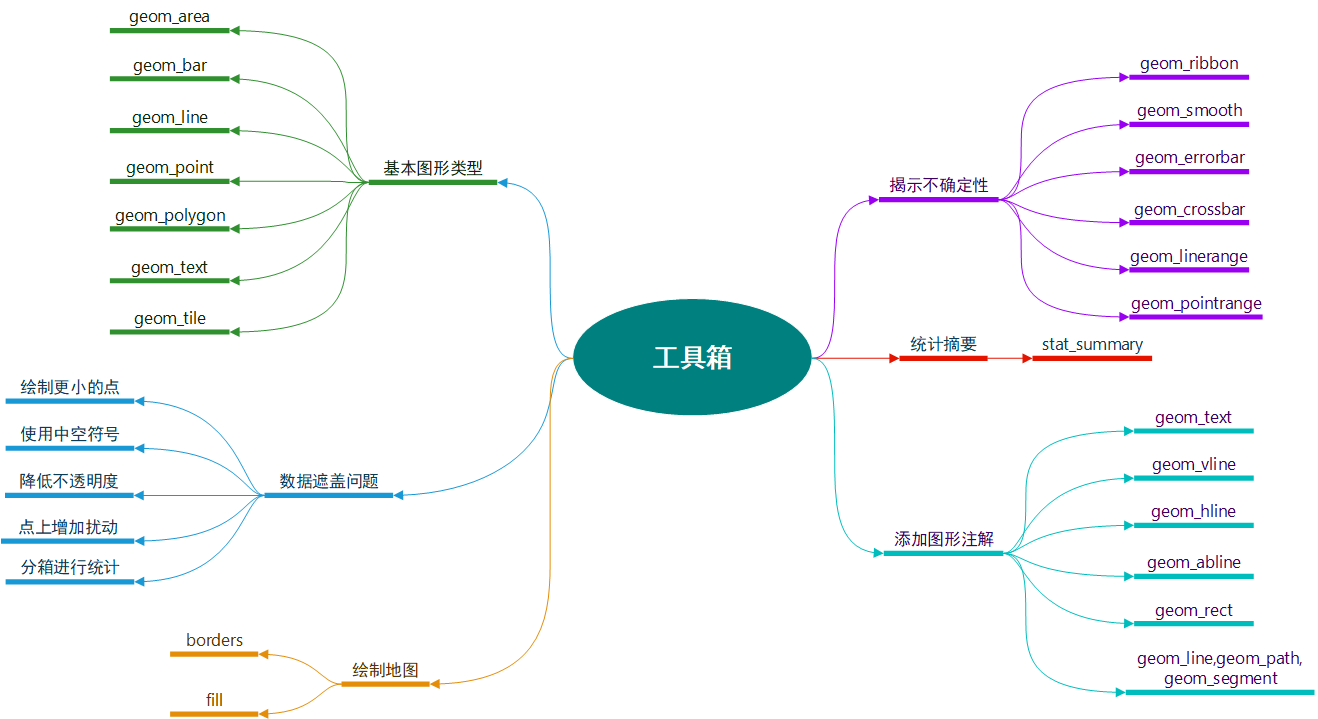
ggplot2(5) 工具箱
5.1 简介
ggplot2的图层化架构鼓励我们以一种结构化的方式来设计和构建图形。本章旨在概述可用的几何对象和统计变换,在文中逐个详述。每一节都解决一个特定的作图问题。
5.2 图层叠加的总体策略
图层有三种用途:
- 用以展现数据本身;
- 用以展示数据的统计摘要。进一步理解数据,对模型做出评价;
- 用以添加额外的元数据、上下文信息和注解。展现数据背景或为原始数据赋予现实意义的注解。
5.3 基本图形类型
以下几何对象是ggplot2图形的基本组成部分。每种几何对象自身即可独立构建图形,同时也可以组合起来构建更复杂的几何图形。这些几何对象基本上都关联了一种常见的图形,当谋幅图只使用了一种几何对象构建时,这幅图往往拥有一个特定的名称。
这些几何对象均是二维的,故x和y两种图形属性都是不可或缺的。同时,它们都可以接受colour和size图形属性,另外,填充类几何对象还可以接受fill图形属性。点使用shape接受图形属性,线和路径使用linetype接受图形属性。这些几何对象可用于展示原始数据,另行计算得到的数据摘要和元数据。
- geom_area():用于绘制面积图,即在普通线图的基础上,依y轴方向填充了下方面积的图形。对于分组数据,各组将按照依次堆叠的方式绘制。
- geom_bar(stat = "identity"):绘制条形图。
- geom_line():绘制线条图。图形属性group决定了哪些观测是连接在一起的。
- geom_point():绘制散点图。
- geom_polygon():绘制多边形,即填充后的路径。
- geom_text():可在指定点处添加标签。通过设置hjust和vjust可以控制文本的横纵位置,设置angle可以控制文本的旋转。
- geom_tile():绘制色深图或者水平图。所有的瓦片(tile)构成了对平面的一个规则切分,且往往将fill图形属性映射至另一个变量。
df <- data.frame(
x = c(3, 1, 5),
y = c(2, 4, 6),
label = c("a","b","c")
)
p <- ggplot(df, aes(x, y)) + xlab(NULL) + ylab(NULL)
p + geom_point() + labs(title = "geom_point")
p + geom_bar(stat="identity") +
labs(title = "geom_bar(stat=\"identity\")")
p + geom_line() + labs(title = "geom_line")
p + geom_area() + labs(title = "geom_area")
p + geom_path() + labs(title = "geom_path")
p + geom_text(aes(label = label)) + labs(title = "geom_text")
p + geom_tile() + labs(title = "geom_tile")
p + geom_polygon() + labs(title = "geom_polygon")

