

volatile
volatile是轻量级的synchronized,如果volatile变量修饰符使用恰当,它比synchronized的使用和执行成本更低,因为它不会引起线程上下文的切换(线程间的保存到再加载)和调度。
内存可见性
多线程操作的时候,一个线程修改了一个变量的值 ,其他线程能立即看到修改后的值。
防止重排序
即程序的执行顺序按照代码的顺序执行(处理器为了提高代码的执行效率可能会对代码进行重排序)。
Volatile可见性的原理
在x86处理器下通过工具获取JIT编译器生成的汇编指令来看看对Volatile进行写操作CPU会做什么事情。

有volatile变量修饰的共享变量进行写操作的时候会多出第二行汇编代码。
Lock前缀的指令在多核处理器下会引发两件事:
1)将当前处理器缓存行的数据写回系统内存;
2)这个写回内存的操作会使得其他CPU里缓存了该内存地址的数据无效。
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存(L1、L2或其他)后再进行操作,但操作完不知道何时会写到内存。
如果对声明了volatile的变量进行写操作,JVM就会向处理器发送一条lock前缀的指令,将这个变量所在缓存行的数据写回到系统内存。在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存值是不是过期,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
第一点的实现:lock信号一般不锁总线,而是锁缓存,毕竟锁总线开销的比较大。如果访问的内存区域没有缓存在处理器内部,它会锁定这块内存区域的缓存并回写到内存,并使用缓存一致性机制来确保修改的原子性,此操作被称为“缓存锁定”,缓存一致性机制会阻止同时修改由两个以上处理器缓存的内存区域数据。
第二点的实现:IA-32 CPU和 Intel 64 CPU使用 MESI(修改、独占、共享、无效)控制协议去维护内部缓存和其他处理器缓存的一致性,避免在总线加lock锁。CPU使用嗅探技术保证它的内部缓存、系统内存和其他处理器的缓存的数据在总线上保持一致。具体解决思路为:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,那么他会发出信号通知其他CPU将该变量的缓存行设置为无效状态。当其他CPU使用这个变量时,首先会去嗅探是否有对该变量更改的信号,当发现这个变量的缓存行已经无效时,会重新从内存中读取这个变量。
Volatile保证有序性的原理
为了性能优化,JVM会在不改变数据依赖性的情况下,允许编译器和处理器对指令序列进行重排序,而有序性问题指的就是程序代码执行的顺序与程序员编写程序的顺序不一致,导致程序结果不正确的问题。而加了volatile修饰的共享变量,则通过内存屏障解决了多线程下有序性问题。
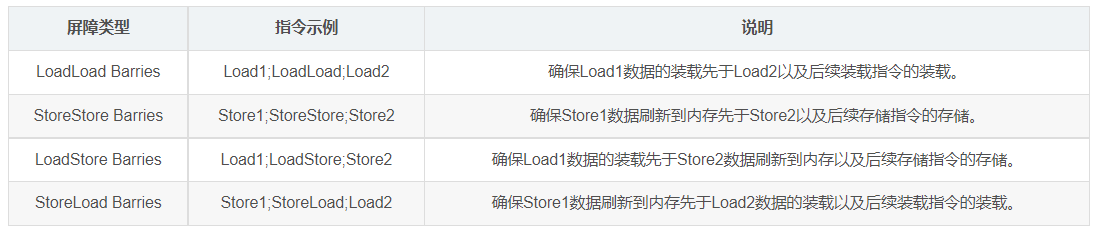
内存屏障分为以下四类:
注:下述Load代表读操作,Store代表写操作
编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
编译器选择了⼀个⽐较保守的JMM内存屏障插⼊策略,这样可以保证在任何处理器平台,任何程序中都能得到正确的volatile内存语义。这个策略是:
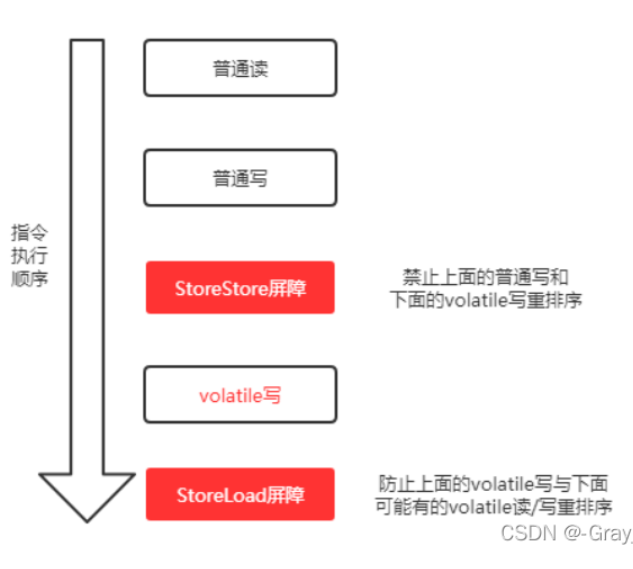
*在每个volatile写操作的前面插入一个StoreStore屏障,禁止StoreStore屏障前面的普通写操作和volatile写操作重排序。
* 在每个volatile写操作的后面插入一个StoreLoad屏障,禁止StoreLoad屏障后面可能有的读操作和volatile写操作重排序。
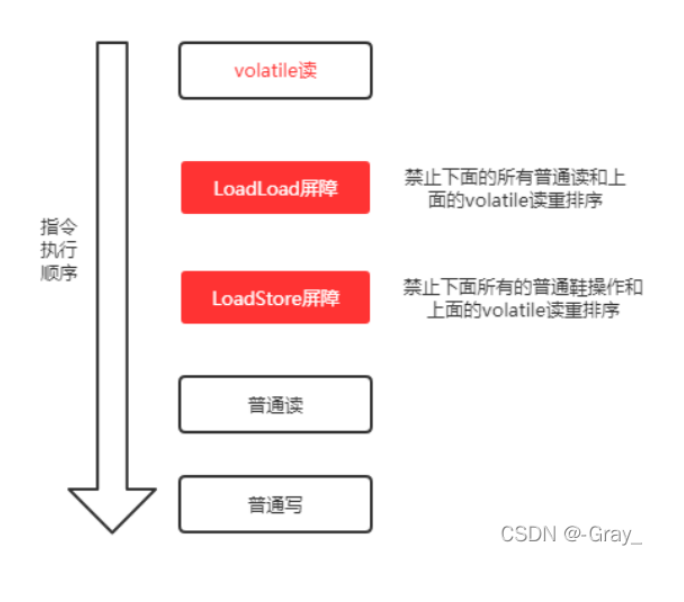
* 在每个volatile读操作的后面插入一个LoadLoad屏障,禁止volatile读操作和LoadLoad屏障后面的普通读操作重排序。
* 在每个volatile读操作的后面插入一个LoadStore屏障,禁止volatile读操作和LoadStore屏障后面的普通写操作重排序。
volatile的使用
1、防止重排序:
我们从一个最经典的例子来分析重排序问题。大家应该都很熟悉单例模式的实现,而在并发环境下的单例实现方式,我们通常可以采用双重检查加锁(DCL)的方式来实现。其源码如下:

