第九期|不是吧,我在社交媒体的照片也会被网络爬虫?
顶象防御云业务安全情报中心监测到,某社交媒体平台遭遇持续性的恶意爬虫盗取。被批量盗取用户信息和原创内容,经分类梳理和初步加工后,被黑灰产转售给竞争对手或直接用于恶意营销。由此不仅给社交媒体平台的数字资产带来直接损失,影响用户对社交媒体平台的信任,更破坏了内容产业的健康发展。
社交媒体是重要的内容平台
中国互联网络信息中心(CNNIC)第46次《中国互联网络发展状况统计报告》显示,截至2020年6月,微信朋友圈使用率为85.0%,QQ空间、微博使用率分别为41.6%、40.4%,较2020年3月分别下降6个百分点、2.1个百分点。
微信朋友圈、微博等主流社交平台长期占据大部分流量,并通过不断丰富的短视频、电商、本地生活等服务,构建完善的流量闭环和服务生态。通过社交平台,网民和企事业组织积极分享图文视频信息,进行各类宣传推广,展示个体形象。例如,2022年北京冬奥会是迄今收视率最高的一届冬奥会,在全球社交媒体上吸引超20亿人关注。
顶象防御云业务安全情报中心第BSI-2022-dpda号情报显示,有黑灰产团伙开发出专门的恶意网络爬虫软件,破解某社交媒体平台的通讯接口和算法,通过篡改IP地址等方式,绕过平台设置的安全防护措施,对该社交媒体进行高频的数据盗取。被盗取的数据包含社交媒体用户信息,以及用户原创的文章、图片、视频等内容。
社交媒体平台的数据是企业的重要数字资产。作为新型的生产要素,不仅是企业核心的竞争力,更是新产品、服务、流程和管理的重要组成部分。恶意爬虫的爬取、盗用行为,不仅造成企业数字资产损失,带来直接的经济损失,消耗了平台服务和带宽资源,严重破坏内容产业的生态秩序。
恶意爬虫肆意盗取社交媒体原创内容
机械工业出版社出版的《攻守道—企业数字业务安全风险与防范》一书中,认为恶意网络爬虫会带来数字资产损失、用户隐私泄露和扰乱业务正常运行等三大危害,并将“恶意网络爬虫”列为十大业务欺诈手段之一。
网络爬虫,又被称为网页蜘蛛,网络机器人,是按照一定的规则,自动地抓取网络信息和数据的程序或者脚本。网络爬虫分为两类,一类是搜索引擎爬虫,为搜索引擎从广域网下载网页,便于搜索检索,后者则是在指定目标下载信息,用于存储或其他用途。另一类是恶意爬虫,是从公开或半公开网络平台抓取商品、服务、文字、图片、用户信息、评价、价格信息以及账户密码、联系方式、身份等隐私信息。
顶象防御云业务安全情报中心分析发现,盗取某社交媒体的恶意爬虫共有两种:第一种恶意爬虫由开发编程能力的人员自主编写,能够根据需要和目的,对规则、逻辑进行自定义;第二种恶意爬虫是直接购买标准化的爬虫工具,简单易用上手快,同时搭售反爬工具。
爬虫开发制作门槛比较低。很多技术论坛社区有关于爬虫开发、研究、使用介绍,市面上也有很多专业的爬虫书籍。只要掌握Python编程语言,按照论坛、社区和书籍上提供的爬虫教程和实操案例,同时根据爬虫技术爱好者分享出来的平台、网站、App的API接口信息,就能够快速搭建出一套专门的爬虫工具。
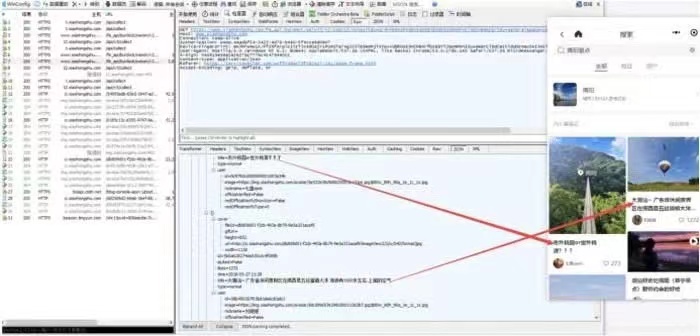
同时,市面也有很多标准化的爬虫工具。这类工具提供了可视化的操作,不懂编程、没有开发能力也能够使用。只需要简单的配置,就能够对目标进行爬取。不仅爬取的进度和结果是可视化,结果导出也相当便利。并且,这类工具还会提供付费购买的工具,帮助使用者绕过常规的反爬措施。
黑灰产盗取社交媒体数据的目的
黑灰产盗取数据是为了牟利。盗取社交平台的用户信息和原创内容后,黑灰产对数据进行储存、加工,然后行商业化售卖,甚至进行诈骗。顶象防御云业务安全情报中心分析发现,黑灰产盗取社交媒体数据主要是以下三个目的。
第一类,为其他平台导流。有非常多针对社交媒体的数据分析平台。通过对社交平台d用户账号信息、内容、浏览、点赞等数据分类处理后,就可以进行内容分析、榜单排行、数据监控等提供服务,输出为三方舆情服务。或者,提取出用户的关注聚焦点,制作类似聚焦的内容,为其他平台做导流。
第二类,搬运内容为其他账号吸引粉丝。粉丝是社交媒体账号影响力的重要体现之一。由于大多数账号自身创作能力有限,很多账号通过爬虫爬取他人的优质文章、视频,再将内容简单加工后重新发布到自己的账号,由此达到快速吸粉的目的。说白了,就是剽窃他人原创版权。
