成都、贵州核酸检测系统“崩溃”背后的技术原因
9月3日“成都发布”消息称,9月1日,成都市新型冠状病毒肺炎疫情防控指挥部发布《关于在全市开展全员核酸检测的通告》,决定自9月1日至9月4日在全市范围内开展全员核酸检测。9月2日晚,核酸检测系统出现异常,导致采样排队时间过长,核酸检测进度缓慢,给市民群众带来困扰和不便。
无独有偶,9月3日12时许,贵州省核酸检测系统出现异常,导致用户无法登录。当日16时起,贵州省核酸检测系统逐步恢复。云上贵州大数据公司发布信息表示歉意,并将以此为鉴,全力改进工作。

顶象业务安全专家认为,核酸检测系统崩溃的技术原因很多,网络带宽、云服务稳定性和资源扩展性、应用系设计、数据库性能以及运维能力都可能影响系统服务。“用户最能直观感受到的一个服务节点。当服务页面出问题后,最先想到的就是应用系统,其实像网络带宽、负载均衡、CDN、数据库性能、运维系统等基础设施和运维能力,都会影响到用户的直接体验。”
顶象业务安全专家建议,应用上线前,企业和单位需要做好应用的容量评估和规划、性能压测以及全链路压测,并制定好故障应急处理流程机制。同时,在运维服务上,尽量选择原厂背后的研发和架构团队做支持。
核酸检测系统的加载过程
成都、贵州等地核酸检测系统频陷崩溃,背后的技术原因会有多种可能。因为应用系统上线运行后,影响系统性能的环节会非常的多。从技术视角看,用户的一个url请求到后台服务,中间要经过多个环节,过程非常复杂。
1、请求发起。浏览器发起url请求、DNS解析、和服务端建立TCP链接、HTTPS协议认证、压缩数据并进行网络传输、接收到结构进行页面渲染
2、网络传输。网络节点路由、数据包封包/拆包、安全防火墙规则和限制、负载均衡/代理服务
3、系统服务。身份验证/权限控制、业务系统、其他依赖的各类应用服务
4、数据存储。缓存、数据库、消息队列、文件等。
可以看到,用户的请求要到达业务系统要经过多个环节,每一个环节都涉及性能上的问题,每一个环节又都有各自可优化的点。
例如,前端发起请求的优化,从浏览器发起url请求,涉及浏览器对域名请求并发数限制、js/css/图片等请求文件大小、请求内容的CDN加速、请求内容的浏览器缓存等。现在大多浏览器都自带开发者诊断工具,可以有针对性的去做性能定位,下图展示了用户的请求情况和单个请求的timing耗时。
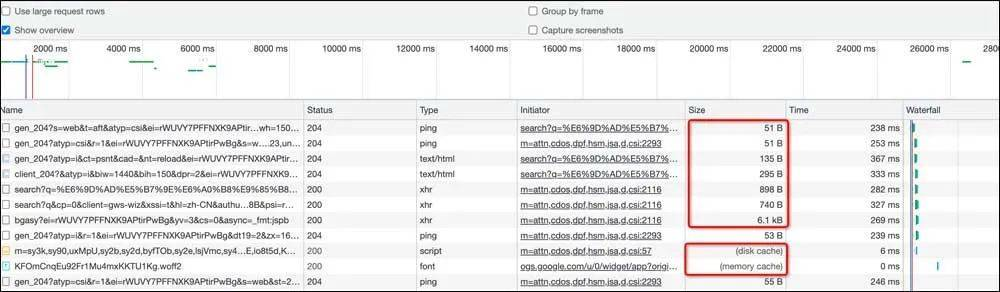
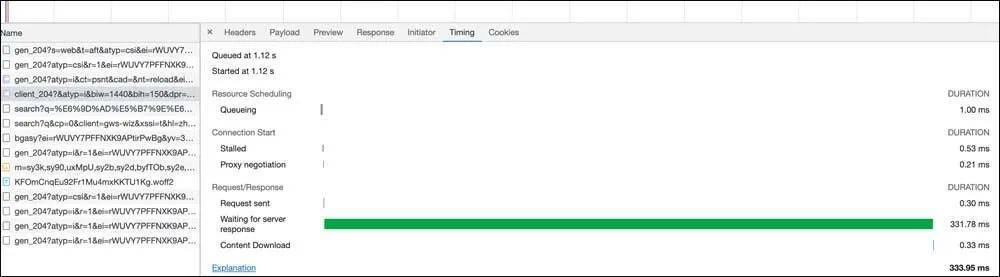
核酸检测系统“崩溃”的技术原因分析
上面提到的四个流程环节都涉及性能优化,每个环节的快与慢都可能影响到用户的直接体验。核酸检测应用系统出现访问慢、崩溃等情况,可以在以下几方面查找原因。
1、网络带宽。可以类比请求数据传输的高速公路,碰到国庆/春节假期高速免费通行,就可能出现堵车的情况,影响出行速度。对应用系统来说,用户访问量激增,如果网络带宽不够,也会出现网络拥堵,影响页面的加载速度,表现出来的就是页面加载不出来或页面加载出错。
2、云服务平台/基础设施的稳定性和性能。现在云计算服务大范围普及,应用都运行在公有云或私有云上,会使用到云服务器、负载均衡、CDN、云存储、流量带宽等云服务。云服务平台作为基础设施的提供方,提升了应用开发部署和运维的效率和降低了运营成本。
一方面,云服务提供方要保障基础设施的稳定性,基础设施出现问题,会影响的业务系统的稳定性;另一方面,云服务使用方也要合理地采购云服务资源,避免资源不足影响业务系统的正常使用。
