

Hadoop2.x伪分布式环境搭建(一)
1、安装hadoop环境,以hadoop-2.5.0版本为例,搭建伪分布式环境,所需要工具包提供网盘下载:http://pan.baidu.com/s/1o8HR0Qu
2、上传所需要的工具包到linux相对就应的目录中
3、接上篇(Linux基础环境的各项配置(三)中最后一部分,需卸载系统自带的jdk,以免后续安装的jdk产生冲突),卸载jdk完成后,安装jdk-7u67-linux-x64.tar.gz版本,上述工具包可下载
(1)、解压JDK
tar -zxf jdk-7u67-linux-x64.tar.gz -C ../model/
(2)、配置环境变量,在/etc/profile配置文件末尾加入如下内容(需要管理员权限才能操作此文件)
##JAVA_HOME export JAVA_HOME=/opt/model/jdk1.7.0_67 export PATH=$PATH:$JAVA_HOME/bin
(3)、让文件生效执行如下命令
source /etc/profile
(4)、执行java -version命令,出现如下图所示则jdk配置成功

4、hadoop-2.5.0安装与配置
(1)、解压下载好的hadoop-2.5.0.tar.gz包
tar -zxf hadoop-2.5.0.tar.gz -C ../model/
(2)、进入hadoop-2.5.0目录,在当前路径的share目录下,有个doc目录,此目录存放的都是官方英文说明文档,基本没用且占用空间及大,建议删除此目录,为后续发送集群节点节省时间
rm -rf share/doc
(3)、修改/opt/model/hadoop-2.5.0/etc/hadoop目录下hadoop-env.sh、mapred-env.sh、yarn-env.sh这三个配置文件,设置JAVA_HOME安装目录,如下所示
export JAVA_HOME=/opt/model/jdk1.7.0_67
(4)、修改core-site.xml配置文件,内容如下
<configuration> <!--指定namenode主节点所在的位置以及交互端口号--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-senior01.dinghong.com:8020</value> </property> <!--更改hadoop.tmp.dir的默认临时目录路径--> <!-- /opt/model/hadoop-2.5.0/data/tmp 这个路径需自己先行创建 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/model/hadoop-2.5.0/data/tmp</value> </property> </configuration>
(5)、修改slaves配置文件,内容修改如下
#定义datanode从节点所在哪台机器,由于此次笔记是伪分布式安装,所有主从节点都在一台机器上,所以主机名都是一样
hadoop-senior01.dinghong.com
(6)、修改hdfs-site.xml配置文件,内容如下
<configuration> <!--指定副本个数,默认值是3个--> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
(7)、修改yarn-site.xml配置文件,内容如下
<configuration> <!-- 指定yarn上运行的是mapreduce程序 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定ResourceManager的位置--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-senior01.dinghong.com</value> </property> </configuration>
(8)、将mapred-site.xml.template文件重命名为mapred-site.xml,并修改其内容如下
<configuration> <!--指定MapReduce运行在YARN上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
(9)、对于NameNode进行格式化操作,命令如下(只需要一次格式化,多次格式化会出错):
bin/hdfs namenode -format
出现如下图所示,表示格式化成功,若格式化出现错误,则需要仔细查找日志信息,查找出错原因,再次格式之前,一定把/opt/model/hadoop-2.5.0/data/tmp目录下的文件删除干净

