

Redis主从哨兵集群
Redis主从架构
配置主从复制 12 replicaof 192.168.0.60 6379 # 从本机6379的redis实例复制数据,Redis 5.0之前使用slaveof 13 replica‐read‐only yes # 配置从节点只读
Redis主从工作原理
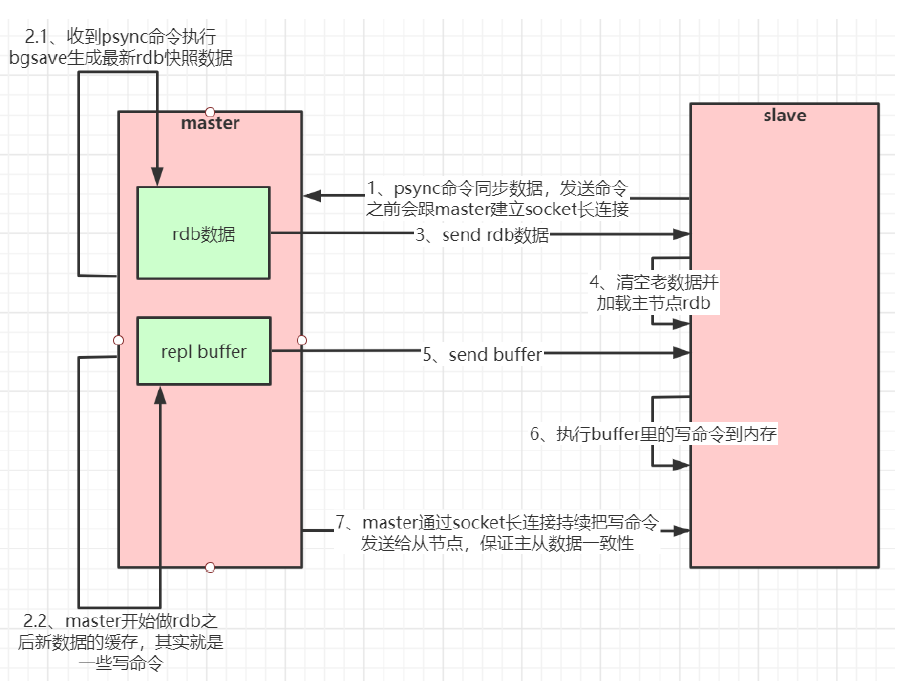
如果你为master配置了一个slave,不管这个slave是否是第一次连接上Master,它都会发送一个PSYNC
命令给master请求复制数据。
master收到PSYNC命令后,会在后台进行数据持久化通过bgsave生成最新的rdb快照文件,持久化期
间,master会继续接收客户端的请求,它会把这些可能修改数据集的请求缓存在内存中。当持久化进行完
毕以后,master会把这份rdb文件数据集发送给slave,slave会把接收到的数据进行持久化生成rdb,然后
再加载到内存中。然后,master再将之前缓存在内存中的命令发送给slave。
当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多
个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送
给多个并发连接的slave。
此后,master每次执行一个写命令都会同步发送给slave,保持master与slave之间数据的一致性
主从复制(全量复制)流程图:
数据部分复制
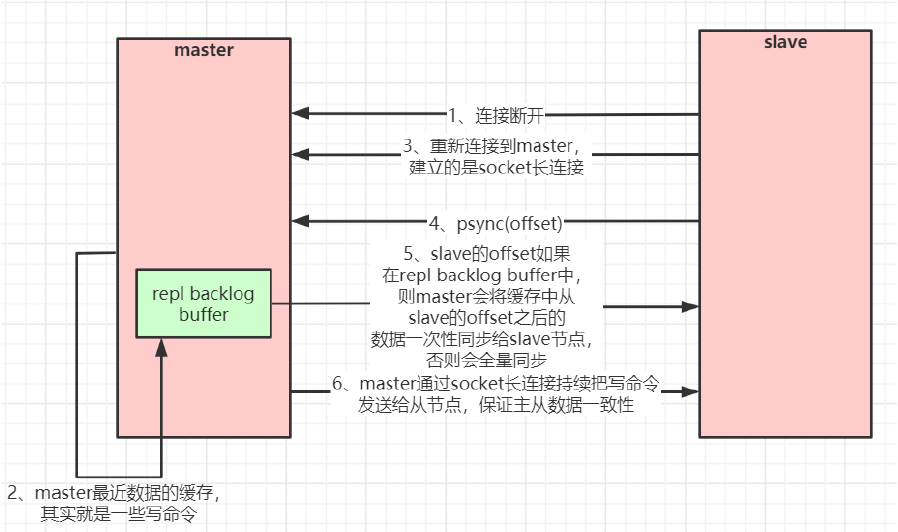
当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支
持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分
数据复制(断点续传)。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的
slave都维护了复制的数据下标offset和master的进程id,因此,当网络连接断开后,slave会请求master