散点图、条形图、线条图、面积图、路径图、标签(散点)图、色深图/水平图、多边形图。
由于条形图、面积图和色深图占据了数据本身范围以外的空间,因此坐标轴被自动拉伸了。
5.4 展示数据分布
有一些几何对象可以用于展示数据的分布,具体使用那种取决于分布的维度、分布是连续型还是离散型,以及我们感兴趣的是条件分布还是联合分布。
直方图
对于一维连续型分布,最重要的几何对象是直方图。
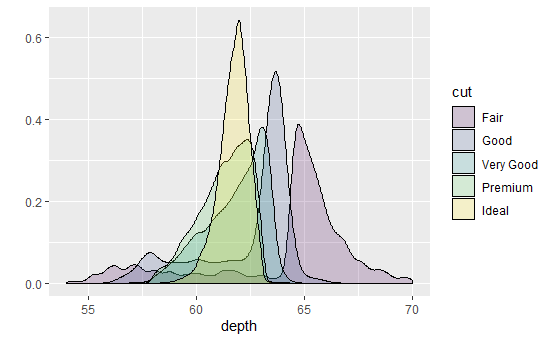
depth_dist <- ggplot(diamonds, aes(depth)) + xlim(58, 68) depth_dist + geom_histogram(aes(y = ..density..), binwidth = 0.1) + facet_grid(cut ~ .) depth_dist + geom_histogram(aes(fill = cut), binwidth = 0.1, position = "fill") depth_dist + geom_freqpoly(aes(colour = cut), binwidth = 0.1)
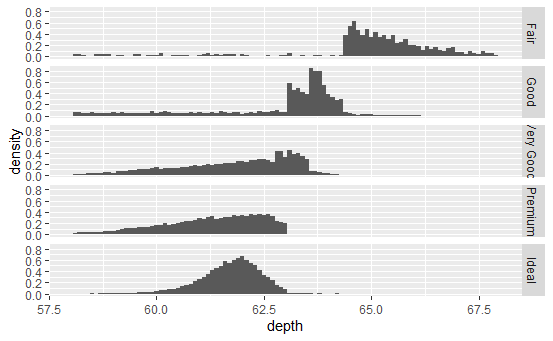
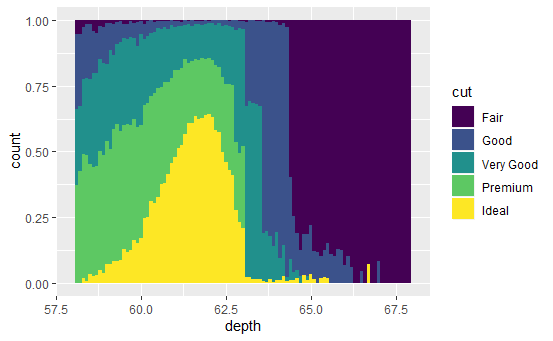
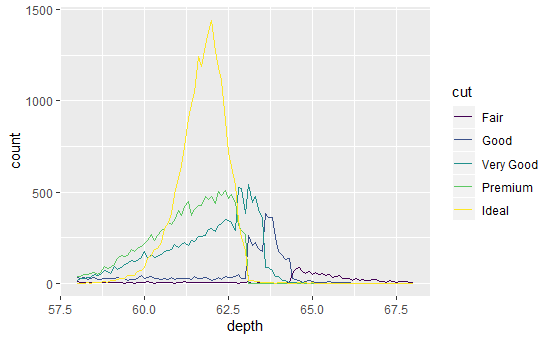
分面直方图、条件密度图、频率多边形图。
它们都显示了出一个有趣的模式:随着钻石质量的提高,分布逐渐向左偏移且愈发对称。
箱线图
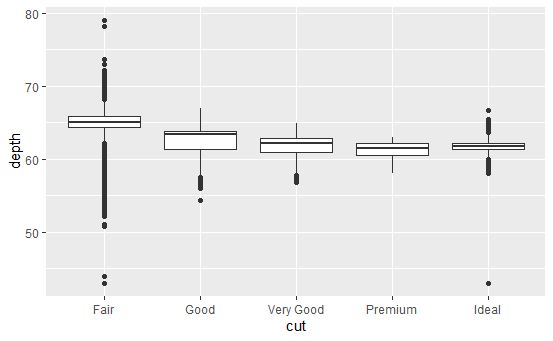
箱线图可以用于观察一个类别性或连续型变量取条件时,另一个连续型变量的分布情况。对于连续型变量,必须设置group图形属性以切分得到多个箱线图。
library(plyr)
qplot(cut, depth, data = diamonds, geom = "boxplot")
qplot(carat, depth, data = diamonds, geom = "boxplot",
group = round_any(carat, 0.1, floor), xlim = c(0, 3))

密度图
density是基于核平滑方法进行平滑后的频率多边形,仅在已知潜在的密度分布为平滑、连续且无界的时候使用这种密度图。使用参数adjust可以调整所得的密度曲线的平滑程度。
qplot(depth, data = diamonds, geom = "density", xlim = c(54, 70))
qplot(depth, data = diamonds, geom = "density", xlim = c(54, 70),
fill = cut, alpha = I(0.2))

