ggplot2(2) 从qplot开始入门
2.1 简介
qplot的意思是快速作图(quick plot)。
qplot是一种快捷方式,如果您已习惯于使用基础plot(),则可以使用它。它可以使用一致的调用模式快速创建许多不同类型的图。
qplot(x, y, ..., data, facets = NULL, margins = FALSE, geom = "auto", xlim = c(NA, NA), ylim = c(NA, NA), log = "", main = NULL, xlab = NULL, ylab = NULL, asp = NA, stat = NULL, position = NULL)
- x,y:图中对象的x坐标和y坐标;
- data:可选,用于指定数据框,若进行了指定,那么函数会首先在该数据框内查找变量名,如果没有指定,将创建一个,从当前环境中提取向量;
- facets:用于图形分面;
- margins:逻辑值或字符向量。margins是附加的面;
- geom:指定绘图类型的字符向量。如果指定x和y,默认为“点”;如果指定x,默认为“柱状图”;
- xlim,ylim:x和y坐标边界;
- log:哪些变量要进行对数转换(“x”、“y”或“xy”);
- main:标题;
- xlab,ylab:x和y坐标轴标签;
- asp:y/x的长宽比。
2.2 数据集
> head(diamonds) # A tibble: 6 x 10 carat cut color clarity depth table price x y z <dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
A dataset containing the prices and other attributes of almost 54,000 diamonds. The variables are as follows:
- price: price in US dollars (\$326–\$18,823)
- carat: weight of the diamond (0.2–5.01)
- cut: quality of the cut (Fair, Good, Very Good, Premium, Ideal)(均匀、良好、非常好、优质、理想)
- color: diamond colour, from D (best) to J (worst)
- clarity: a measurement of how clear the diamond is (I1 (worst), SI2, SI1, VS2, VS1, VVS2, VVS1, IF (best))
