NLP——天池新闻文本分类 Task2
NLP——新闻文本处理:TASK2 数据处理与数据分析
1.数据读取
import os
import pandas as pd
import matplotlib.pyplot as plt
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
#设置显示范围
#pd.set_option('display.max_columns', 1000)
#pd.set_option('display.width', 1000)
#pd.set_option('display.max_colwidth', 1000)
#数据读取
train_df = pd.read_csv('train_set.csv',encoding='gbk',sep='\t')
print(train_df.head())
sep :列间分隔符
nrows :读取行数
| label | text | |
|---|---|---|
| 0 | 2 | 2967 6758 339 2021 1854 3731 4109 3792 4149 15... |
| 1 | 11 | 4464 486 6352 5619 2465 4802 1452 3137 5778 54... |
| 2 | 3 | 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... |
| 3 | 2 | 7159 948 4866 2109 5520 2490 211 3956 5520 549... |
| 4 | 3 | 3646 3055 3055 2490 4659 6065 3370 5814 2465 5... |
数据集每行代表一个文本,第一列为新闻类别,第二列为文本字符。
2.数据分析
文本长度分析
每行代表一条新闻,每行文本中的字符使用空格隔开。
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
#apply默认以列为单位分别对列应用函数
#split通过指定的字符对字符串进行切片,以空格为分隔符对数据切片
print(train_df['text_len'].describe())
count 200000.000000
mean 907.207110
std 996.029036
min 2.000000
25% 374.000000
50% 676.000000
75% 1131.000000
max 57921.000000
Name: text_len, dtype: float64
可以看到每条文本平均字符数为907个,最多字符数为57921,最短的文本仅有2个字符。
下面将每条新闻文本的长度绘制直方图
_ = plt.hist(train_df['text_len'], bins=20000)#直方图 句子长度
plt.xlim(0,8000)
plt.xlabel('Text char count')
plt.title("Histogram of char count")
plt.savefig("text_len.png")
plt.show()
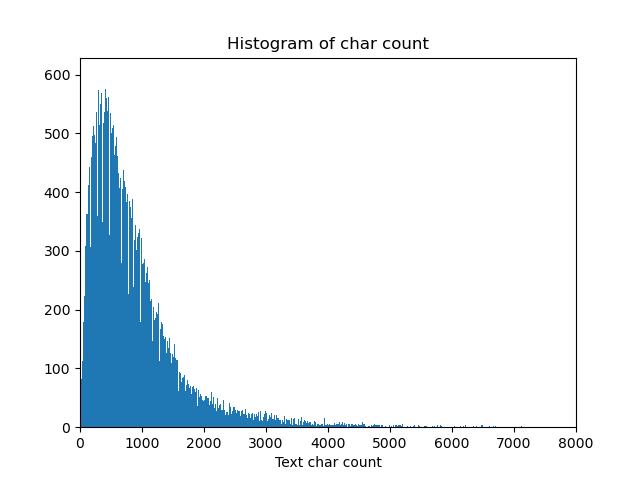
可以看到大部分新闻文本的字符数目都集中于2000以内
新闻类别统计
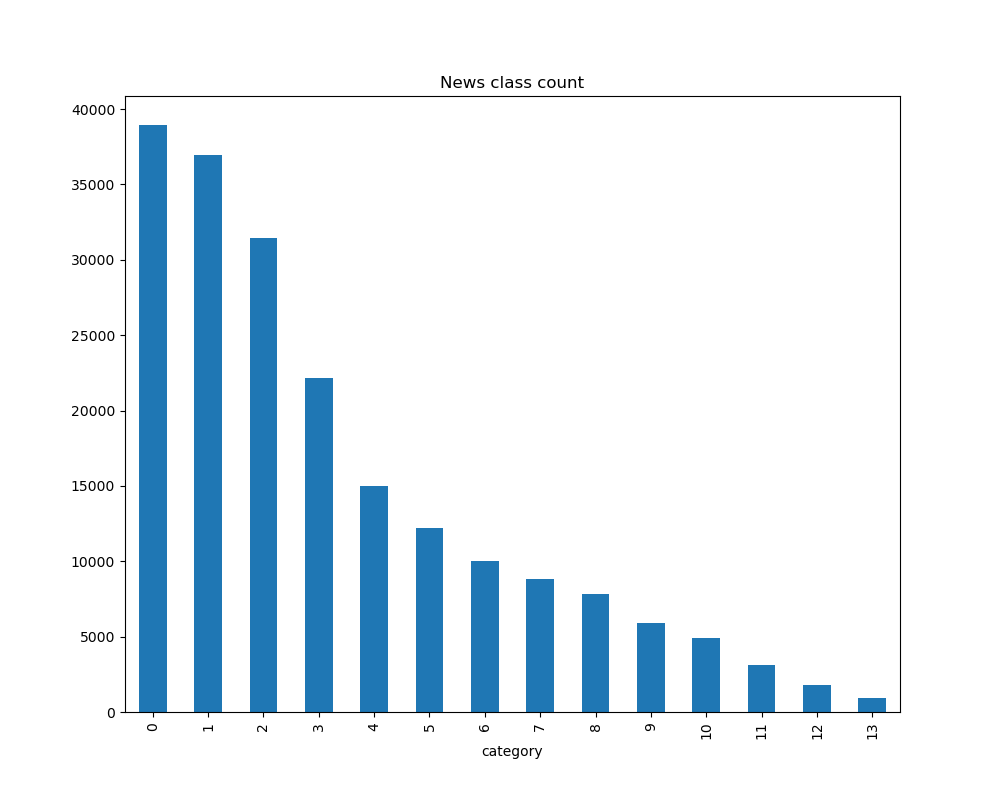
可对数据集的类别进行分布统计,得到各个类别新闻的样本个数:
plt.figure(figsize=(10,8))
train_df['label'].value_counts().plot(kind='bar')
plt.title('News class count')
plt.xlabel("category")
plt.savefig("text_label.png")
plt.show()
pandas 的value_counts() 函数可以对Series里面的每个值进行计数并且排序。默认从高到低做降序排序。
如果想用升序排列,可以加参数 (ascending=True) 。
如果想得出的计数占比,可以加参数 normalize=True 。
空值是默认剔除掉的。value_counts()返回的结果是一个Series数组,可以跟别的数组进行运算。
在数据集中标签的对应的关系如下:{'科技': 0, '股票': 1, '体育': 2, '娱乐': 3, '时政': 4, '社会': 5, '教育': 6, '财经': 7, '家居': 8, '游戏': 9, '房产': 10, '时尚': 11, '彩票': 12, '星座': 13}
可以看出科技类新闻文本数量最多,星座类最少。
字符分布统计
统计每个字符出现的次数,将所有句子先用空格进行拼接,再计数:
from collections import Counter
all_lines = ' '.join(list(train_df['text']))#用空格连接生成新的字符串
word_count = Counter(all_lines.split(" "))#以空格切片再进行计数,得到
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)#排序
print(len(word_count))
print(word_count[0])#降序排序首位为最高次数