继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标
offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
主从复制(部分复制,断点续传)流程图:
redis哨兵模式
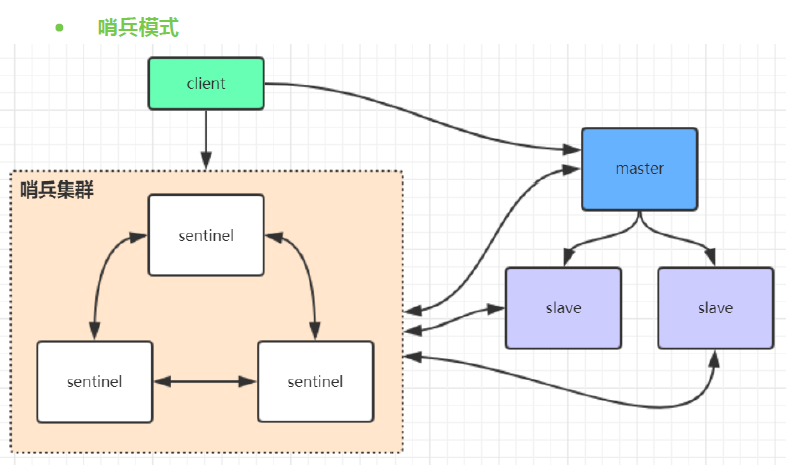
在redis3.0以前的版本要实现集群一般是借助哨兵sentinel工具来监控master节点的状态,如果master节点异
常,则会做主从切换,将某一台slave作为master,哨兵的配置略微复杂,并且性能和高可用性等各方面表现
一般,特别是在主从切换的瞬间存在访问瞬断的情况,而且哨兵模式只有一个主节点对外提供服务,没法支持
很高的并发,且单个主节点内存也不宜设置得过大,否则会导致持久化文件过大,影响数据恢复或主从同步的
效率
哨兵机制分为三个阶段:
1、监控。哨兵进程会周期给所有的主库、从库发送 PING 命令,检测机器是否处于服务状态。如果没有在设置时间内收到回复,则判定为下线。
2、选主。主要是看各个节点的打分情况,打分规则分为 从库优先级、从库复制进度、从库ID号。只要有一轮,某个从库得分最高,则选举它为主库。
- 从库优先级,主要是考虑到不同的机器可能配置不一样,配置高的机器,优先级高一些,通过
slave-priority来配置 - 从库复制进度,主要是看
slave_repl_offset的值大小,值越大表示已经同步的数据越多,得分越高。 - 从库ID号,每个Redis 实例启动时,都会生成一个 ID,在优先级和复制进度相同的条件下,ID号最小的从库分数最高,会被选为新主库。
3、通知。把选举后的新主库发送给所有节点,让所有的从库执行 replicaof 命令,和新 master建立主从关系、数据同步复制。另外,也会把最新的主库信息同步给客户端。这样后续的写请求会打到新的 主节点上。
网络抖动,引发误判
哨兵节点监控到主节点超时未响应,主节点不一定是真的宕机。可能是之间的网络拥堵,或者主库自身压力过大,导致响应超时。
如何避免这种情况?