- x: length in mm (0–10.74)
- y: width in mm (0–58.9)
- z: depth in mm (0–31.8)
- depth: total depth percentage = z / mean(x, y) = 2 * z / (x + y) (43–79)
- table: width of top of diamond relative to widest point (43–95)
> str(diamonds) Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 53940 obs. of 10 variables: $ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ... $ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ... $ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ... $ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ... $ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ... $ table : num 55 61 65 58 58 57 57 55 61 61 ... $ price : int 326 326 327 334 335 336 336 337 337 338 ... $ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ... $ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ... $ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
可以看到cut、color、clarity为有序分类变量。
抽样:(方便观察,加快运算速度)
set.seed(1410) # 让样本可重复 dsmall <- diamonds[sample(nrow(diamonds), 100), ]
2.3 基本用法
绘制散点图。
qplot(carat, price, data = diamonds)

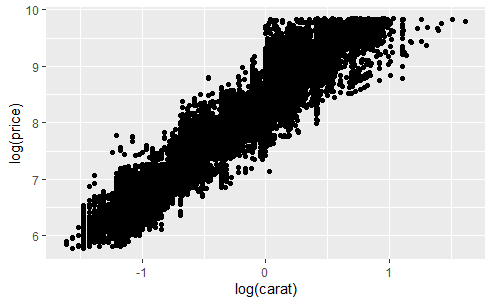
对数变换(对坐标系进行变换,并没有改变变量的值)。
