

死磕Spring之Spring 的 Bean 生命周期
https://www.jianshu.com/p/6d968c10a580
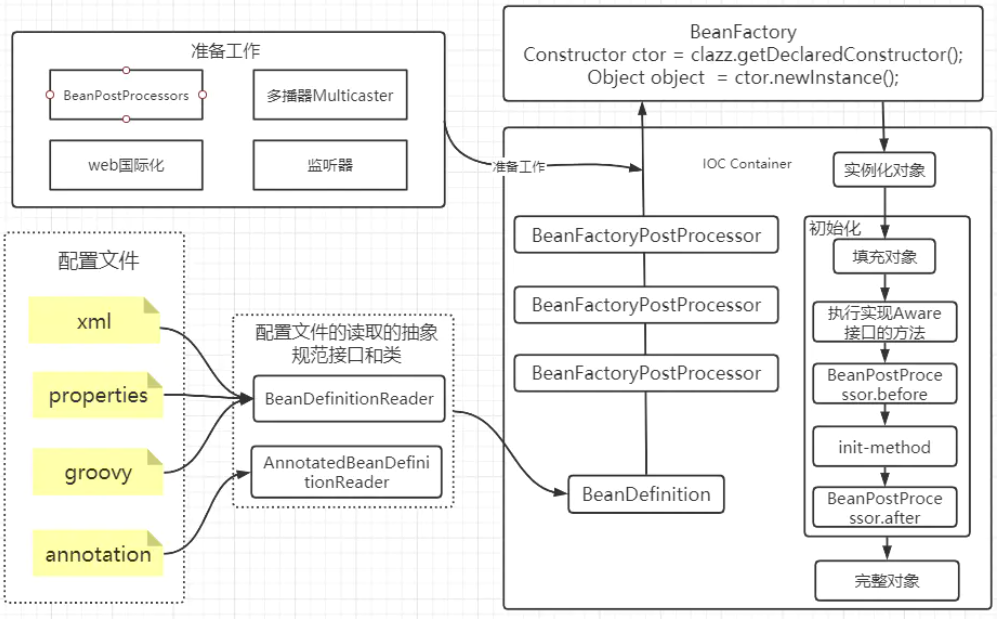
Spring在启动的时候需要「扫描」在XML/注解/JavaConfig 中需要被Spring管理的Bean信息,将这些信息封装成BeanDefinition,最后会把这些信息放到一个beanDefinitionMap中。
这个Map的key应该是beanName,value则是BeanDefinition对象。
接着会遍历这个beanDefinitionMap,执行BeanFactoryPostProcessor这个Bean工厂后置处理器的逻辑。
比如说,我们平时定义的占位符信息,就是通过BeanFactoryPostProcessor的子类PropertyPlaceholderConfigurer进行注入进去。
这里我们也可以自定义BeanFactoryPostProcessor来对我们定义好的Bean元数据进行获取或者修改
BeanFactoryPostProcessor后置处理器执行完了以后,就到了实例化对象啦
在Spring里边是通过反射来实现的,一般情况下会通过反射选择合适的构造器来把对象实例化
但这里把对象实例化,只是把对象给创建出来,而对象具体的属性是还没注入的。
相关属性注入完之后,往下接着就是初始化的工作了
首先判断该Bean是否实现了Aware相关的接口
Aware相关的接口处理完之后,就会到BeanPostProcessor后置处理器啦
BeanPostProcessor相关子类的before方法执行完,则执行init相关的方法,比如说@PostConstruct、实现了InitializingBean接口、定义的init-method方法
他们的被调用「执行顺序」分别是:@PostConstruct、实现了InitializingBean接口以及init-method方法
这些都是Spring给我们的「扩展」,像@PostConstruct我就经常用到
比如说:对象实例化后,我要做些初始化的相关工作或者就启个线程去Kafka拉取数据
等到init方法执行完之后,就会执行BeanPostProcessor的after方法
https://blog.csdn.net/Java_3y/article/details/119871652
Spring上下文中的Bean生命周期也类似,如下:
(1)实例化Bean:
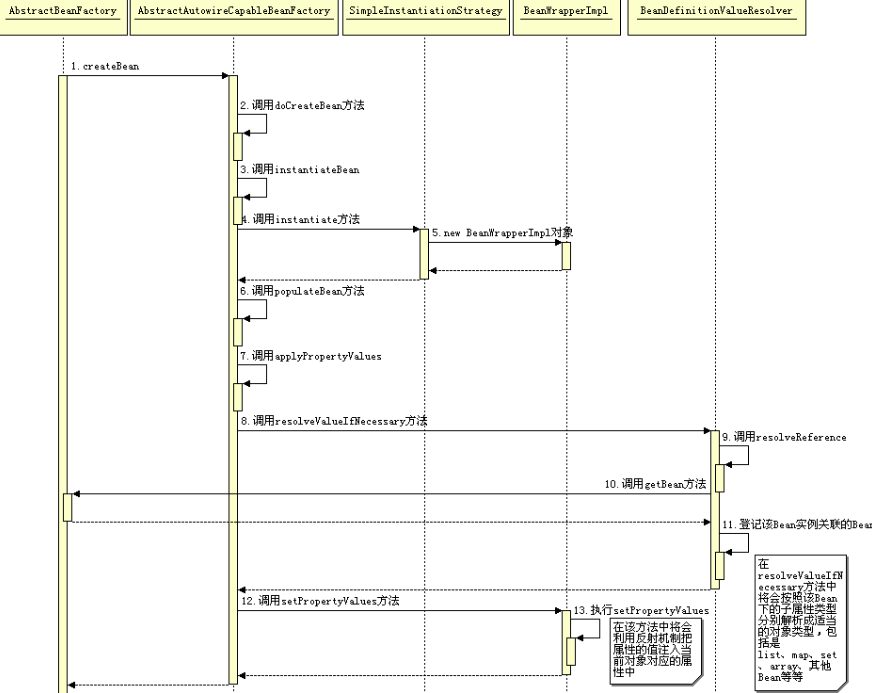
对于BeanFactory容器,当客户向容器请求一个尚未初始化的bean时,或初始化bean的时候需要注入另一个尚未初始化的依赖时,容器就会调用createBean进行实例化。