5.5 处理数据遮盖问题
- 小规模的遮盖问题可以通过绘制更小的点或者使用中空的符号缓解。
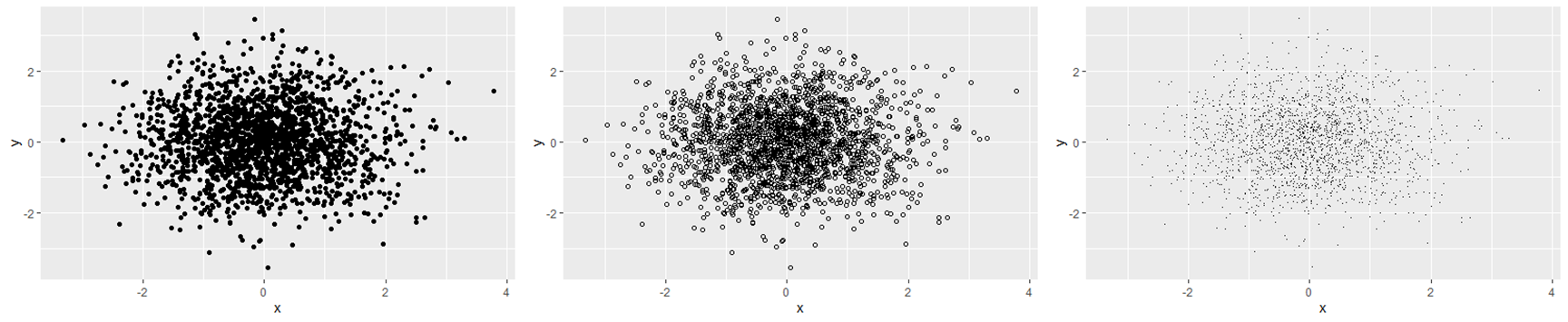
## 从左至右分别为:默认的 shape、shape = 1(中空的点),以及 shape= '.'(像素大小的点)。 df <- data.frame(x = rnorm(2000), y = rnorm(2000)) norm <- ggplot(df, aes(x, y)) norm + geom_point() norm + geom_point(shape = 1) norm + geom_point(shape = ".") # 点的大小为像素级
- 对于更大的数据集可以使用降低不透明度的方法,R中可用的最小alpha值为1/256。
- 如果数据存在一定的离散型,可以通过在点上增加扰动来减轻重叠。特别是与不透明度一起使用时,比较有效。
## 从左至右为:不加任何处理的点,使用默认扰动参数打散后的点, ## 横向扰动参数为 0.5 (横轴单位距离的一半)时打散后的点,alpha 值 1/50。 td <- ggplot(diamonds, aes(table, depth)) + xlim(50, 70) + ylim(50, 70) td + geom_point() td + geom_jitter() jit <- position_jitter(width = 0.5) td + geom_jitter(position = jit) td + geom_jitter(position = jit, colour = "black", alpha = 1/50)

- 也可以认为遮盖绘制问题是一种二维核密度估计问题,可将点分箱并统计每个箱中点的个数,然后通过某种方式可视化这个数量(直方图的二维推广)。
library(hexbin) d <- ggplot(diamonds, aes(carat, price)) d + stat_bin2d(bins = 50) d + stat_bin2d(binwidth = c(0.02, 200)) d + stat_binhex(bins = 50) d + stat_binhex(binwidth = c(0.02, 200))

正方形/六边形分箱。
- 使用stat_density2d进行二维密度估计。
d <- ggplot(mtcars, aes(wt, mpg)) d + geom_point() + geom_density2d() d + stat_density2d(aes(colour=..level..)) d + stat_density2d(geom = "tile", aes(fill = ..density..), contour = F) last_plot() + scale_fill_gradient(limits = c(0.01, 0.05))

等高线图,使用scale_fill_gradient以限制密度范围。
5.6 曲面图
ggplot2暂不支持真正的三维曲面图,但具有在二维平面上展现三维曲面的常见工具:等高线图,着色瓦片,气泡图等。
5.7 绘制地图
ggplot2提供了一些工具,让使用maps包绘制的地图与其他ggplot2图形的结合十分方便。下表中列出了可用的地图数据名称。我们使用地图数据可能有两种主要原因:一是为空间数据图形添加参考轮廓线,二是通过在不同的区域填充颜色以构建等值线图。
library(maps)
data(us.cities)
big_cities <- subset(us.cities, pop > 5e+05)
qplot(long, lat, data = big_cities) + borders("state", size = 0.5)
tx_cities <- subset(us.cities, country.etc == "TX")
ggplot(tx_cities, aes(long, lat)) + borders("county", "texas", colour = "grey70") +
geom_point(colour = "black", alpha = 0.5)
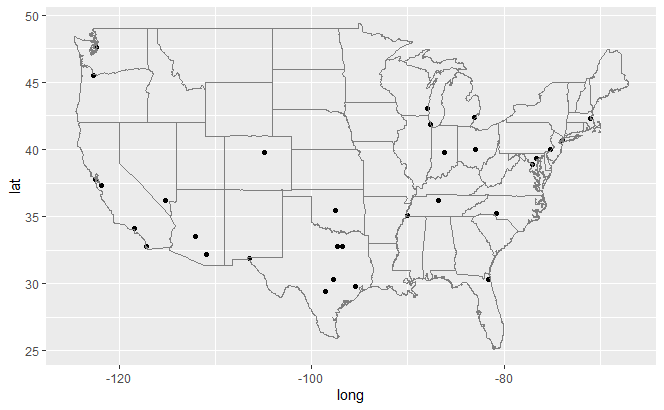

使用borders()添加地图边界,前两个参数指定了要绘制的地图名map以及其中的具体区域region,其余的参数用于控制边界的外观:如边界的颜色colour和线条粗细size。
展示了美国五十万人口以上的城市,德克萨斯州的城市区划。
使用fill绘制等值线图。
library(maps)
states <- map_data("state")
arrests <- USArrests
names(arrests) <- tolower(names(arrests))
arrests$region <- tolower(rownames(USArrests))
choro <- merge(states, arrests, by = "region")
# 由于绘制多边形时涉及顺序问题 且merge破坏了原始排序 故将行重新排序
choro <- choro[order(choro$order), ]
qplot(long, lat, data = choro, group = group, fill = assault, geom = "polygon")
qplot(long, lat, data = choro, group = group, fill = murder, geom = "polygon")

