树
为什么需要树这种数据结构
数组存储方式的分析
优点:通过下标方式访问元素,速度快。对于有序数组,还可使用二分查找提高检索速度。
缺点:如果要检索具体某个值,或者插入值(按一定顺序)会整体移动,效率较低 。
链式存储方式的分析
优点:在一定程度上对数组存储方式有优化(比如:插入一个数值节点,只需要将插入节点,链接到链表中即可, 删除效率也很好)。
缺点:在进行检索时,效率仍然较低,比如(检索某个值,需要从头节点开始遍历) 。
树存储方式的分析
能提高数据存储,读取的效率, 比如利用 二叉排序树(Binary Sort Tree),既可以保证数据的检索速度,同时也可以保证数据的插入,删除,修改的速度。
树
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。把它叫做 “树” 是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
特点:
每个节点有零个或多个子节点;
没有父节点的节点称为根节点;
每一个非根节点有且只有一个父节点;
除了根节点外,每个子节点可以分为多个不相交的子树;
二叉树
二叉树是树的特殊一种,具有如下特点:
1、每个结点最多有两颗子树,结点的度最大为2。
2、左子树和右子树是有顺序的,次序不能颠倒。
3、即使某结点只有一个子树,也要区分左右子树。
如果该二叉树的所有叶子节点都在最后一层,并且结点总数= 2^n -1 , n 为层数,则我们称为满二叉树。
如果该二叉树的所有叶子节点都在最后一层或者倒数第二层,而且最后一层的叶子节点在左边连续,倒数第二层的叶子节点在右边连续,我们称为完全二叉树。
二叉树是一种比较有用的折中方案,它添加,删除元素都很快,并且在查找方面也有很多的算法优化,所以,二叉树既有链表的好处,也有数组的好处,是两者的优化方案,在处理大批量的动态数据方面非常有用。
扩展:
二叉树有很多扩展的数据结构,包括平衡二叉树、红黑树、B+树等,这些数据结构二叉树的基础上衍生了很多的功能,在实际应用中广泛用到,例如mysql的数据库索引结构用的就是B+树,还有HashMap的底层源码中用到了红黑树。这些二叉树的功能强大,但算法上比较复杂,想学习的话还是需要花时间去深入的。
二叉树的遍历
前序遍历: 先输出父节点,再遍历左子树和右子树。
中序遍历: 先遍历左子树,再输出父节点,再遍历右子树。
后序遍历: 先遍历左子树,再遍历右子树,最后输出父节点。
小结: 看输出父节点的顺序,就确定是前序,中序还是后序。
平衡二叉树(AVL)
定义:基于二分法的策略提高数据的查找速度的一种二叉树数据结构
特点:
非叶子节点最多拥有两个子节点;
非叶子节值大于左边子节点、小于右边子节点;
树的左右两边的层级数相差不会大于1(左子树和右子树相差);
没有值相等重复的节点;
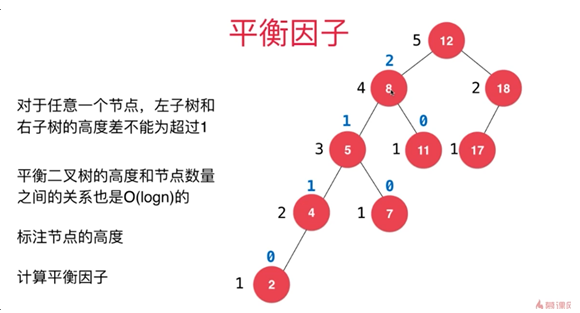
平衡因子:蓝色部分
红黑树
红黑树(Red Black Tree) 是一种自平衡二叉查找树
红黑树和AVL树类似,都是在进行插入和删除操作时通过特定操作保持二叉查找树的平衡,从而获得较高的查找性能。
二叉平衡树的严格平衡策略以牺牲建立查找结构(插入,删除操作)的代价,换来了稳定的O(logN) 的查找时间复杂度
它虽然是复杂的,但它的最坏情况运行时间也是非常良好的,并且在实践中是高效的: 它可以在O(log n)时间内做查找,插入和删除,这里的n 是树中元素的数目。
特点:
(1) 每个节点或者是黑色,或者是红色。
(2) 根节点是黑色。
(3) 每个叶子节点是黑色。 [注意:这里叶子节点,是指为空的叶子节点!]