qplot(carat, price, data = diamonds, log = 'xy')
2.4 颜色、大小、形状和其他图形属性
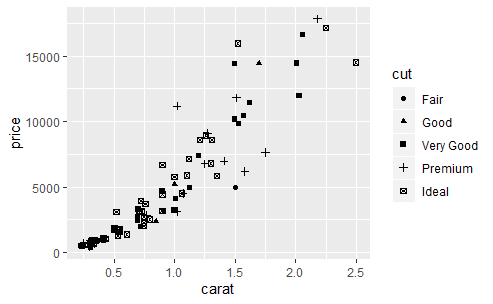
自动向重量和价格的散点图中添加颜色和切工的信息。
qplot(carat, price, data = dsmall, colour = color) qplot(carat, price, data = dsmall, shape = cut)

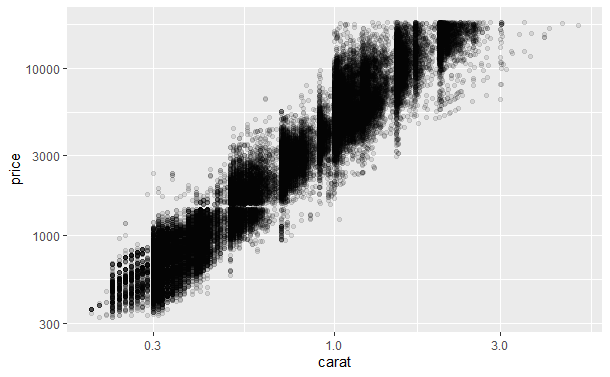
不透明度选择,在数据量很大时,太多的点重合,影响观察,使用半透明的颜色可以有效减轻图形元素重叠的现象,观察数据集聚趋势,alpha值可以设定不透明度,取值从0(完全透明)到1(完全不透明),通常用分数来表示,例如1/10或1/20,其分母表示经过多少次重叠之后颜色将变得不透明。
qplot(carat, price, data = diamonds, log = 'xy', alpha = I(1/10))
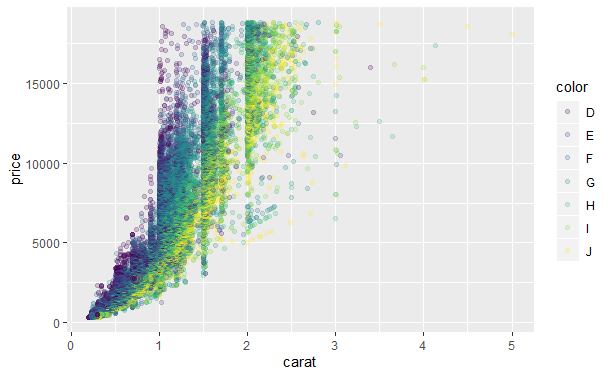
qplot(carat, price, data = diamonds, colour = color, alpha = I(1/5))
2.5 几何对象
二维对象:
- geom = "point":绘制散点图;
- geom = "smooth":拟合一条平滑曲线,并将标准误展示在图中,如果不需要展现标准误可以使用se = FALSE;
- geom = "boxplot":绘制箱线图,用以概括一系列点的分布情况;
- geom = "jitter":绘制扰动点图;
- geom = "path"或geom = "line":可以在数据点之间绘制连线,这类图形的作用是探索时间和其他变量之间的关系,但连线同样可以用其他的方式将数据点连接起来,线条图只能创建从左到右的连线,而路径图则可以使任意的方向。
一维对象:
- geom = "histogram":绘制直方图;
- geom = "freqpoly":绘制频率多边形;
- geom = "density":绘制密度曲线;
- geom = "bar:对离散变量绘制条形图。
2.5.1 向图中添加平滑曲线
使用c()将多个对象传递给geom,几何对象会按照指定的顺序进行堆叠。
qplot(carat, price, data = dsmall, geom = c("point", "smooth"))
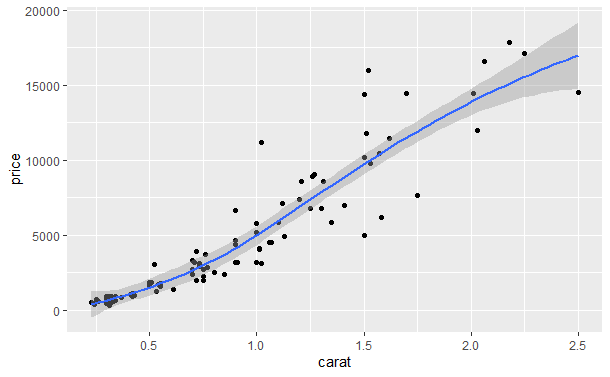