对于ApplicationContext容器,当容器启动结束后,通过获取BeanDefinition对象中的信息,实例化所有的bean。
(2)设置对象属性(依赖注入):
实例化后的对象被封装在BeanWrapper对象中,紧接着,Spring根据BeanDefinition中的信息 以及 通过BeanWrapper提供的设置属性的接口完成依赖注入。
(3)处理Aware接口:
接着,Spring会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean:
①如果这个Bean已经实现了BeanNameAware接口,会调用它实现的setBeanName(String beanId)方法,此处传递的就是Spring配置文件中Bean的id值;
②如果这个Bean已经实现了BeanFactoryAware接口,会调用它实现的setBeanFactory()方法,传递的是Spring工厂自身。
③如果这个Bean已经实现了ApplicationContextAware接口,会调用setApplicationContext(ApplicationContext)方法,传入Spring上下文;
(4)BeanPostProcessor:
如果想对Bean进行一些自定义的处理,那么可以让Bean实现了BeanPostProcessor接口,那将会调用postProcessBeforeInitialization(Object obj, String s)方法。由于这个方法是在Bean初始化结束时调用的,所以可以被应用于内存或缓存技术;
(5)InitializingBean 与 init-method:
如果Bean在Spring配置文件中配置了 init-method 属性,则会自动调用其配置的初始化方法。
(6)如果这个Bean实现了BeanPostProcessor接口,将会调用postProcessAfterInitialization(Object obj, String s)方法;
以上几个步骤完成后,Bean就已经被正确创建了,之后就可以使用这个Bean了。
(7)DisposableBean:
当Bean不再需要时,会经过清理阶段,如果Bean实现了DisposableBean这个接口,会调用其实现的destroy()方法;
(8)destroy-method:
最后,如果这个Bean的Spring配置中配置了destroy-method属性,会自动调用其配置的销毁方法。
https://www.jianshu.com/p/1dec08d290c1
https://blog.csdn.net/qq_29899535/article/details/122239512
Spring中bean的加载过程?