print(word_count[-1])#末位为最低次数
6869 #整个训练集数据的总体字符数
('3750', 7482224)
('3133', 1)
从中可以看出整个训练集包含6869个字符,其中编号为'3750'的字符出现的次数最多,有7482224次,3313出现的次数最少,仅有一次。
Counter :Counter类继承dict类,因此能够使用dict类中的方法,用于统计字符串中每个字符的数量(出现次数)。
import collections
obj = collections.Counter('aabbccc')
print(obj)
Counter({'c': 3, 'a': 2, 'b': 2})
c.items() :转为(elem, cnt)格式的列表。
sorted :对key进行排序。
sorted(iterable, cmp=None, key=None, reverse=False)
参数说明:
iterable -- 可迭代对象。
cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。此处依照第二个元素,即出现次数进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)
各个字符在每个句子中会存在多次,下面统计每个字符会出现在多少个句子中。
from collections import Counter
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
#用空格切片生成一个集合,set删除重复的元素,再list生成一个数组,利用空格进行拼接
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0])
print(word_count[1])
print(word_count[2])
('3750', 197997)
('900', 197653)
('648', 191975)
'text_unique' 为删除掉句内重复后的字符数组。
可以看到字符3750,900和648在20w条数据中出现率接近99%,可猜测为标点符号。
3.课后练习
1.假设字符3750,字符900和字符648是句子的标点符号,请分析赛题每篇新闻平均由多少个句子构成?
假设标点符号均分隔句子,只需计数其中的标点个数即可粗略计算每条新闻的句子个数。
train_df['punctuation']=train_df['text'].apply(lambda x:sum([x.count('3750'),x.count('900'),x.count('648')]))
sum1=train_df['punctuation'].mean()
print(sum1)
得到结果:
79.80237
2.统计每类新闻中出现次数最多的字符
首先需要去掉所有文本中的标点符号,否则运算结果将产生错误。
先将所有文本进行分组,运用groupby函数,
df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式——函数名称)
np.concatenate :一次完成多个数组的拼接。
.rest_index() :对于清洗后的数据进行重置其索引。
由于数据过多,取前500条文本进行运算:
stop = ['3750','900','648']
train_df['text_stop'] = train_df['text'].apply(lambda x: [i for i in x.split(' ') if i not in stop])#去掉标点符号
temp = train_df[['label','text_stop']]
temp_1 = temp.groupby(['label'])['text_stop'].apply(lambda x:np.concatenate(list(x))).reset_index()
#以label进行分类,再对每一类别进行计数
freq = [ ]
for i in range(0,len(temp_1)):
word_count = Counter(temp_1['text_stop'][i])
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
freq.append(word_count[i])
#print(freq)
for i in set(train_df['label']):
print('label {}: {}'.format(i,freq[i]))
得到结果:
label 0: ('3370', 1216)
label 1: ('4464', 1403)
label 2: ('6122', 819)
label 3: ('669', 320)
label 4: ('4893', 184)
label 5: ('803', 230)
label 6: ('669', 264)
label 7: ('2109', 167)
label 8: ('3560', 181)
label 9: ('4939', 79)
label 10: ('7399', 85)
label 11: ('3370', 31)
label 12: ('2218', 43)
label 13: ('1375', 32)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号