利用method参数可以选择不同的平滑器。
- method = "loess"使用的是局部回归方法,在当n较小是是默认选项,其平滑程度由span控制,取值范围为0(很不平滑)到1(很平滑)。Loess对于大数据并不合适,因为其内存消耗是$O(n^{2})$。
- 使用method = "gam", formula = y ~ s(x)可以调用mgcv包拟合一个广义可加模型。对于大数据应使用y ~ s(x, bs = "cs")。
library(mgcv)
qplot(carat, price, data = dsmall, geom = c("point", "smooth"), method = "gam", formula = y ~ s(x))
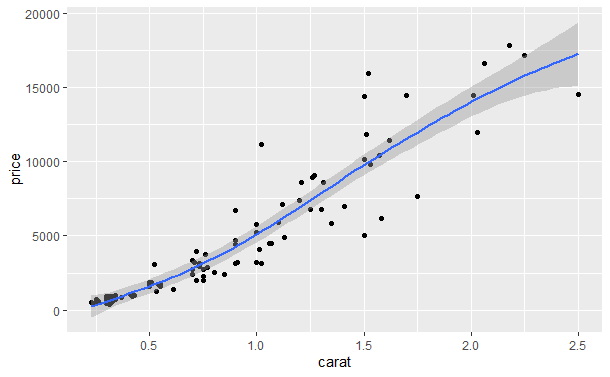
- method = "lm"拟合的是线性模型,默认得到一条直线,但可以通过formula = y ~ poly(x, 2)来拟合一个二次多项式。
qplot(carat, price, data = dsmall, geom = c("point", "smooth"), method = "lm")
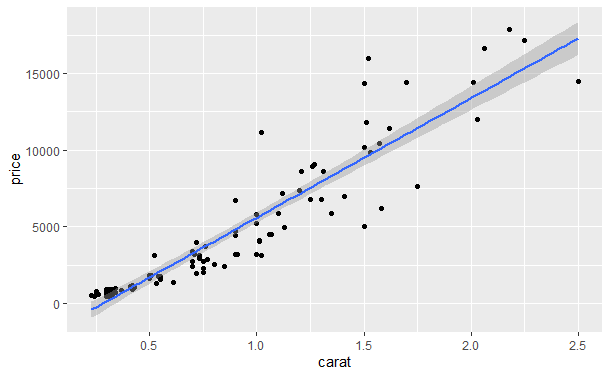
- method = "rlm"与"lm"类似,但采用了一种更为稳健的拟合方法,使得结果对异常值不太敏感,这一方法是MASS包的一部分,因此使用时需要先加载MASS包。
2.5.2 箱线图和扰动点图
qplot(color, price/carat, data = diamonds, geom = "jitter", alpha = I(1/30)) qplot(color, price/carat, data = diamonds, geom = "boxplot")

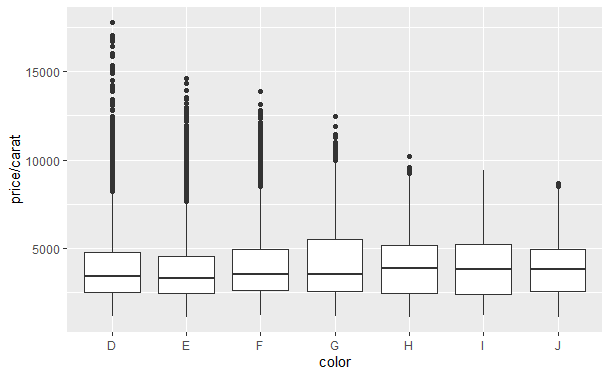
每种方法都有它的优势和不足,箱线图只用了5个数字进行描述,更具概括性;扰动点图绘制了全部点,更具全面性。
2.5.3 直方图和密度曲线图
直方图和密度曲线图可以展现单个变量的分布,相对于箱线图而言,它们提供了更多的关于单个变量分布的信息,但它们不太容易在不同组之间进行比较。
qplot(carat, data = diamonds, geom = "histogram") qplot(carat, data = diamonds, geom = "density")


对于密度曲线而言,adjust参数控制了曲线的平滑程度(adjust取值越大,曲线越平滑);对于直方图,binwidth参数通过设置组距来调节平滑度,或者也可以使用breaks对切分位置进行显示的指定。