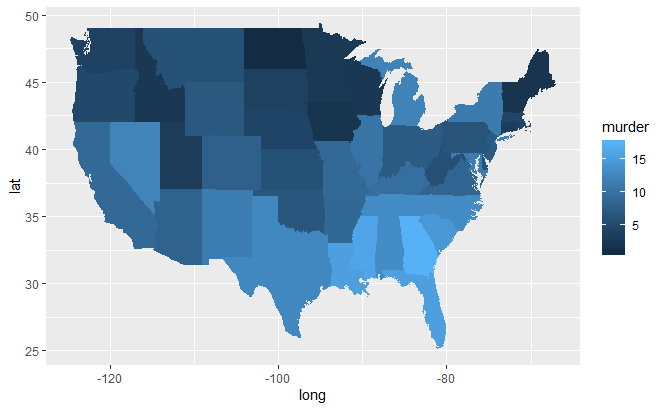
各州人身伤害案件的数量,各州谋杀类案件的数量。
使用map_data()将数据从maps包转换到适合用ggplot2绘图的数据。
library(plyr)
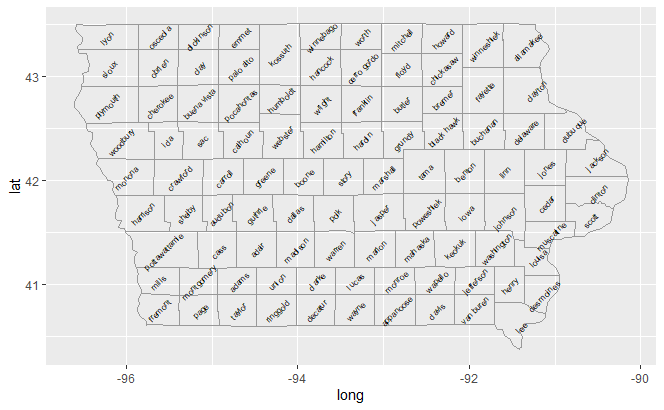
ia <- map_data("county", "iowa")
mid_range <- function(x) mean(range(x, na.rm = TRUE))
centres <- ddply(ia, .(subregion), colwise(mid_range, .(lat, long)))
ggplot(ia, aes(long, lat)) + geom_polygon(aes(group = group), fill = NA, colour = "grey60") +
geom_text(aes(label = subregion), data = centres, size = 2, angle = 45)
5.8 揭示不确定性
不论是从模型所得或是从对分布的假设而得,如果我们已经知道了一些关于数据中不确定性的信息,那么对这些信息加以展示通常是很重要的。ggplot2中的4类用以完成此项工作的几何对象被列于下表中,它们均假设我们对给定x时y的条件分布感兴趣,并且都使用ymin和ymax来确定y的值域。
| 变量X类型 | 仅展示区间 | 同时展示区间和中间值 |
| 连续型 | geom_ribbon | geom_smooth(stat = "identity") |
| 离散型 | geom_errorbar | geom_crossbar |
| geom_linerange | geom_pointrange |
d <- subset(diamonds, carat < 2.5 & rbinom(nrow(diamonds), 1, 0.2) == 1)
d$lcarat <- log10(d$carat)
d$lprice <- log10(d$price)
# 剔除整体的线性趋势
detrend <- lm(lprice ~ lcarat, data = d)
d$lprice2 <- resid(detrend)
mod <- lm(lprice2 ~ lcarat * color, data = d)
library(effects)
effectdf <- function(...) {
suppressWarnings(as.data.frame(effect(...)))
}
color <- effectdf("color", mod)
both1 <- effectdf("lcarat:color", mod)
carat <- effectdf("lcarat", mod, default.levels = 50)
both2 <- effectdf("lcarat:color", mod, default.levels = 3)
qplot(lcarat, lprice, data = d, colour = color)
qplot(lcarat, lprice2, data = d, colour = color)
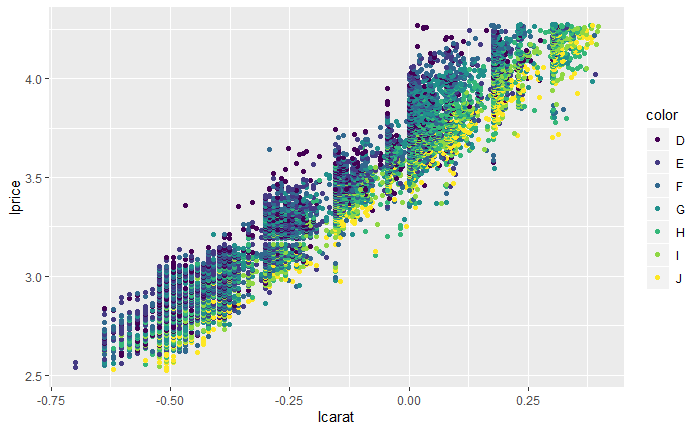
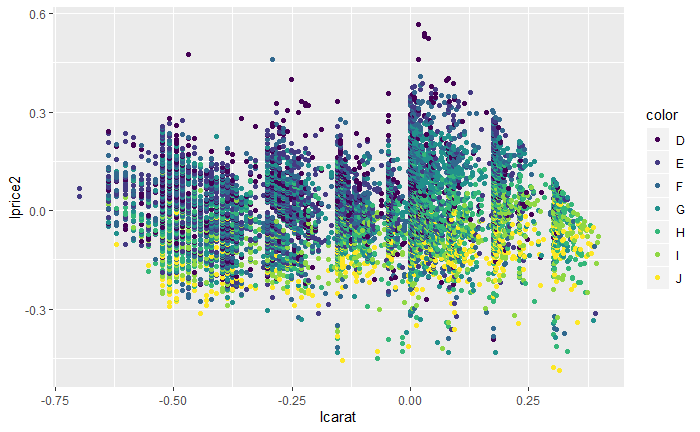
对x轴和y轴的数据均取以10为底的对数,剔除了主要的线性趋势。
fplot <- ggplot(mapping = aes(y = fit, ymin = lower, ymax = upper)) + ylim(range(both2$lower,
both2$upper))
fplot %+% color + aes(x = color) + geom_point() + geom_errorbar()
fplot %+% both2 + aes(x = color, colour = lcarat, group = interaction(color,
lcarat)) + geom_errorbar() + geom_line(aes(group = lcarat)) + scale_colour_gradient()
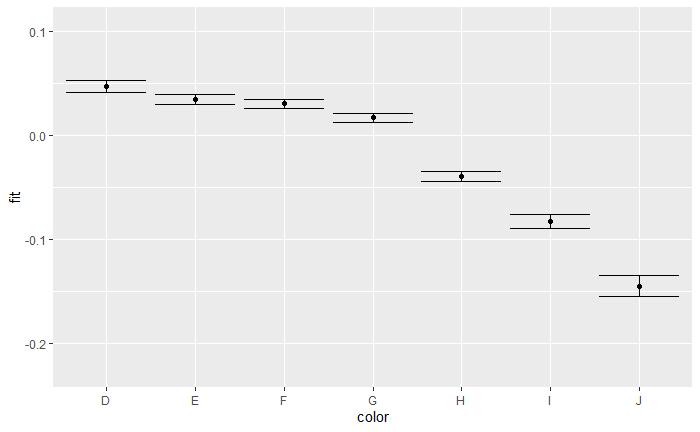
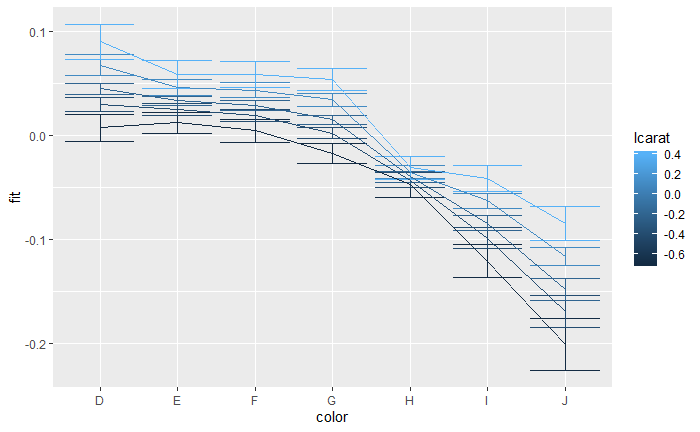
展示模型估计结果中变量color的不确定性:color的边际效应,针对变量caret的不同水平(level),变量color的条件效应。(95%置信区间)
fplot %+% carat + aes(x = lcarat) + geom_smooth(stat = "identity")
ends <- subset(both1, lcarat == max(lcarat))
fplot %+% both1 + aes(x = lcarat, colour = color) + geom_smooth(stat = "identity") +
scale_colour_hue() + theme(legend.position = "none") + geom_text(aes(label = color,
x = lcarat + 0.02), ends)
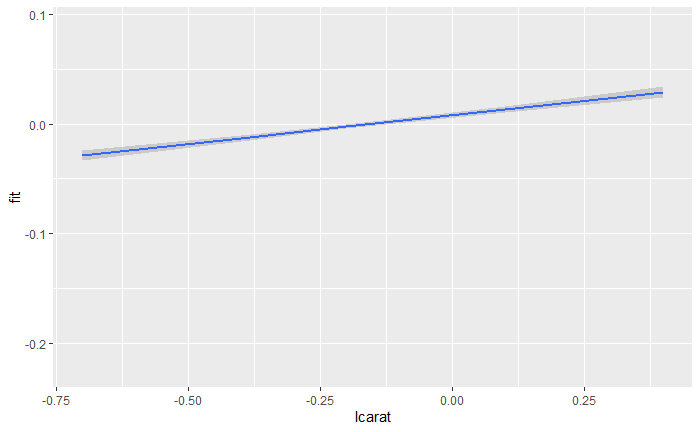
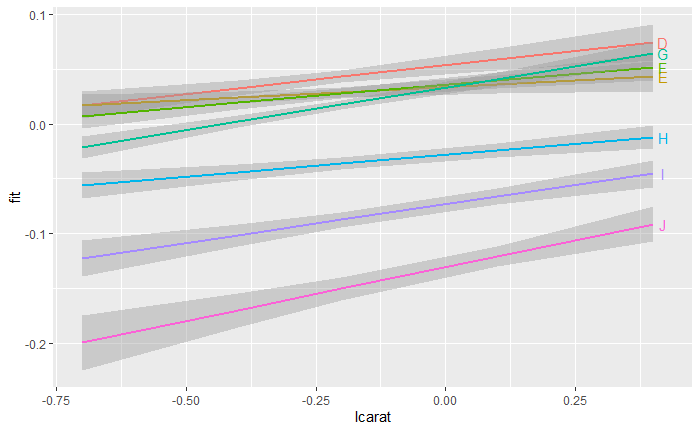
5.9 统计摘要
m <- ggplot(diamonds, aes(as.integer(clarity), price)) m + stat_summary(fun.y = "median", geom = "line") m + stat_summary(fun.y = "mean", geom = "line")
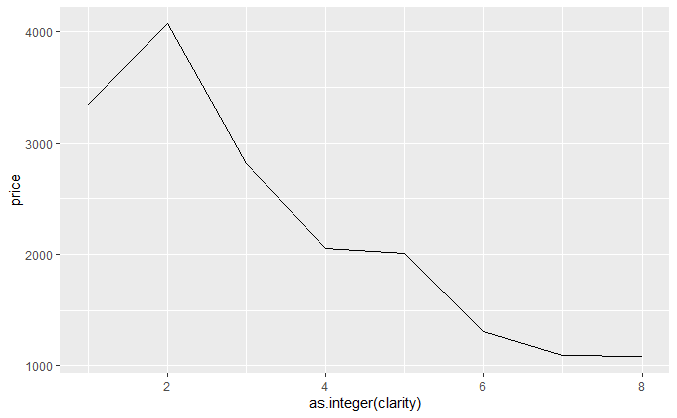
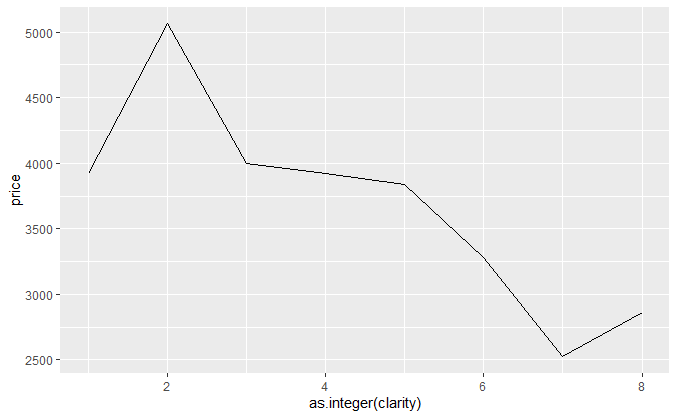
中位数,均值。
m2 <- ggplot(diamonds, aes(as.integer(clarity), price, colour = color)) m2 + stat_summary(fun.y = "median", geom = "line") m2 + stat_summary(fun.y = "mean", geom = "line")

