
OO第一阶段作业总结之菜鸡历险记
前言
这三次循序渐进的求导作业让我逐渐完善了自己的类架构和方法的划分,在紧张刺激的疯狂重构中逐步理清面向对象所特有的逻辑关系。尤其是从第二次作业到第三次作业,我从随意地在一个类中增添方法并随意地暴露类成员属性,进步到学会增加类的数量,分层次地、独立地实现每个类的功能,并用接口统领全局。
一. 整体思路
第一次作业
(1)用正则表达式按匹配拆分的方式匹配(防止大正则因为(中间项)*的形式爆栈)
(2)将式中所有的空格和\t用空串取代,然后用正则表达式对不带符号的首项(特判)和中间项进行匹配提取。
(3)在PolyTerm类中,对项进行分组匹配提取符号、系数、指数并求导。
(4)在Polynomial类中,将求导得到的项存入Arraylist中,并在同时合并同类项。
(5)打印:
1. 先将系数为0的项从Arraylist中去掉。如果此时Arraylist为空,输出0,否则继续处理。
2. 将系数大于0的项(如果有的话)换到最前面(表达式长度-1)
3. 如果不是第一项且此项为正,输出一个正号。
4. 如果指数为0,直接输出系数(常数),结束。
5. 如果系数为1,则不输出系数;如果系数为-1,则输出-;否则输出系数和乘号。
6. 输出x。
7. 如果指数为1,不输出;否则输出^和指数。
第二次作业
(1)在Expression类中,逐项匹配输入的字符串判断WF。
(2)将表达式逐项拆解,实例化Term对象并求导。
(3)对每个新的求导生成的项,合并同结构不同系数的项并将其存入ArrayList中。项的类型Struct是Expression类中的嵌套类,包含项的一个构造方法和4个属性:
coef:系数,indexPower:x的次数,indexSin:sin的次数,indexCos:cos的次数
(4)打印因子时,由于第一项之前已经有乘号了,故第一次输出x,sin(x)或cos(x)项时直接输出str,此后都输出“*”+str。
(5)尝试将每两项按照如下化简规则合并,若合并成功则break到最外面,再重新开始对list循环查找,直到某一次扫遍整个list都没找到能合并化简的两项,则结束。
化简规则:
1. asin(x)^2+bcos(x)^2
将绝对值小的一项的系数作为常数,再加上剩余的sin(x)^2或cos(x)^2项
2. 1-sin(x)^2=cos(x)^2
3. 1-cos(x)^2=sin(x)^2
经试验可知,a-bsin(x)^2以及a-bcos(x)^2的化简可能反而使输出表达式字符数增多,因此规则2,3要求两项系数相同。
(6)去除ArrayList中所有为0的项,输出。
第三次作业
(1)按照表达式、组合项、因子的层次,构建基于递归的输入合法性判定。
(2)在表达式、组合项以及三角函数嵌套这三个类中将输入字符串逐层递归拆解。
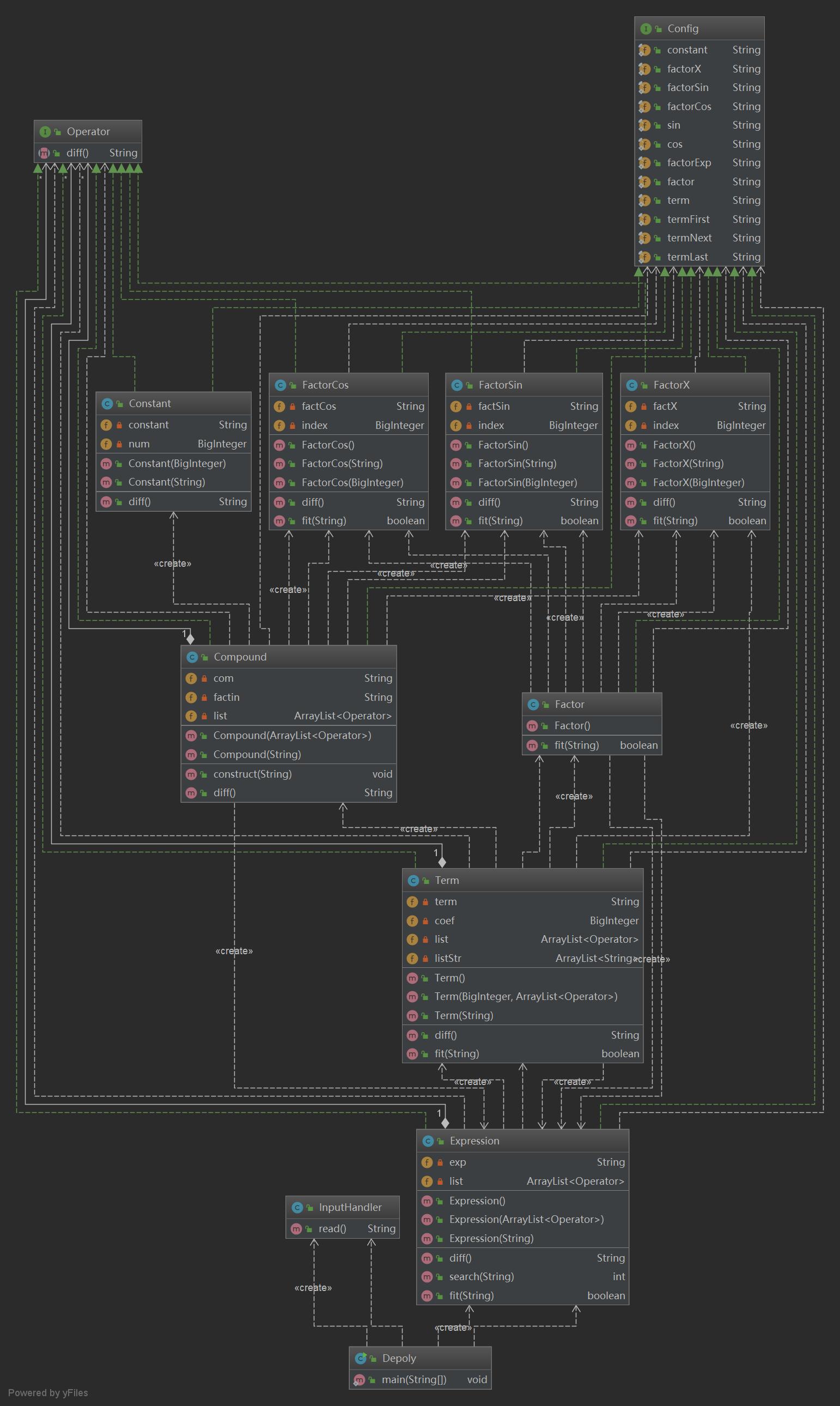
(3)使用接口Operator将表达式、组合项、嵌套因子、四种因子(Constant,FactorX,FactorSin,FactorCos)联系起来,使它们的求导方法能够无差别地互相调用,而不必区分被调用者到底是哪一个类的实例化对象。(聪明的我还定义了一个Config接口,里面塞了几乎所有的正则匹配模式串,所有implements了它的类都能愉快地享用其中的模式串)