package com.paddx.test.concurrent; public class Singleton { public static volatile Singleton singleton; /** * 构造函数私有,禁止外部实例化 */ private Singleton() {}; public static Singleton getInstance() { if (singleton == null) { synchronized (singleton) { if (singleton == null) { singleton = new Singleton(); } } } return singleton; } }
现在我们分析一下为什么要在变量singleton之间加上volatile关键字。要理解这个问题,先要了解对象的构造过程,实例化一个对象其实可以分为三个步骤:
(1)分配内存空间。
(2)初始化对象。
(3)将内存空间的地址赋值给对应的引用。
但是由于操作系统可以对指令进行重排序,所以上面的过程也可能会变成如下过程:
(1)分配内存空间。
(2)将内存空间的地址赋值给对应的引用。
(3)初始化对象
如果是这个流程,多线程环境下就可能将一个未初始化的对象引用暴露出来,从而导致不可预料的结果。因此,为了防止这个过程的重排序,我们需要将变量设置为volatile类型的变量。
2、实现可见性
可见性问题主要指一个线程修改了共享变量值,而另一个线程却看不到。引起可见性问题的主要原因是每个线程拥有自己的一个高速缓存区——线程工作内存。volatile关键字能有效的解决这个问题,我们看下下面的例子,就可以知道其作用:
package com.paddx.test.concurrent; public class VolatileTest { int a = 1; int b = 2; public void change(){ a = 3; b = a; } public void print(){ System.out.println("b="+b+";a="+a); } public static void main(String[] args) { while (true){ final VolatileTest test = new VolatileTest(); new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } test.change(); } }).start(); new Thread(new Runnable() { @Override public void run() { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } test.print(); } }).start(); } } }
直观上说,这段代码的结果只可能有两种:b=3;a=3 或 b=2;a=1。不过运行上面的代码(可能时间上要长一点),你会发现除了上两种结果之外,还出现了第三种结果:b=3;a=1
为什么会出现b=3;a=1这种结果呢?正常情况下,如果先执行change方法,再执行print方法,输出结果应该为b=3;a=3。相反,如果先执行的print方法,再执行change方法,结果应该是 b=2;a=1。那b=3;a=1的结果是怎么出来的?原因就是第一个线程将值a=3修改后,但是对第二个线程是不可见的,所以才出现这一结果。如果将a和b都改成volatile类型的变量再执行,则再也不会出现b=3;a=1的结果了。
volatile与synchronized的区别
volatile只能修饰实例变量和类变量,而synchronized可以修饰方法,以及代码块。
volatile保证数据的可见性,但是不保证原子性(多线程进行写操作,不保证线程安全);而synchronized是一种排他(互斥)的机制。
volatile用于禁止指令重排序:可以解决单例双重检查对象初始化代码执行乱序问题。
volatile可以看做是轻量版的synchronized,volatile不保证原子性,但是如果是对一个共享变量进行多个线程的赋值,而没有其他的操作,那么就可以用volatile来代替synchronized,因为赋值本身是有原子性的,而volatile又保证了可见性,所以就可以保证线程安全了。
https://blog.csdn.net/bfj11/article/details/123949405


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)