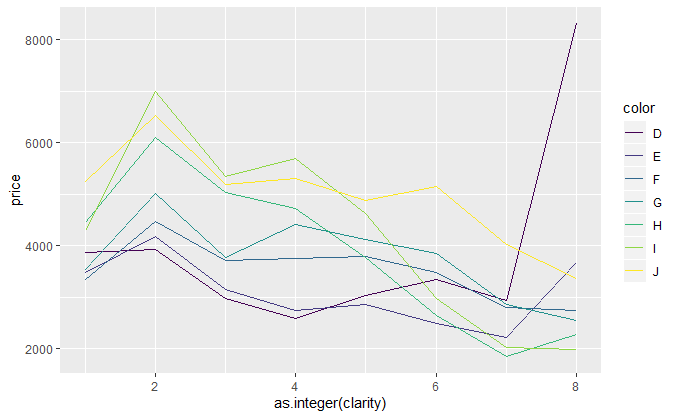
分组呈现。
midm <- function(x) mean(x, trim = 0.5)
m + stat_summary(aes(colour = "trimmed"), fun.y = midm, geom = "point") +
stat_summary(aes(colour = "raw"), fun.y = mean, geom = "point")
trim:在计算平均值之前,从x的每一端要裁剪的观测值的分数(0到0.5)。修剪范围以外的值作为最近的端点。