(4)求导方法逐层递归地返回String,在主类中得到最后的输出。
二. 自我测试中发现的问题
第一次作业
(1)爆栈
在500个+x的狂轰滥炸下,大正则匹配的方式完美地爆炸了。于是,我对表达式进行匹配拆分如下:
1. 首项:[ \\t]*[+-]?[ \\t]*+term
2. 中间项:[ \\t]*[+-][ \\t]*+term
3. 末尾:[ \\t]*
成功地解决了爆栈问题。
(2)优化
除合并同类项外,将正项(如果有)提前到首项还能减少一个字符。因此,遍历ArrayList, 将找到的第一个正项与首项互换即可。
第二次作业
(1)空输入
中测时发现空输入报错的问题,用hasNextLine()解决。
第三次作业
由于难度剧增,这次作业中遇到的问题非常多,并且多次导致无法通过简单的debug处理,只能重构。以下这些问题是我多次重构的动力之源。
(1)嵌套带来的正则匹配问题
最初,我以为前两次作业的逐项拆解方式也能完美地搞定这次的合法性判断,因此只是使用\\(.*\\)和sin\\(.*\\) 这两种模式匹配表达式因子和三角函数嵌套因子并逐层拆解递归。然而,小伙伴甩过来的如下两个样例让我陷入了绝望沉思:
1. sin(x)+cos(x)
2. sin((cos(x)+x))
对于样例1,贪婪型匹配会把整个x)+cos(x当成内嵌因子,从而在判断内嵌因子合法性时成功WF。而对于样例2,勉强型匹配又会之匹配到sin((cos(x)+x),同样造成内嵌因子判定的问题。这导致了我的代码遇到WF时几乎100%能判出WF,但不是WF时也有巨大可能WF(……)。
因此,我不得不将整个合法性判断部分重构。在Expression部分的组合项提取中,只有在加号处满足前面的左右括号匹配,且加号前(跳过空白符)不是^或*符号时才提取组合项,在判断其匹配组合项后送入Term继续拆解,在Term中也遵循乘号前左右括号匹配的原则按乘号拆解成Factor。
(2)表达式、项和嵌套因子的拆分
在最初的结构中,我的表达式、项以及嵌套因子类都设置了一个split方法,负责对输入的字符串进行逐层拆解。然而,发现自己几乎在每次实例化对象后都会调用其split方法时,我忽然感受到了自己的智障愚蠢,灰溜溜地把所有split方法并入了构造方法中。
调用split方法虽然并没有什么实质上的问题,但放着构造方法这种好工具不用的愚蠢行径还是给了我深刻的教训orz。
(3)求导
当我兴冲冲地把新鲜出炉de了一通小bug的代码交上去并且信心满满地觉得自己能一遍过时,却心痛地看到:Runtime Error。我意识到,求导时将结果以接口Operator统领的各种类(比如Term, Expression,Compound等)的实例化对象的形式返回,大大增加了递归调用的层数,还混乱到自己也不知道哪个地方多调用了几层。
因此,我抛弃了这种看起来很漂亮但实现起来过于混乱的方式,改成返回String类型,并通过省略指数、系数以及去掉0和1*的方式,自底向上地完成了最基础的化简工作。
(4)优化相关的遗憾
1. 被忽略的0*