在直方图中,应当尝试多种组距:组距较大时图形能够反应总体特性;组距较小时,则能显示出更过细节。
要在不同的分组之间进行比较,只需在加上一个图形映射。
qplot(carat, data = diamonds, geom = "density", colour = color) qplot(carat, data = diamonds, geom = "histogram", fill = color)
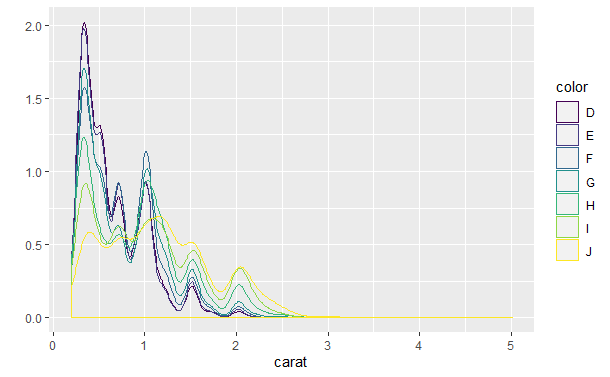
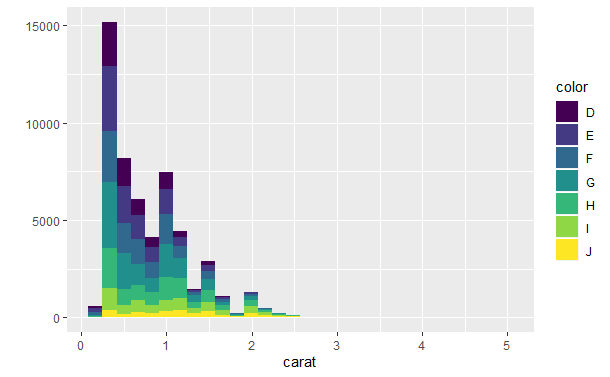
密度曲线图似乎更吸引人,因为很容易阅读,而且适于在不同的曲线之间进行比较。然而要真正理解密度曲线则比较困难,而且密度曲线有一些隐含的假设,例如曲线应该是无界、连续和平滑的,这些假设不一定适用于真实的数据。
2.5.4 条形图
用于绘制离散变量,与直方图类似。条形图会计算每一个水平下观测的数量。使用weight可以进行加权。
qplot(color, data = diamonds, geom = "bar")
qplot(color, data = diamonds, geom = "bar", weight = carat) + scale_y_continuous("carat")

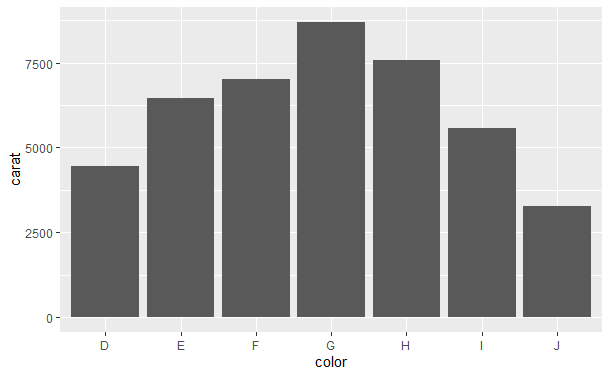
第一幅图展现了分组的计数,第二幅图展现了没中颜色钻石的总重量。
2.5.5 时间序列中的线条图和路径图
线条图和路径图用于可视化时间序列数据。线条图将点从左到右进行连接,而路径图则按照点在数据集中的顺序进行连接。线条图的x轴一般是时间,它展现了单个变量随时间的变化情况;路径图则展现了两个变量随时间联动的情况,时间反映在点的连接顺序上。
数据集:economics
> head(economics) # A tibble: 6 x 6 date pce pop psavert uempmed unemploy <date> <dbl> <dbl> <dbl> <dbl> <dbl> 1 1967-07-01 507. 198712 12.6 4.5 2944 2 1967-08-01 510. 198911 12.6 4.7 2945 3 1967-09-01 516. 199113 11.9 4.6 2958 4 1967-10-01 512. 199311 12.9 4.9 3143 5 1967-11-01 517. 199498 12.8 4.7 3066 6 1967-12-01 525. 199657 11.8 4.8 3018