iqr <- function(x, ...) {
qs <- quantile(as.numeric(x), c(0.4, 0.6), na.rm = T)
names(qs) <- c("ymin", "ymax")
qs
}
m + stat_summary(fun.data = "iqr", geom = "ribbon")

下表给出了来自Hmisc包中的摘要计算函数,这些函数拥有专门的封装,以使它们能够与stat_summary()更轻松地共同使用。
| 函数名 | Hmisc包中原名 | 中间值类型 | 所计算区间 |
| mean_cl_normal | mean.cl.normal() | 均值 | 正态渐进所得标准误 |
| mean_cl_boot | mean.cl.boot() | 均值 | Bootstrap所得标准误 |
| mean_sdl | mean.sdl() | 均值 | 标准差的倍数 |
| median_hilow | median.hilow() | 中位数 | 尾部面积相同的外分为点对 |
以下为补充:
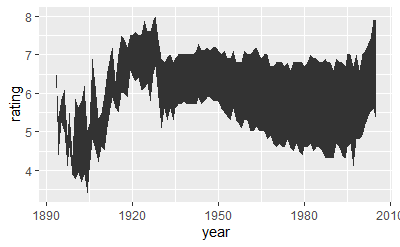
因为之前没有找到movies数据集,所以没有画出下面的图形。movies数据集已不在包含于ggplot2中,而是在ggplot2movies包中,需要单独加载。
movies数据集包含了5万多(58788)部电影的数据,24个变量。
- title:电影名称;
- year:上映年份;
- budget:总预算(如果已知,美元);
- lenght:时长(分钟);
- rating:平均IMDB用户评级;
- votes:给这部电影评分的IMD用户数目;
- r1~r10:对这部电影的评价是1的用户百分比;
- mpaa:美国电影协会评级;
- action, animation, comedy, drama, documentary, romance, short:动作、动画、喜剧、戏剧、纪录片、爱情片、短片。表示电影是否属于这一类型的二元变量。
library(ggplot2movies) m <- ggplot(movies, aes(year, rating)) m + stat_summary(fun.y = "median", geom = "line") m + stat_summary(fun.data = "median_hilow", geom = "smooth") m + stat_summary(fun.y = "mean", geom = "line") m + stat_summary(fun.data = "mean_cl_boot", geom = "smooth") m2 <- ggplot(movies, aes(factor(round(rating)), log10(votes))) m2 + stat_summary(fun.y = "mean", geom = "point") m2 + stat_summary(fun.data = "mean_cl_normal", geom = "errorbar") m2 + stat_summary(fun.data = "median_hilow", geom = "pointrange") m2 + stat_summary(fun.data = "median_hilow", geom = "crossbar")
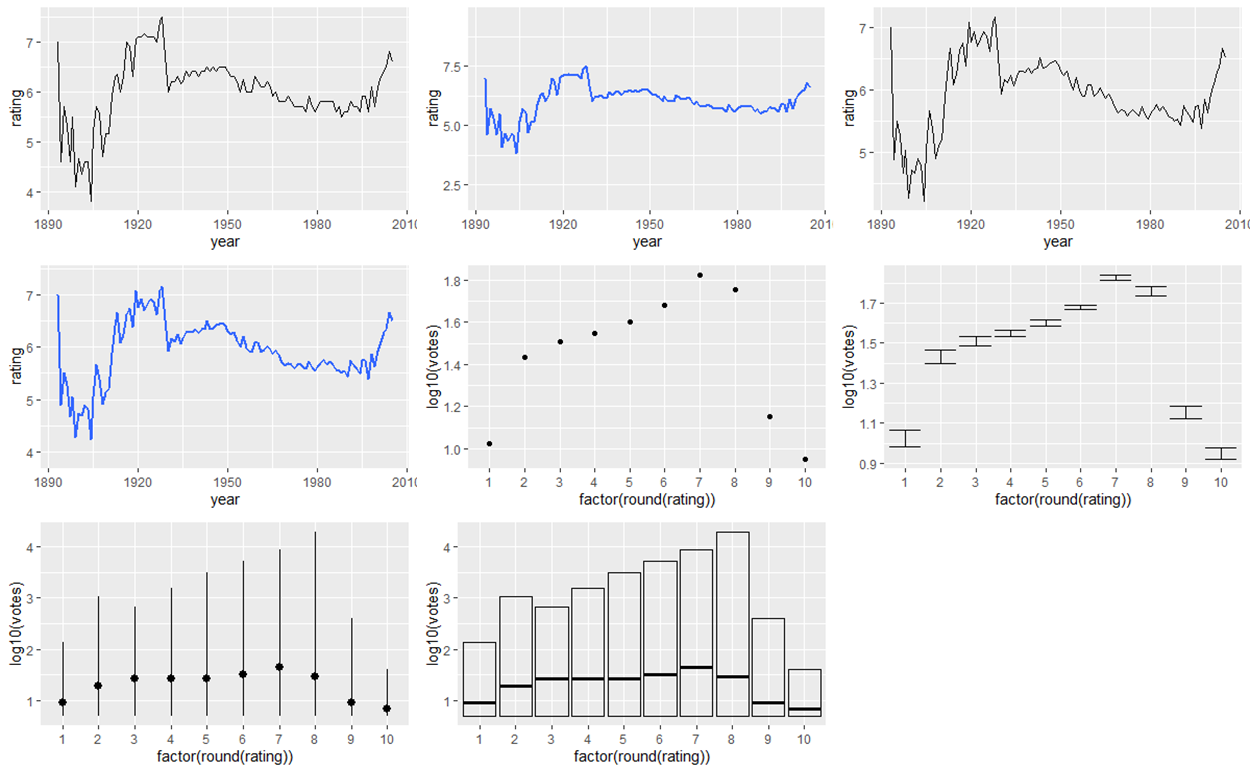
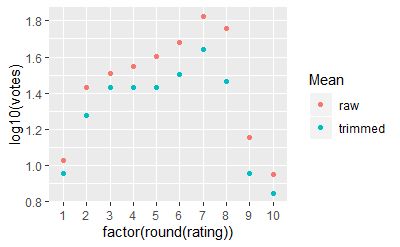
midm <- function(x) mean(x, trim = 0.5)
m2 + stat_summary(aes(colour = "trimmed"), fun.y = midm, geom = "point") +
stat_summary(aes(colour = "raw"), fun.y = mean, geom = "point") + scale_colour_hue("Mean")
iqr <- function(x, ...) {
qs <- quantile(as.numeric(x), c(0.25, 0.75), na.rm = T)
names(qs) <- c("ymin", "ymax")
qs
}
m + stat_summary(fun.data = "iqr", geom = "ribbon")
5.10 添加图形注解
添加图形注解的方式有两种:逐个添加和批量添加。
- geom_text:可添加文字描述或为点添加标签。对于多数图形,为所有观测添加标签是无益的,然而,使用抽取子集的方式为部分观测添加标签可能会非常有用——我们往往希望标出离群点或者其他重要的点。
- geom_vline,geom_hline:向图形添加垂直线或水平线。
- geom_abline:向图形添加任意斜率和截距的直线。
- geom_rect:可强调图形中感兴趣的矩形区域,拥有xmin、xmax、ymin、ymax几种图形属性。
- geom_line,geom_path,geom_segment:都可以添加直线。
以上这些几何对象都有一个arrow参数,可以用来在线上放置箭头。
- arrow:绘制箭头,拥有angle、length、ends、type等参数。
(unemp <- qplot(date, unemploy, data = economics, geom = "line", xlab = "",
ylab = "No. unemployed (1000s)"))