在对组合项Term求导的过程中,由于我在求导前已经事先将所有系数提出并存在coef中,导致我以为在组合项求导时并不会出现0*的情况。然而,愚蠢的我忽略了sin(15)这种常数型嵌套因子导数为0的情况,最终惊现0*(暴风哭泣)。
2. 瞎bb两句没能实现的优化策略
采用自底向上的优化模式,在因子类中处理好^1, 1*, 0之类的情况(这些基本完成),在组合项中着重于内嵌因子求导为0的情况,在Term中把每一个组合项进行提取常数、x的幂次、以及相同因子幂次的操作,在表达式中把系数不同但其后结构完全相同的组合项合并。为此,可能需要对从因子到表达式的每个类单独设置求导系数的get方法,实现系数与其后组合项的分离。但由于策略实现起来既困且难,还面临着再次Runtime Error的风险,菜鸡只能放弃,写在这里权当完成遗愿(……)。
(5)i和j,&&和||的双重傻傻分不清楚
Expression类的合法性检测中,我本意想从+-号位置向前查找第一个空白符并且判断其是否为^或*,但由于极度不全面的自我测试(写给自己的测试样例居然全部没加空格,万分后悔自己的愚蠢.jpg),导致往前去寻找第一个非空白符的变量j根本没有移动。因此,x^ +1,x* +1的等非常简单的数据都能轻而易举地被我判成WF。以下是代码对比。
修改前: 修改后:


三、代码分析
在借鉴学长大佬们博客的基础上,总结程序结构的度量参数如下:
(1)ev(G):基本复杂度,用来衡量程序非结构化程度的,范围在[1,v(G)]之间,值越大则程序的结构越“病态”。非结构成分降低了程序的质量,增加了代码的维护难度。
(2)Iv(G):模块设计复杂度,用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。
(3)v(G): 循环复杂度,用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数。
博客链接:https://www.cnblogs.com/qianmianyu/p/8698557.html
https://www.cnblogs.com/panxuchen/p/8689287.html
第一次作业
(1)类图

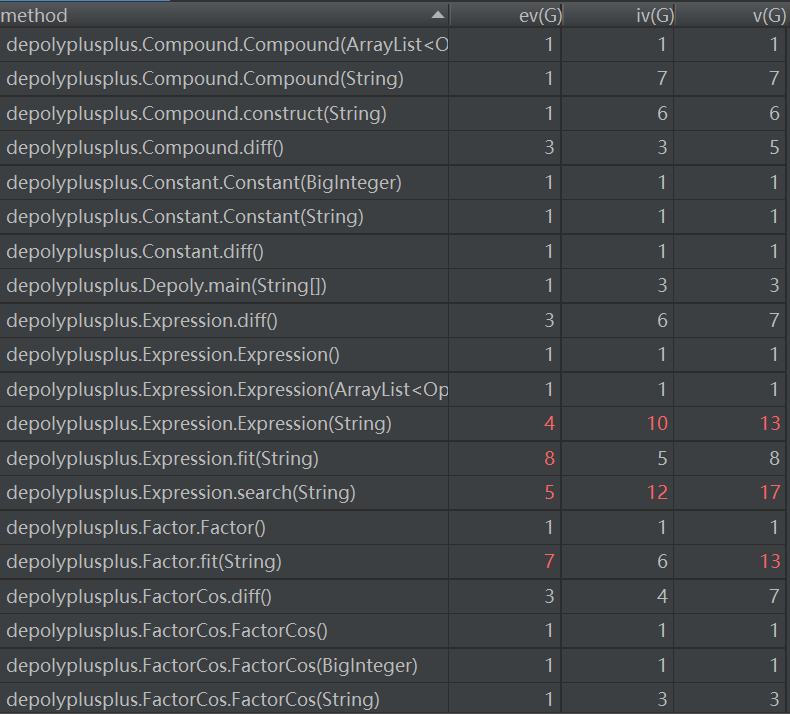
(2)方法度量

(3)分析
1.结构分析
第一次作业的类定义主要包括多项式类和项类。多项式类的功能是合法性判断、求导结果储存和打印字符串,项类的功能是在构造方法中解析传入项的系数、指数并将求导结果返回给多项式类。其中,我使用了coefList和indexList两个ArrayList分开存储系数和指数,这样的设计缺乏整体性思维,有所欠缺。改进方法是将ArrayList中所存元素的数据结构定义为两个BigInteger(系数和指数)组成的二元组。
2.复杂度分析
从方法度量中可以看出,formatFit的基本复杂度较高。这是由于在逐项匹配的过程中,我使用了if/else以及while循环的结构。在互测阶段,我发现有大佬使用独占性匹配的方法,可以避免拆项带来的复杂度,值得借鉴。当然,这次作业可以使用独占性匹配的原因是,一次性匹配整个字符串的结果一定符合我们的需求。但接下来的两次作业(尤其是第三次)最终还是逃不开逐项拆解。