首先从大的几个核心步骤来去说明,因为Spring中的具体加载过程和用到的类实在是太多了。
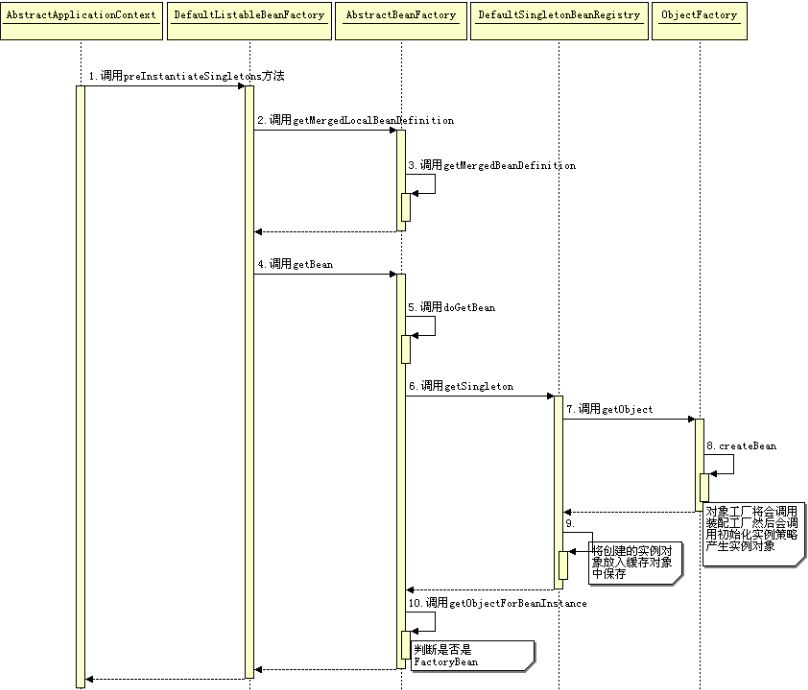
(1)、首先是先从AbstractBeanFactory中去调用doGetBean(name, requiredType, final Object[] args, boolean typeCheckOnly【这个是判断进行创建bean还是仅仅用来做类型检查】)方法,然后第一步要做的就是先去对传入的参数name进行做转换,因为有可能传进来的name=“&XXX”之类,需要去除&符号
(2)、然后接着是去调用getSingleton()方法,其实在上一个面试题中已经提到了这个方法,这个方法就是利用“三级缓存” 来去避免循环依赖问题的出现的。【这里补充一下,只有在是单例的情况下才会去解决循环依赖问题】
(3)、对从缓存中拿到的bean其实是最原始的bean,还未长大,所以这里还需要调用getObjectForBeanInstance(Object beanInstance, String name, String beanName, RootBeanDefinition mbd)方法去进行实例化。
(4)、然后会解决单例情况下尝试去解决循环依赖,如果isPrototypeCurrentlyInCreation(beanName)返回为true的话,会继续下一步,否则throw new BeanCurrentlyInCreationException(beanName);
(5)、因为第三步中缓存中如果没有数据的话,就直接去parentBeanFactory中去获取bean,然后判断containsBeanDefinition(beanName)中去检查已加载的XML文件中是否包含有这样的bean存在,不存在的话递归去getBean()获取,如果没有继续下一步
(6)、这一步是吧存储在XML配置文件中的GernericBeanDifinition转换为RootBeanDifinition对象。这里主要进行一个转换,如果父类的bean不为空的话,会一并合并父类的属性
(7)、这一步核心就是需要跟这个Bean有关的所有依赖的bean都要被加载进来,通过刚刚的那个RootBeanDifinition对象去拿到所有的beanName,然后通过registerDependentBean(dependsOnBean, beanName)注册bean的依赖
(8)、然后这一步就是会根据我们在定义bean的作用域的时候定义的作用域是什么,然后进行判断在进行不同的策略进行创建(比如isSingleton、isPrototype)
(9)、这个是最后一步的类型装换,会去检查根据需要的类型是否符合bean的实际类型去做一个类型转换。Spring中提供了许多的类型转换器。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)