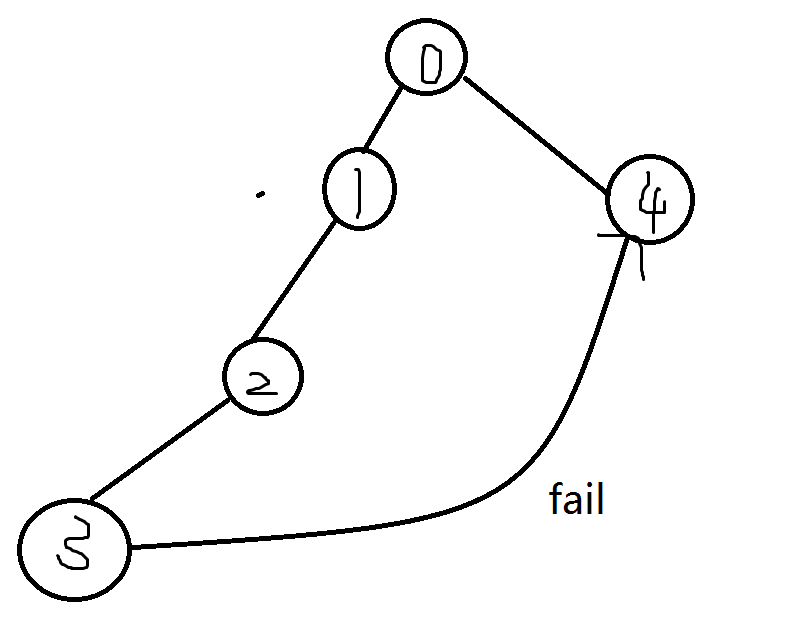
考虑优化,不难发现如果从u向fail[u]连一条线,最后连出来的图是一个DAG,而且任意一条边的起点的深度一定大于终点的深度,于是可以进行DP,像差分数组一样途中累加贡献就好了
代码的写法:如果完全按照上面的思路来写,就要枚举每个模式串作为文本串,然后将query函数中的内层for循环变成\(O(1)\)的操作(就是直接添加边\((u,fail[u])\)),最后跑拓扑排序。这样子当然没问题,但是有更简单更快速的写法。我们在字典树建立的过程中,就将途中经过的点累加一次,最后直接对所有点跑拓扑排序就好了。由于任意一条边的起点的深度一定大于终点的深度,所以我们直接倒序循环BFS中的点就好了。注意不能倒序循环点的编号,因为编号小的点可能连接编号大的点,如下
具体见代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号