

序列化
https://mp.weixin.qq.com/s/s-ih7FDbjwXXBAlfEZs7TQ
https://baijiahao.baidu.com/s?id=1633305649182361563&wfr=spider&for=pc
- 序列化是指将对象实例的状态存到存储媒体的过程
- 反序列化是指将存储在存储媒体中的对象状态装换成对象的过程
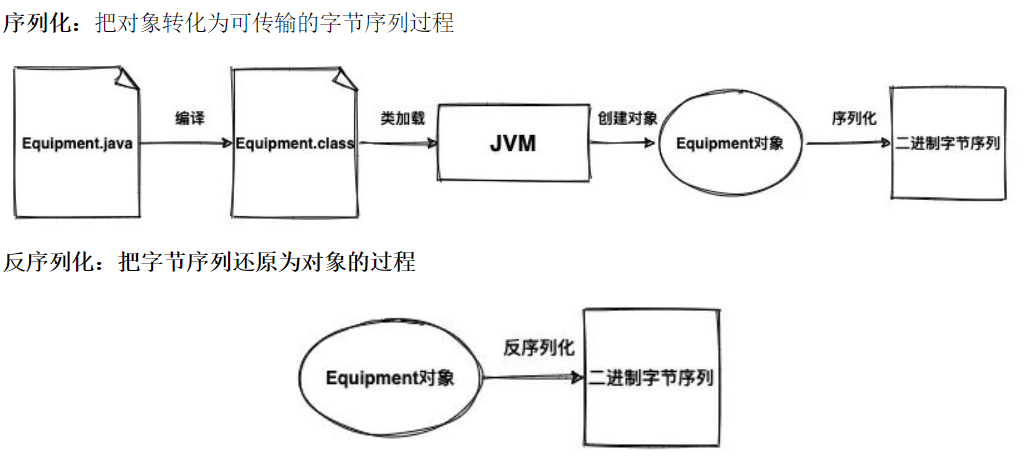
序列化的机制
序列化最终的目的是为了对象可以跨平台存储和进行网络传输,而我们进行跨平台存储和网络传输的方式就是 IO,而 IO 支持的数据格式就是字节数组。
那现在的问题就是如何把对象转换成字节数组?这个很好办,一般的编程语言都有这个能力,可以很容易将对象转成字节数组。
仔细一想,我们单方面的把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,简单说就是将对象转成字节数组容易但是将字节数组还原成对象就难了,所以我们必须在把对象转成字节数组的时候就制定一种规则(序列化),那么我们从 IO 流里面读出数据的时候再以这种规则把对象还原回来(反序列化)。
还是拿上面游戏那个例子,我们将正在玩的游戏存档到硬盘,序列化就是将一个个角色对象和装备对象存储到硬盘,然后留下一张原来对象的结构图纸,反序列化就是将硬盘里一个个对象读出来照着图纸逐个还原恢复。
常见序列化的方式
序列化只是定义了拆解对象的具体规则,那这种规则肯定也是多种多样的,比如现在常见的序列化方式有:JDK 原生、JSON、ProtoBuf、Hessian、Kryo等。
(1)JDK 原生
作为一个成熟的编程语言,JDK自带了序列化方法。只需要类实现了Serializable接口,就可以通过ObjectOutputStream类将对象变成byte[]字节数组。
JDK 序列化会把对象类的描述信息和所有的属性以及继承的元数据都序列化为字节流,所以会导致生成的字节流相对比较大。
另外,这种序列化方式是 JDK 自带的,因此不支持跨语言。
简单总结一下:JDK 原生的序列化方式生成的字节流比较大,也不支持跨语言,因此在实际项目和框架中用的都比较少。
(2)ProtoBuf
谷歌推出的,是一种语言无关、平台无关、可扩展的序列化结构数据的方法,它可用于通信协议、数据存储等。序列化后体积小,一般用于对传输性能有较高要求的系统。
(4)Hessian
Hessian 是一个轻量级的二进制 web service 协议,主要用于传输二进制数据。
在传输数据前 Hessian 支持将对象序列化成二进制流,相对于 JDK 原生序列化,Hessian序列化之后体积更小,性能更优。
(5)Kryo
Kryo 是一个 Java 序列化框架,号称 Java 最快的序列化框架。Kryo 在序列化速度上很有优势,底层依赖于字节码生成机制。
由于只能限定在 JVM 语言上,所以 Kryo 不支持跨语言使用。
(6)JSON
上面讲的几种序列化方式都是直接将对象变成二进制,也就是byte[]字节数组,这些方式都可以叫二进制方式。
JSON 序列化方式生成的是一串有规则的字符串,在可读性上要优于上面几种方式,但是在体积上就没什么优势了。
另外 JSON 是有规则的字符串,不跟任何编程语言绑定,天然上就具备了跨平台。
总结一下:JSON 可读性强,支持跨平台,体积稍微逊色。
JSON 序列化常见的框架有:
fastJSON、Jackson、Gson 等。
序列化技术的选型
上面列举的这些序列化技术各有优缺点,不能简单地说哪一种就是最好的,不然也不会有这么多序列化技术共存了。
既然有这么多序列化技术可供选择,那在实际项目中如何选型呢?