presidential <- presidential[-(1:3), ] yrng <- range(economics$unemploy) xrng <- range(economics$date) unemp + geom_vline(aes(xintercept = as.numeric(start)), data = presidential)

library(scales)
unemp + geom_rect(aes(NULL, NULL, xmin = start, xmax = end, fill = party),
ymin = yrng[1], ymax = yrng[2], data = presidential) +
scale_fill_manual(values = alpha(c("blue", "red"), 0.2))
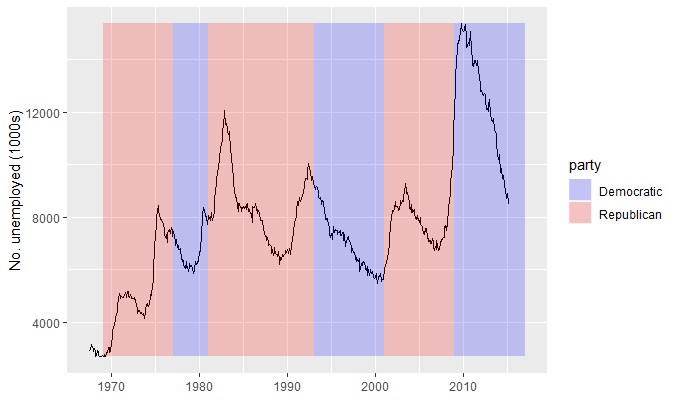
添加民主党和共和党分界。
last_plot() + geom_text(aes(x = start, y = yrng[1], label = name), data = presidential,
size = 3, hjust = 0, vjust = 0)