该数据集来自美国经济时间序列数据。
- date:数据收集月份
- psavert:个人储蓄率
- pce:个人消费支出
- unemploy:失业人数(以千计)
- uempmed:失业持续时间的中位数,以周为单位。
- pop:总人口,以千为单位
绘制时间序列线条图。(失业率)
qplot(date, unemploy/pop, data = economics, geom = "line")
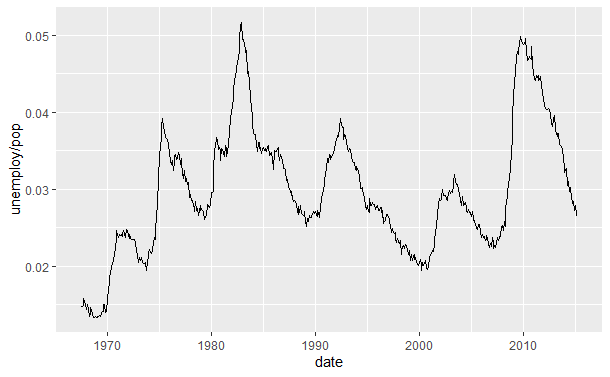
绘制路径图(失业率&失业持续时间)。将时间date映射到colour属性上更容易看出时间的行进方向。
qplot(unemploy/pop, uempmed, data = economics, geom = c("point", "path"), colour = date)

2.6 分面
分面将数据分隔成若干子集,然后创建一个图形的矩阵,将一个子集绘制到矩阵的窗格中。
通过row_var ~ col_var的表达式进行指定,如果指向指定一行或者一列,可以使用 . 作为占位符。
qplot(carat, data = diamonds, facets = color ~ ., geom = "histogram", binwidth = 0.1,
xlim = c(0, 3))
qplot(carat, ..density.., data = diamonds, facets = color ~ cut, geom = "histogram",
binwidth = 0.1, xlim = c(0, 3))
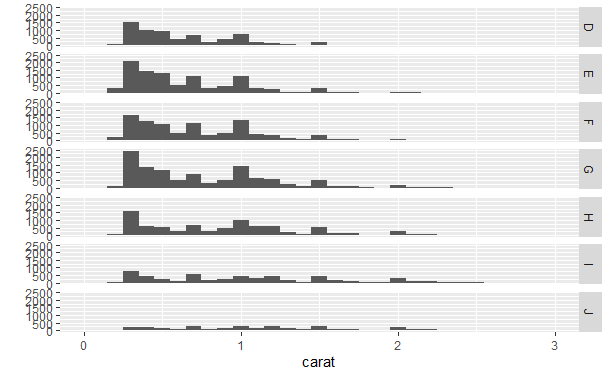
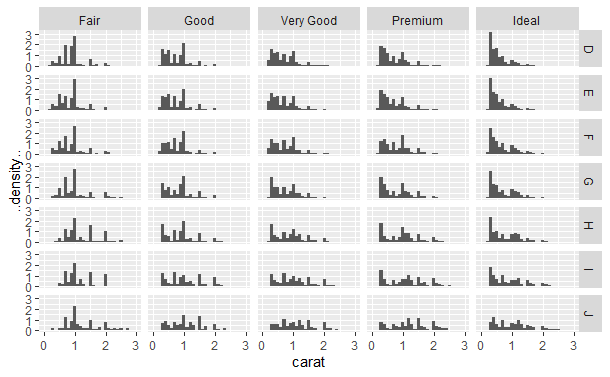
..density..告诉ggplot2将密度而不是频数映射到y轴。
2.7 与plot函数的区别
- qplot不是泛型函数,当将不同类型的R对象传入qplot时,它并不会自动匹配默认的函数调用。ggplot()是一个泛型函数;
- gglpot2中的图形属性名称如colour、shape和size等比基础绘图系统中的名称如col、pch、cex等更直观,容易记忆;
- 在基础绘图系统中,可以通过points()、lines()和text()函数来向已有的图形中添加更多的元素,而在ggplot2中,你需要在当前的图形中加入额外的图层。
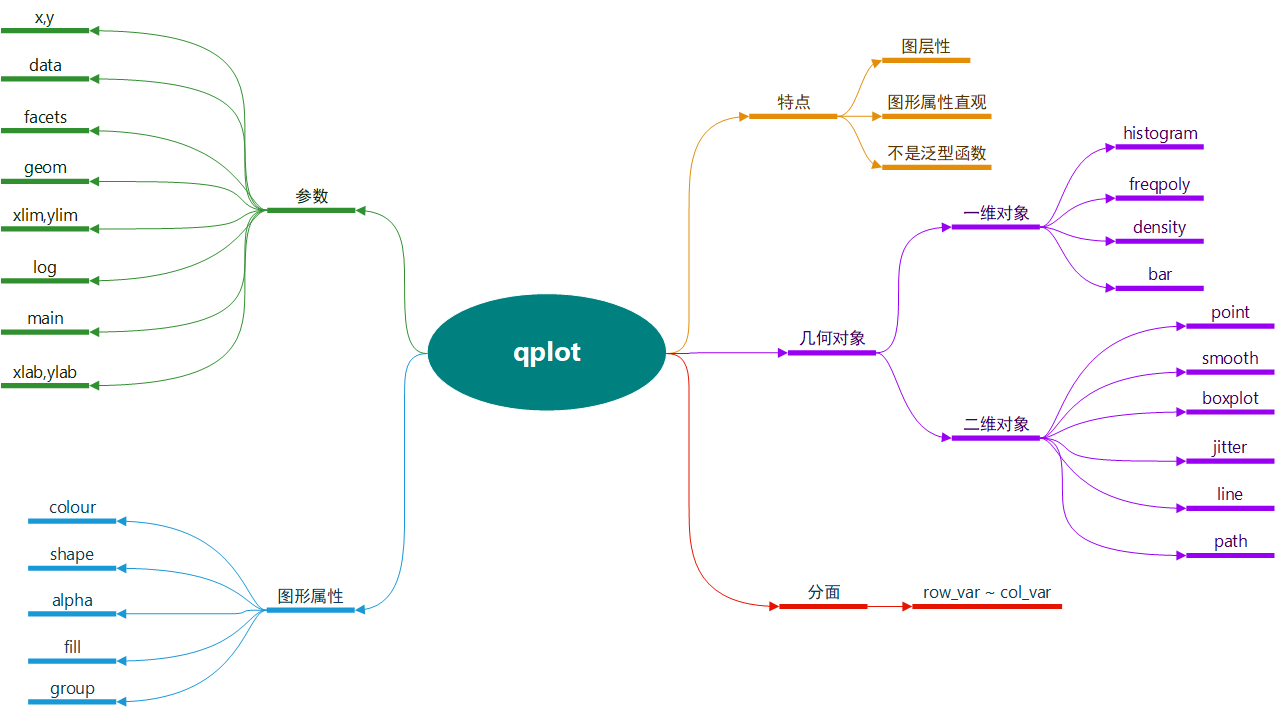
总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号