第三类,制作仿冒账号进行诈骗。通过爬虫爬取社交平台他人的信息、分享的文章、视频等内容,在同个平台或在另一个社交平台建立高仿的虚假账号,骗取粉丝的关注,然后进行各类欺诈。
此外,竞争对手也会利用网络爬虫进行恶性竞争。同行的竞争是赤裸裸的。不少公司会雇佣黑灰产,对目标平台发起数据盗取攻击,从而导致竞品无法正常使用。如果在某个重要的节点,通过恶意爬虫对目标平台进行大流量的访问或盗取,会瞬间过高的并发量,出现DDoS效果,导致大量普通用户无法正常访问该网站,干扰平台的正常运营。
恶意网络爬虫的技术特征
机械工业出版社出版的《攻守道—企业数字业务安全风险与防范》一书中,对恶意网络爬虫有详细的技术特征分析,大体来看,主包含以下几点特征。
1、访问的目标集中。恶意网络爬虫主要是爬取核心信息,因此只浏览访问多个页面,对于非涉及信息数据的页面不做不访问。
2、行为有规律。由于爬虫是程序化操作,按照预先设定的流程进行访问等,因此呈现出有规律、有节奏且统一的特征。
3、同一设备上有规模化的访问和操作。爬虫的目的是最短时间内抓取最多信息,因此同一设备会有大量离散的行为,包括访问、浏览、查询等。
4、访问IP地址异常。爬虫的IP来源地址呈现不同维度上的聚集,而且浏览、查询等操作时不停变换IP地址。并且很多爬虫程序伪装成浏览器进行访问,并且通过购买或者租用的云服务、改造路由器、租用IP代理、频繁变更代理IP等进行访问。
5、操作多集中非业务时间段。爬虫程序运行时间多集中在无人值守阶段。此时系统监控会放松,而且平台的带宽等资源占用少,爬虫密集的批量爬取不会对带宽、接口造成影响。
针对恶意网络爬虫的防控建议
基于恶意网络爬虫的技术特征以及社交媒体平台的特点,顶象防御云业务安全情报中心安全及防控建议如下。
1、安全防护建议
加强平台风险环境监测。社交平台的客户端可集成安全SDK,使其定期对App的运行环境进行检测,对于存在代码注入、hook、模拟器、云手机、root、越狱等风险能够做到有效监控和拦截。
保障客户端安全。社交分析平台的APP和网页,可以分别部署H5混淆防护及端安全加固,以保障客户端安全。
保障通信传输安全。黑产在业务通信传输的环节,可能会尝试篡改、爬取报文数据。通过对通讯链路的加密,可防止终端安全检测模块的数据被篡改和冒用。
加强业务安全策略防控。针对批量爬虫的风险特征,可将社交媒体中各个业务查询场景的请求接入业务安全风控系统。同时将终端采集的设备指纹信息、用户行为数据等传输给风控系统,通过在风控系统配置相应的安全防控策略,有效地对风险进行识别和拦截。
1)设备终端环境检测。识别客户端(或浏览器)的设备指纹是否合法,是否存在注入、hook、模拟器等风险。通常批量作弊软件大多都存在以上风险特征。
2)行为检测。基于设备行为进行策略布控。针对同设备高频查询,同IP高频查询,相同IP段反复高频查询的请求进行监控。
3)名单库维护。统计基于风控历史数据,对于存在异常行为的账号、IP段进行标注,沉淀到相应的名单库。对于名单表内的数据在做策略时进行分层,适当加严管控。
4)外部数据服务。考虑对接手机号风险评分、IP风险库、代理邮箱检测等数据服务,对于风险进行有效识别和拦截。
2、处置及防控措施
顶象防御云业务安全情报中心建议,对识别为风险的请求进行实时拦截,直接反馈查询失败等,或在发现异常后通过弹出验证码的方式要求进行人机识别。
第五代智能验证码。验证码能够阻挡恶意爬虫盗用、盗取数据行为,防止个人信息、平台数据泄露。当某一设备或账户访问次数过多后,就自动让请求跳转到一个验证码页面,只有在输入正确的验证码之后才能继续访问网站。但是设置复杂的验证码会影响用户操作,带来负面的体验感受。
设备指纹+风控引擎+智能模型平台。设备指纹及时识别注入、hook、模拟器等风险,风控引擎对注册、登录、领取等操作进行风险实时识别判定;智能模型平台帮助社交媒体构建专属风控模型,由此构建多维度防御体系,有效拦截各种恶意爬虫风险,且不影响正常用户体验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号