引入哨兵集群,多个哨兵实例一起判断,降低误判率。判断标准就是,假如 n 个哨兵实例,至少有 n/2+1 个判定一致,才可以定论
哨兵如何知道所有从库地址呢?
我们知道每个哨兵实例的配置参数里有配置主库的ip和port,而每个主库要同步数据给从库,自然有挂载的所有从库信息。
所以,哨兵实例只需向主库发送INFO命令即可获取到所需要的信息,然后哨兵实例在依次与从库建立连接。
至此,一个哨兵实例便可以收集到整个Redis 集群的数据,包含三块:
- 所有的哨兵节点ip、port
- 主节点ip、port
- 主节点挂载的所有从节点的 ip、port
其他哨兵实例也是一样道理,这里就不在赘述了。
哨兵是个集群,如何选哨兵Leader?
当一个哨兵实例监控到主库”主观下线“后,给其他实例发送 is-master-down-by-addr 命令,其他哨兵实例根据自己与主库的连接情况,做出 Y 或 N的回复。
当这个哨兵收集到了超过 quorum 配置项的 Y 回复后,就会标记主库”客观下线“。
当一个哨兵实例收到超过 设置的quorum 票Y后,它会成为新的Leader。然后由它(哨兵S3)负责后面的从库选主,通知从库与新主库建立关系并同步数据,通知客户端访问新主库。
如果本轮没有选出Leader节点,等哨兵故障转移超时时间的 2 倍时间后,重新发起新一轮选举。
为了保证哨兵Leader选举的顺利进行,除了对网络质量有要求外,最好配置奇数个哨兵节点且最好三个以上。
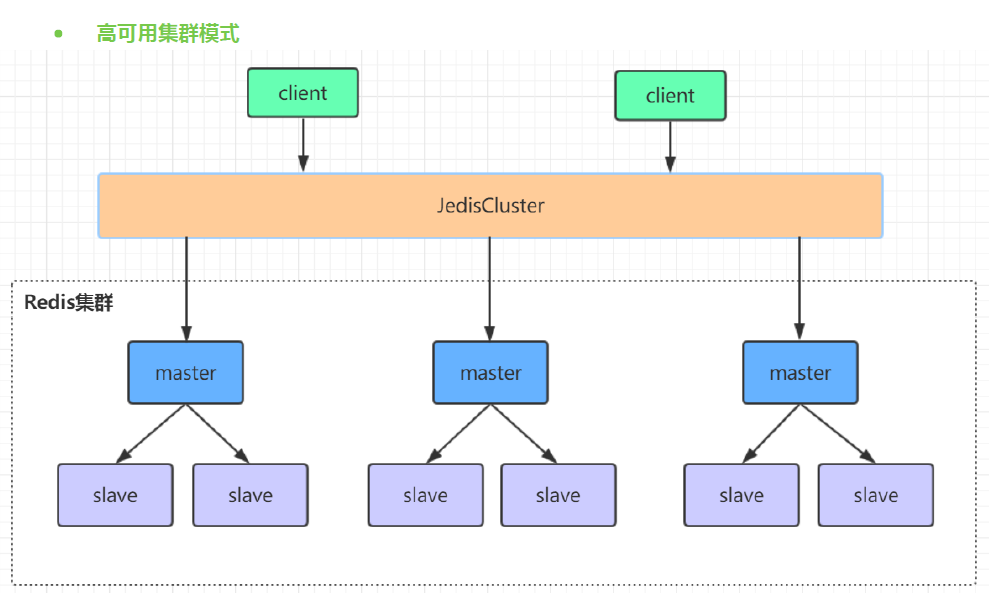
高可用集群模式
Redis集群选举原理分析
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master。由于挂掉的master
可能会有多个slave,从而存在多个slave竞争成为master节点的过程, 其过程如下:
1.slave发现自己的master变为FAIL
2.将自己记录的集群currentEpoch加1,并广播FAILOVER_AUTH_REQUEST 信息
3.其他节点收到该信息,只有master响应,判断请求者的合法性,并发送FAILOVER_AUTH_ACK,对每一个
epoch只发送一次ack
4.尝试failover的slave收集master返回的FAILOVER_AUTH_ACK
5.slave收到超过半数master的ack后变成新Master(这里解释了集群为什么至少需要三个主节点,如果只有两
个,当其中一个挂了,只剩一个主节点是不能选举成功的)
6.slave广播Pong消息通知其他集群节点。
从节点并不是在主节点一进入 FAIL 状态就马上尝试发起选举,而是有一定延迟,一定的延迟确保我们等待
FAIL状态在集群中传播,slave如果立即尝试选举,其它masters或许尚未意识到FAIL状态,可能会拒绝投票
•延迟计算公式:
DELAY = 500ms + random(0 ~ 500ms) + SLAVE_RANK * 1000ms
•SLAVE_RANK表示此slave已经从master复制数据的总量的rank。Rank越小代表已复制的数据越新。这种方
式下,持有最新数据的slave将会首先发起选举(理论上)。
集群脑裂数据丢失问题
redis集群没有过半机制会有脑裂问题,网络分区导致脑裂后多个主节点对外提供写服务,一旦网络分区恢复,
会将其中一个主节点变为从节点,这时会有大量数据丢失。
规避方法可以在redis配置里加上参数(这种方法不可能百分百避免数据丢失,参考集群leader选举机制):
1 min‐replicas‐to‐write 1 //写数据成功最少同步的slave数量,这个数量可以模仿大于半数机制配置,比如 集群总共三个节点可以配置1,加上leader就是2,超过了半数
