深度学习(一)
tf.data 模块
tf.data API 最重要的概念:tf.data.Dataset 表示一系列元素
tf.data.Dataset 中每个元素包含一个或多个 Tensor 对象。
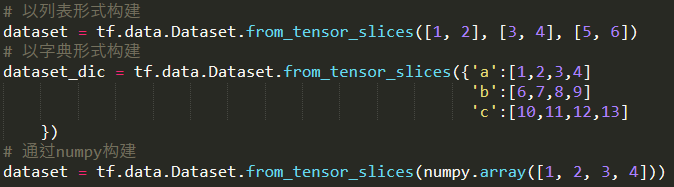
创建 tf.data.Dataset:
1、直接从 Tensor 创建 Dataset
Dataset.from_tensor_slices()
使用 numpy ,TensorFlow 会自动将其转换为 Tensor。
2、通过对一个或多个 tf.data.Dataset 对象来使用变换(Dataset.zip)来创建 Dataset
一个 Dataset 对象包含多个元素,每个元素的结构都是相同的。每个元素包含一个或多个 tf.Tensor 对象,这些对象被称为组件。
Dataset
Dataset 的属性由构成该 Dataset 的元素的属性映射得到,元素可以是单个张量、张量元组,张量的嵌套元组。
直接对 Dataset 进行迭代处理

Dataset 对象,显示内部数据的规格 shape
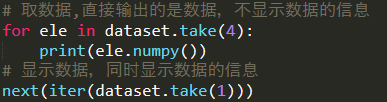
利用 take 可以取出 dataset 中的一部分数据
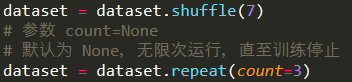
对数据进行乱序操作 shuffle ,避免神经网络记忆数据关系,忽略数据本身

buffer_size 是数据的长度,在乱序的时候可以选择处理数据的多少
设置乱序操作运行的次数 repeat
数据过多,分批次输入到网络中进行训练 batch

使用函数对数据进行变换——map

对不同数据进行读取之后,组合到一起

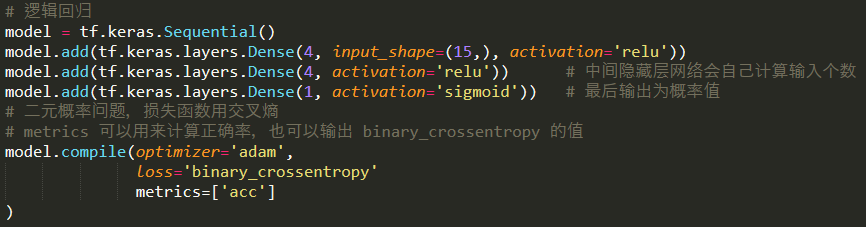
创建网络(多层感知器)

逻辑回归
softmax分类
对数几率回归解决二分类问题,softmax函数可以进行多分类
softmax层可以使神经网络的输出是概率分布。softmax的每一个样本必须属于某一个类别,且所有可能的样本均被覆盖。所有样本分量概率和为 1。只有两类时,与对数几率回归完全相同。
在 tf.keras 里,对于多分类问题使用 categorical_crossentropy 和 sparse_categorical_crossentropy 来计算 softmax 的交叉熵。
label 采用顺序编码时,损失函数用 sparse_categorical_crossentropy
label 采用独热编码时,损失函数用 categorical_crossentropy


过拟合
过拟合:在训练数据上,得分很高,在测试数据上得分相对较低。
欠拟合:在训练数据上,得分较低,在测试数据上得分也低。
添加 dropout 层解决过拟合问题
在训练时,认为丢弃一些神经元,在测试的时候,所有神经元都参与。
dropout 作用:取平均作用、减少神经元之间复杂的共适应关系。

参数选择原则:
首先开发一个过拟合模型:
1、添加更多的层
2、让每一层变得更大
3、训练更多的轮次
抑制过拟合:
1、dropout
2、正则化
3、图像增强
增加训练数据是最佳的抑制过拟合的方法
调节参数:学习速率、隐藏单元数、训练轮次
构建网络的总原则:保证神经网络容量足够拟合数据
1、增大网络容量,直到过拟合
2、采取措施抑制过拟合
3、继续增大网络容量,直到过拟合

 浙公网安备 33010602011771号
浙公网安备 33010602011771号