Polynomial中print方法兼有基本复杂度、模块设计复杂度、循环复杂度高的缺点。这是由于print方法完成了去点系数为0的项,前移正项以及以最简略的方式逐项输出的众多功能。事实上,对其进行拆解,会比将其一股脑放在输出方法中要更合理一些。
第二次作业
(1)类图

(2)方法度量

![]()
(3)分析
1.结构分析
虽然本次作业没有什么bug,但它其实是我的作业中结构最丑的一次。由于沿用了第一次作业中主类、表达式类、项类的基本框架,导致表达式类中的方法过多,结构混乱,不少方法甚至只是为了满足60行的长度限制而强行拆解出来的。事实上,我应该在表达式的求导方法中调用Term的求导方法,并将返回值设置为Expression类(或者ArrayList),然后直接merge即可。同时,我还将Term的属性直接暴露给了Expression类,违背了设计原则。这些缺点都很可能导致潜在的bug。
2.复杂度分析
formatFit以及print方法复杂度较高的原因与第一次作业基本类似。
simplify方法基本复杂度较高的原因是其中嵌套了一个最外层while循环以及对每两项进行化简检查的两层for循环,并且不断使用if-break结构来判断是否找到符合某一种化简方法的情形。这其实是化简的设计方案导致的。Term构造方法的模块设计复杂度、循环复杂度也较高,这主要来源于将组合项拆解成因子时指数、系数匹配提取。
第三次作业
(1)类图
(2)方法度量

(3)分析
1. 结构分析
本次作业的结构整体上优于第二次作业。在疯狂重构(实际上重写了一遍代码)的情况下,告别混乱的构造和求导,最终得到了层次、思路都较为清晰的代码架构。
2. 复杂度分析
复杂度较高的方法,其主要原因是使用了多层嵌套的while循环,if/else式的字符串拆解和因子类型判断,以及递归层级之间的相互调用传参等。
四、快乐hack
三次作业的互测环节,除第一次能看到被hack次数时为跟风hack研究过代码以外,之后都是拿构造样例无差别打击。
第一次作业
构造样例时,我主要考虑了符号格式奇怪的首项,合并同类项后数组为空的情形,空串,爆栈,以及在所有可能加空格的地方组合式插入空格组建表达式的覆盖性测试方案。测试时,我hack到了表达式末尾不匹配(在末尾随便输什么都会被过滤掉)、数组为空时无输出(一个0砍了屋友,两个0误伤队友)的情况,并通过研究代码hack到了开头两个字符莫名被过滤掉的问题。
第二次作业
样例构造方法与第一次类似,hack到了sin(x)中每个括号两侧未考虑空格的格式错误,以及多个因子相乘且带有指数和空格时,正则匹配判断错误的问题。
第三次作业
主要针对自己在代码实现过程中遇到的问题和bug构造测试样例。
五、心得体会
覆盖性样例构造很重要,不要奢望自己写的能和想的一样。结构清晰很重要,当代码过于混乱导致连自己都难以分析清楚功能的实现机理时,一定不要犹豫地重写重构,否则面向对象编程可能就变成了面向de不完甚至解决不了的bug编程。以及实现同一接口的类中的同一方法能被无差别调用这一特性,也给我带来了很大的实用性好处,希望能在以后的实践中发掘其更多用处。