添加总统信息。
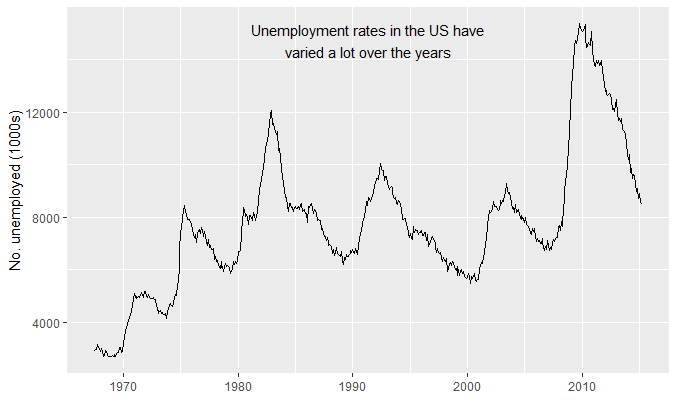
caption <- paste(strwrap("Unemployment rates in the US have\nvaried a lot over the years",
40), collapse = "\n")
unemp + geom_text(aes(x, y, label = caption), data = data.frame(x = mean(xrng),
y = yrng[2]), hjust = 0.5, vjust = 1, size = 4)
highest <- subset(economics, unemploy == max(unemploy))
unemp + geom_point(data = highest, size = 3, colour = alpha("red", 0.5))
5.11 含权数据
在处理整合后的数据时,数据集的每一行可能代表了多种观测值,此时我们需要以某种方式把权重考虑进去。
## 使用点的大小来展示权重
qplot(percwhite, percbelowpoverty, data = midwest)
qplot(percwhite, percbelowpoverty, data = midwest, size = poptotal/1e+06) +
scale_size_area("Population\n(millions)", breaks = c(0.5, 1, 2, 4))
qplot(percwhite, percbelowpoverty, data = midwest, size = area, alpha = I(1/10)) + scale_size_area()
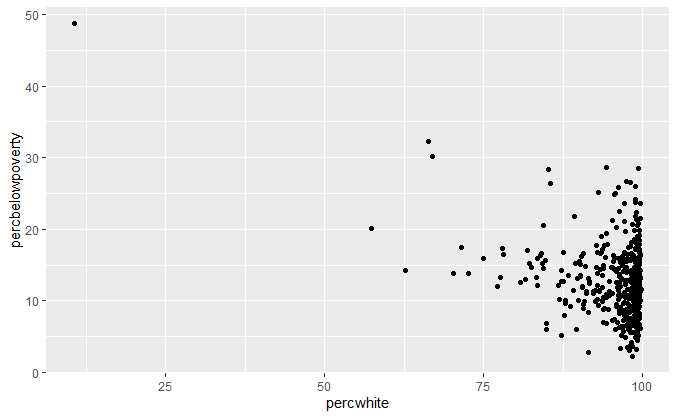

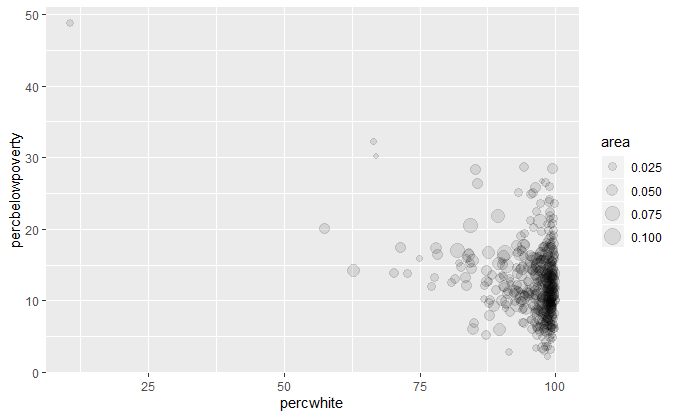
无权重,以人口数量为权重,以面积为权重。
lm_smooth <- geom_smooth(method = lm, size = 1) qplot(percwhite, percbelowpoverty, data = midwest) + lm_smooth qplot(percwhite, percbelowpoverty, data = midwest, weight = popdensity, size = popdensity) + lm_smooth
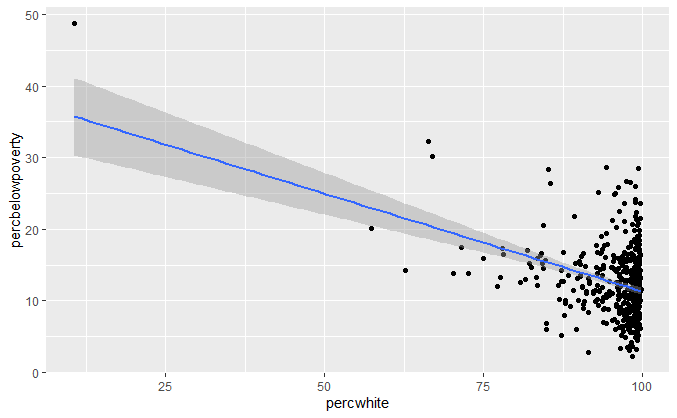
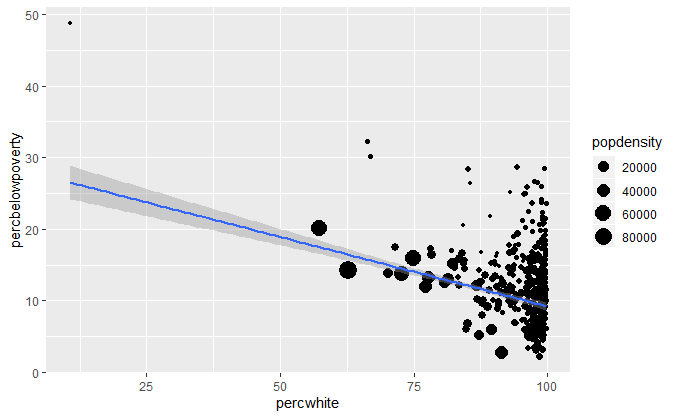
未考虑权重的最优拟合曲线和以人口数量作为权重的最优拟合曲线。
qplot(percbelowpoverty, data = midwest, binwidth = 1)
qplot(percbelowpoverty, data = midwest, weight = poptotal, binwidth = 1) +
ylab("population")

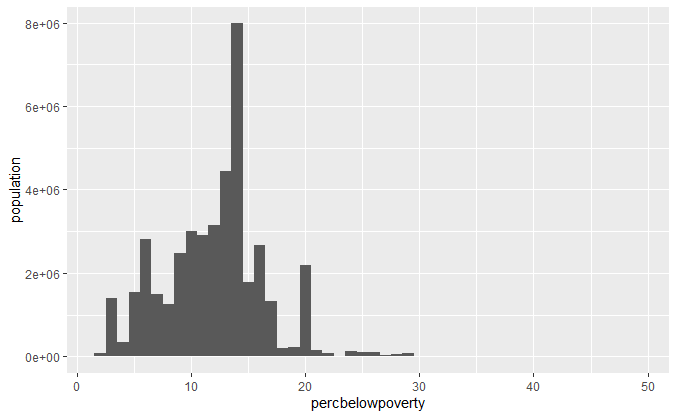
不含权重信息以及含权重信息的直方图。不含权重信息的直方图展示了郡的数量,而含权重信息的直方图展示了人口数量。权重的加入的确极大地改变了对图形的解读!
总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号