(4) 如果一个节点是红色的,则它的子节点必须是黑色的。
(5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
红黑树和平衡二叉树区别如下:
1、红黑树放弃了追求完全平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
2、平衡二叉树追求绝对平衡,条件比较苛刻,实现起来比较麻烦,每次插入新节点之后需要旋转的次数不能预知。
一颗平衡二叉树能容纳多少的结点呢?这跟树的高度是有关系的,假设树的高度为h,那每一层最多容纳的结点数量为2^(n-1),整棵树最多容纳节点数为2^0+2^1+2^2+...+2^(h-1)。这样计算,100w数据树的高度大概在20左右,那也就是说从有着100w条数据的平衡二叉树中找一个数据,最坏的情况下需要20次查找。如果是内存操作,效率也是很高的!但是我们数据库中的数据基本都是放在磁盘中的,每读取一个二叉树的结点就是一次磁盘IO,这样我们找一条数据如果要经过20次磁盘的IO?那性能就成了一个很大的问题了!那我们是不是可以把这棵树压缩一下,让每一层能够容纳更多的节点呢?
B树
定义:B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个)
- 排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
- 子节点数:非叶节点的子节点数>1,且<=M (M>=2),空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
- 关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
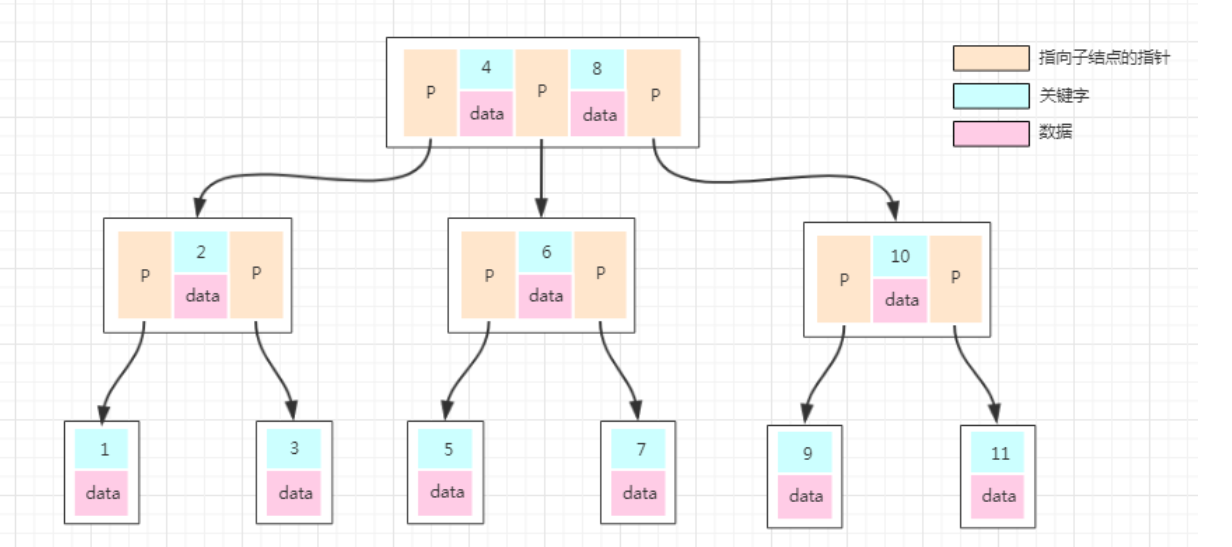
- 所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
数据库的数据都是一条条的数据,如果某个数据库以B-Tree的数据结构存储数据,那数据怎么存放的呢?我们看下一张图
B+树
B+ 树是一种树数据结构,是一个n叉树,每个节点通常有多个孩子,一颗B+树包含根节点、内部节点和叶子节点。
- B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
- B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
如下B+树的数据存放

B和B+树的区别在于,B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
B+ 树的优点在于:
- 由于B+树在内部节点上不好含数据信息,因此在内存页中能够存放更多的key。 数据存放的更加紧密,具有更好的空间局部性。因此访问叶子几点上关联的数据也具有更好的缓存命中率。
- B+树的叶子结点都是相链的,因此对整棵树的便利只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。相邻的元素可能在内存中不相邻,所以缓存命中性没有B+树好。
但是B树也有优点,其优点在于,由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
部分参考
https://www.cnblogs.com/sujing/p/11110292.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号