3、应用系统自身设计和性能。系统的设计的大框架,决定了应用系统的性能和稳定性。例如,技术上调侃的二维码扫描,如果请求响应传输的就是二维码图片,这种设计就必然限制了接口的性能(一般传输文本即可,文本的数据报文大小远远小于图片)。还有就是应用的部署结构,分布式集群部署的稳定性必然好于单点部署应用,应用系统上线前也要做好性能测试。
4、数据库的性能。数据库的性能会影响到应用系统的性能,应用系统的数据查询、写入会依赖下面的数据库,比如数据库出现慢查询就会导致页面查询变慢。数据库技术比较成熟,一般都会配合缓存使用,提升数据查询的性能。
5、运维系统和能力。运维在应用系统的生命周期中会占到70%以上的时间,高质量的运维系统和服务,能保障应用系统的性能和稳定性。例如故障前的容量管理、预警、巡检、演练、日志管理,故障中的处理机制、oncall、告警、定位和预案执行,故障后的复盘总结、改进措施的落地闭环。相信只有在日常运维上做好了充分的准备,在面对故障问题时才能做到及时快速地处理。
应用系统性能和稳定性能力要求
可以看到,应用系统只是用户最能直观感受到的一个服务节点。页面出问题后,最先想到的就是应用系统,其实像网络带宽、负载均衡、CDN、数据库性能、运维系统等基础设施和运维能力,都会影响到用户的直接体验。
以顶象风控系统(实时决策引擎)为例,看下顶象风控系统在设计和实施时,对系统性能和稳定性上的能力要求(PS:顶象风控系统在性能和稳定性上,支持TPS>5w的集群部署,平均rt<100ms,采用分布式集群部署,支持分钟级系统预警和在线水平扩展)。
设计原则
应用系统的架构设计,要采用分布式设计、集群化部署。
采用微服务架构,无状态设计。
功能内聚,模块化、组件化设计。
面对大流量高并发场景下,要具备一定容错性,有降级保护机制。
动态内容和静态内容分离,静态内容放到CDN,加速访问。
具备可扩展性、可运维性。
部署结构
支持DMZ区、业务区、数据库区、内网区的部署结构,满足网络隔离要求。
支持多机房容灾备份。
支持动态请求代理转发、静态内容CDN托管。
应用系统部署,无状态化,可随时增减节点。
可扩展性
支持配置化、脚本化对接消息队列(kafka、rabbitmq),无需开发,配置即生效。
支持配置化、脚本化对接其他系统api接口,便于在策略中使用。
支持配置化、脚本化对原始业务参数进行转换处理。
支持自定义策略和规则、自定义外部关联数据等各种衍生变量。
日志格式化,支持同步到业务系统或大数据平台。
支持sso对接和二次开发。
支持自定义角色、权限、背景图和LOGO的替换。
支持请求由业务系统路由转发。
可运维性
容器化部署和集群管理,支持快速在线水平扩缩容。
具备系统监控告警功能和机制,对服务器资源、网络状况、API调用、中间件等性能情况进行监控告警。
具备灰度发布功能和机制,分别从应用级、功能级进行灰度发布管理。支持策略灰度上线、上线前进行真实数据试跑和调优。
具备安全管理机制,可针对不同渠道、部门和人员进行权限控制,实现风控策略和运行数据的隔离,并且对策略的变更有版本记录和审核控制。
最后,关于运维,有几点需要特别强调:
1、尽可能采用原厂运维,在运维服务支持上,原厂人员更熟悉,处理技术问题有原厂背后的研发和架构团队支持。
2、上线前评估和压测,任何应用系统上线,都需要做好上线前容量评估和规划(预估请求量和并发量,准备相应机器资源,留足冗余量)、性能压测(稳定性压测和极限压测,为应对短时大并发量做好极限压测,了解系统的性能上限),以及全链路压测(评估整个业务链路上的性能短板)。
3、故障问题处理闭环,定制好故障应急处理机制,从问题预警、进展同步、定位处理,到事后复盘、措施的落地和验证,整个处理闭环做到位,避免问题重复出现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号