关于A*的一些理解
A*算法,本质是对BFS的一种优化,无论这个BFS是普通的BFS(搜索树上边权为1)还是优先队列BFS(搜索树上的边权可能大于1)
蓝书上论证正确性那一段说的\(s\)指的是目标状态的某一状态(即\(s\)已经到达了目标状态但不一定最优)然后再去理解那一段话
但是,我想说的是,中间的点第一次被取出的时候不一定是这个点的最优状态,见下图
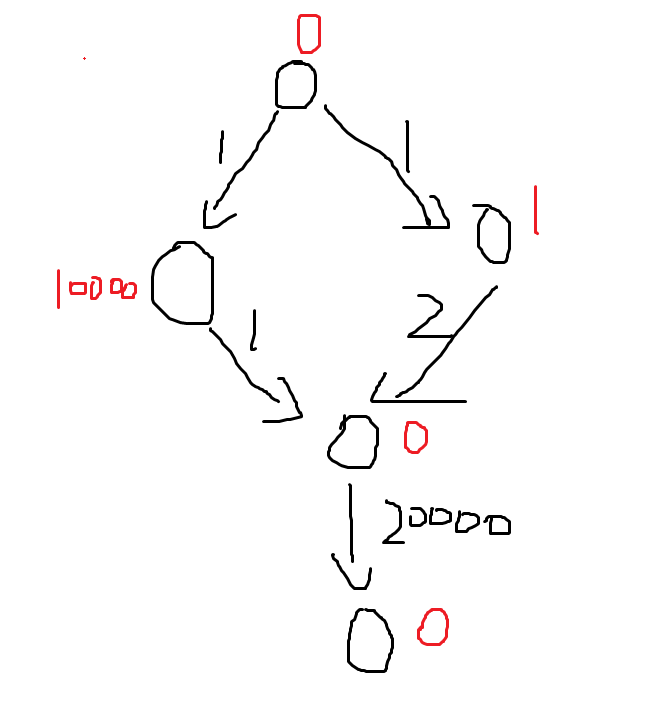
可以模拟一下,会发现倒数第二个点被入队了两次,而且第二次入队才是这个点的最优情况
出现这个的原因就是因为估价函数只跟当前这个状态有关
那么这种情况会不会影响最终的结论?
答案是不会
因为目标状态的估价函数一定为0,如果一个已经到达了目标状态但不是最优的\(s\)入队了,由于存在一个更优的目标状态,所以从起始状态到目标状态一定会存在一条路径,这条路径的终点是目标状态的最优情况而且每一个点的当前代价都是这些点的最优代价(我不管这条路径是什么时候被搜索出来的,反正肯定存在这么一条路径)。根据估价函数的性质,这条路径上的每一个点的当前代价+未来估价一定小于等于目标状态的最优情况,于是就小于\(s\)的当前代价,就是说在\(s\)被扩展之前,这条路径上的每一个点都会被扩展,所以目标状态的最优情况一定比\(s\)先扩展,所以不会影响答案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号