匹配统计
这个是对
注意不能简单地将
这道题目有hash+二分的做法,比较好想,下面介绍KMP的做法
我们先考虑一个暴力的做法,我们把
那我们怎么用KMP呢?我们考虑利用
接下来就看看这篇题解
这篇题解怎么保证不重不漏呢?考虑我们上面的暴力算法,在暴力的过程中,我们给每一个匹配长度分类,如下
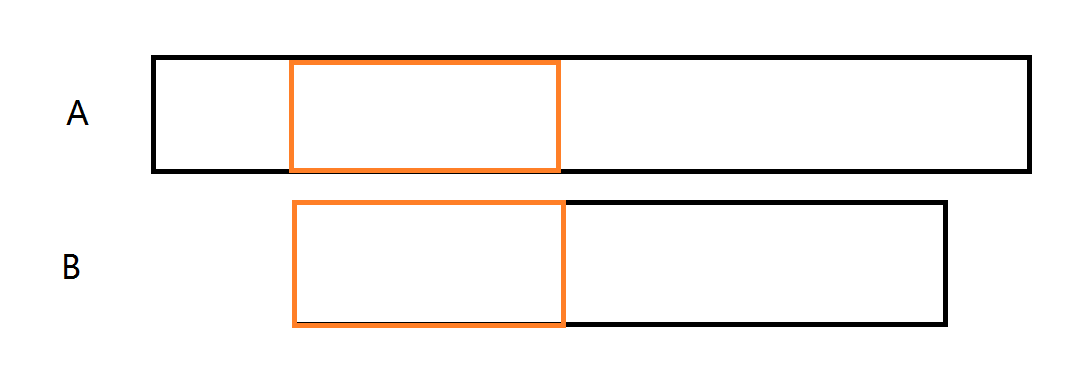
假设某一次
那我们朴素的加
我们将
那么在暴力的过程后


这个是对
注意不能简单地将
这道题目有hash+二分的做法,比较好想,下面介绍KMP的做法
我们先考虑一个暴力的做法,我们把
那我们怎么用KMP呢?我们考虑利用
接下来就看看这篇题解
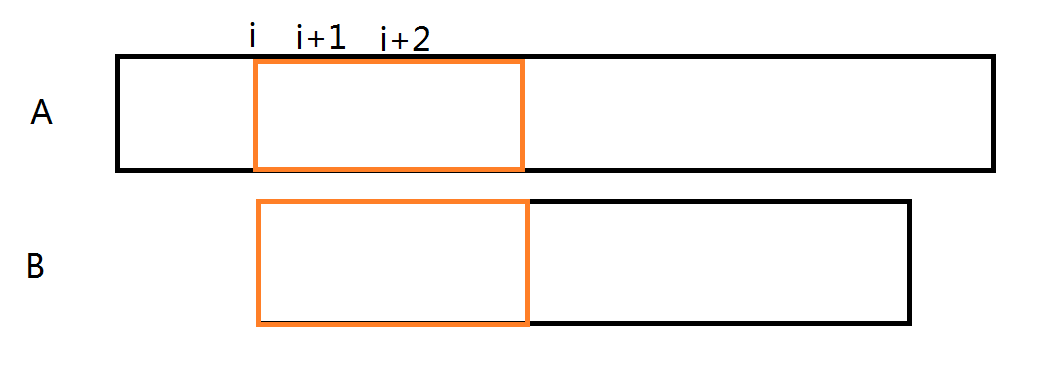
这篇题解怎么保证不重不漏呢?考虑我们上面的暴力算法,在暴力的过程中,我们给每一个匹配长度分类,如下
假设某一次
那我们朴素的加
我们将
那么在暴力的过程后


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构