注意:这个配置在一定程度上会影响集群的可用性,比如slave要是少于1个,这个集群就算leader正常也不能
提供服务了,需要具体场景权衡选择。
哨兵leader选举流程
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进
行故障转移工作。每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的
leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一
个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移
操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。
哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨
兵节点就是哨兵leader了,可以正常选举新master。
Redis集群节点间的通信机制
redis cluster节点间采取gossip协议进行通信
维护集群的元数据(集群节点信息,主从角色,节点数量,各节点共享的数据等)有两种方式:集中
式和gossip
集中式:
优点在于元数据的更新和读取,时效性非常好,一旦元数据出现变更立即就会更新到集中式的存储中,其他节
点读取的时候立即就可以立即感知到;不足在于所有的元数据的更新压力全部集中在一个地方,可能导致元数
据的存储压力。 很多中间件都会借助zookeeper集中式存储元数据。
gossip:
gossip协议包含多种消息,包括ping,pong,meet,fail等等。
meet:某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通
信;
ping:每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据,互相通过
ping交换元数据(类似自己感知到的集群节点增加和移除,hash slot信息等);
pong: 对ping和meet消息的返回,包含自己的状态和其他信息,也可以用于信息广播和更新;
fail: 某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
gossip协议的优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上
去更新,有一定的延时,降低了压力;缺点在于元数据更新有延时可能导致集群的一些操作会有一些滞后。
gossip通信的10000端口
每个节点都有一个专门用于节点间gossip通信的端口,就是自己提供服务的端口号+10000,比如7001,那么
用于节点间通信的就是17001端口。 每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他几
点接收到ping消息之后返回pong消息。
网络抖动
真实世界的机房网络往往并不是风平浪静的,它们经常会发生各种各样的小问题。比如网络抖动就是非常常见
的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。
为解决这种问题,Redis Cluster 提供了一种选项clusternodetimeout,
表示当某个节点持续 timeout
的时间失联时,才可以认定该节点出现故障,需要进行主从切换。如果没有这个选项,网络抖动会导致主从频
繁切换 (数据的重新复制)。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)