5、hadoop-2.5.0上述步骤操作完毕后,即可启动相关进程
sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager
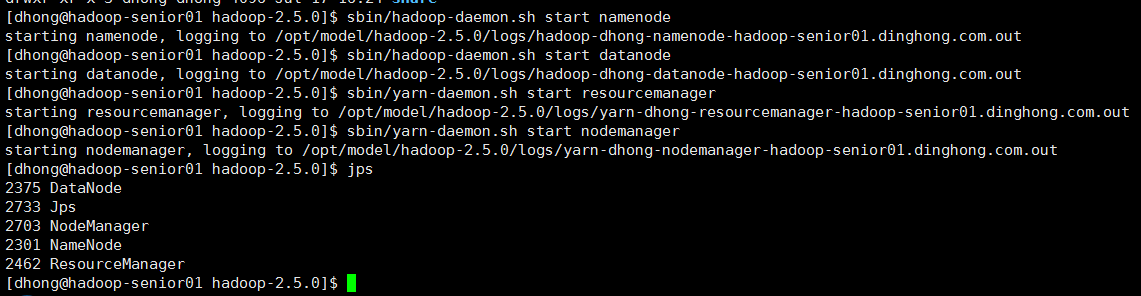
在web页面访问hdfs以及yarn信息页面,说明启动成功了,如下图所示
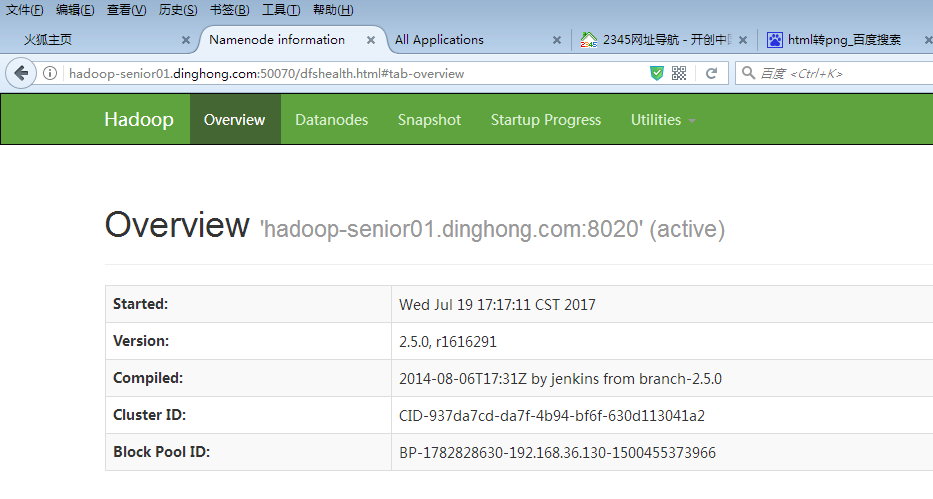
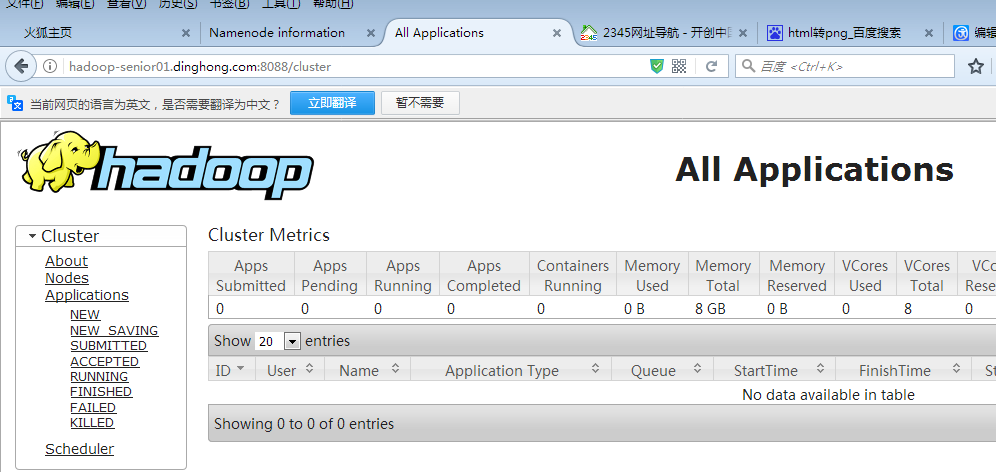
6、继续开启自带历史服务器和日志聚集功能
(1)、修改mapred-site.xml配置文件,配置历史服务器,添加如下内容
<!-- 指定历史服务器的所在机器 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-senior01.ibeifeng.com:10020</value> </property> <!-- 指定历史服务器外部访问地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-senior01.ibeifeng.com:19888</value> </property>
(2)、修改yarn-site.xml配置文件,开启日志聚集功能,添加如下内容
<!-- 指定是否开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志在HDFS上保留的时间期限 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property>
7、HDFS文件权限的修改
(1)、修改hdfs-site.xml配置文件,设置不检查文件权限,添加如下内容
<!--设置不启用HDFS文件系统的权限检查--> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property>
(2)、修改core-site.xml配置文件,设置不检查文件权限,添加如下内容
<!--指定修改Hadoop静态用户名,建议设为hadoop启动用户--> <property> <name>hadoop.http.staticuser.user</name> <value>dhong</value> </property>