我认为需要结合具体的项目来看,比较技术是服务于业务的。你可以从下面这几个因素来考虑:
(1)协议是否支持跨平台
如果一个大的系统有好多种语言进行混合开发,那么就肯定不适合用有语言局限性的序列化协议,比如 JDK 原生、Kryo 这些只能用在 Java 语言范围下,你用 JDK 原生方式进行序列化,用其他语言是无法反序列化的。
(2)序列化的速度
如果序列化的频率非常高,那么选择序列化速度快的协议会为你的系统性能提升不少。
(3)序列化生成的体积
如果频繁的在网络中传输的数据那就需要数据越小越好,小的数据传输快,也不占带宽,也能整体提升系统的性能,因此序列化生成的体积就很关键了。
我们来看看Serializable到底是什么,跟进去看一下,我们发现Serializable接口里面竟然什么都没有,只是个空接口。
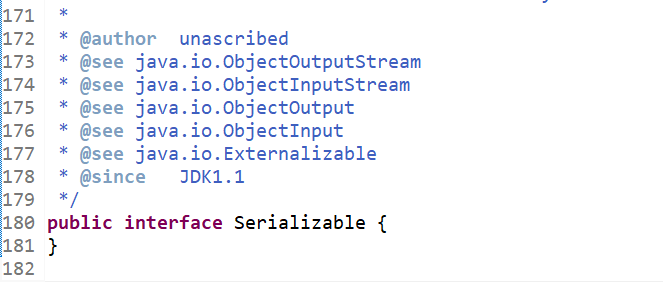
一个接口里面什么内容都没有,我们可以将它理解成一个标识接口。
在Java中的这个Serializable接口其实是给jvm看的,通知jvm,我不对这个类做序列化了,你(jvm)帮我序列化就好了。
Serializable接口就是Java提供用来进行高效率的异地共享实例对象的机制,实现这个接口即可。
为什么要定义serialversionUID变量
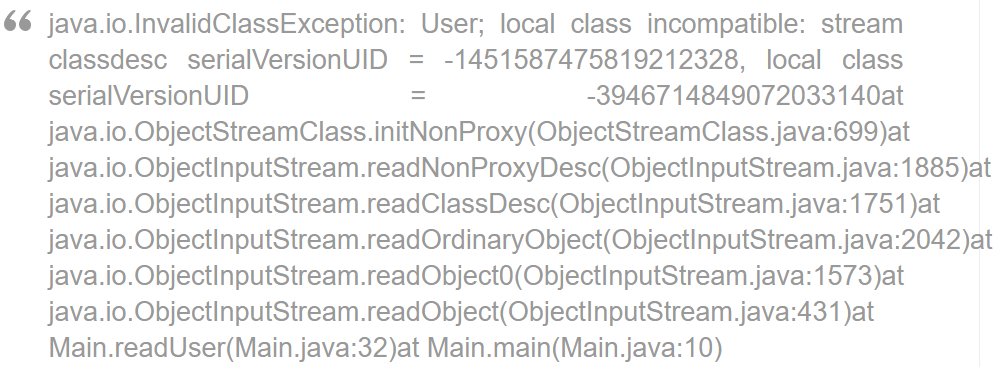
从说明中我们可以看到,如果我们没有自己声明一个serialVersionUID变量,接口会默认生成一个serialVersionUID,但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常。
serialVersionUID的详细的工作机制是:在序列化的时候系统将serialVersionUID写入到序列化的文件中去,当反序列化的时候系统会先去检测文件中的serialVersionUID是否跟当前的文件的serialVersionUID是否一致,如果一直则反序列化成功,否则就说明当前类跟序列化后的类发生了变化,比如是成员变量的数量或者是类型发生了变化,那么在反序列化时就会发生crash,并且回报出错误:
显式定义serialVersionUID主要有两种用途:
- 在某些场合,希望类的不同版本对序列化兼容,故需确保类的不同版本具有相同的serialVersionUID;
- 在某些场合,不希望类的不同版本对序列化兼容,因此需要确保类的不同版本具有不同的serialVersionUID。
序列化为什么可以实现深拷贝?
答:若一个对象的属性引用其他对象,则序列化该对象时引用对象也会同时被序列化,这即是序列化能够实现深拷贝的本质。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)