MATLAB神经网络(5) 基于BP_Adaboost的强分类器设计——公司财务预警建模
5.1 案例背景
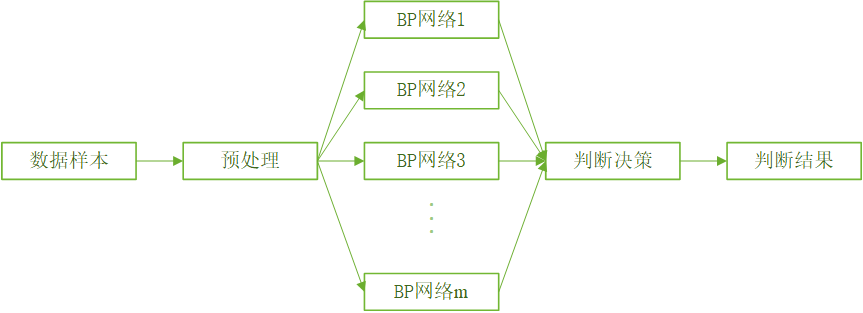
5.1.1 BP_Adaboost模型
Adaboost算法的思想是合并多个“弱”分类器的输出以产生有效分类。其主要步骤为:首先给出弱学习算法和样本空间($X$,$Y$),从样本空间中找出$m$组训练数据,每组训练数据的权重都是$\frac{1}{m}$。然后用弱学习算法迭代运算$T$次,每次运算后都按照分类结果更新训练数据权重分布,对于分类失败的训练个体赋予较大权重,下次迭代运算时更加关注这些训练个体。弱分类器通过反复迭代得到一个分类函数序列${f_1},{f_2},...,{f_T}$,每个分类函数赋予一个权重,分类结果越好的函数,其对应权重越大。$T$次迭代之后,最终强分类函数$F$由弱分类函数加权得到。BP_Adaboost模型即BP神经网络作为弱分类器,反复训练BP神经网络预测样本输出,通过Adaboost算法得到多个BP神经网络弱分类器组成的强分类器。
5.1.2 公司财务预警系统介绍
公司财务预警系统是为了防止公司财务系统运行偏离预期目标而建立的报警系统,具有针对性和预测性等特点。它通过公司的各项指标综合评价并预测公司财务状况、发展趋势和变化,为决策者科学决策提供智力支持。
评价指标:成分费用利润率、资产营运能力、公司总资产、总资产增长率、流动比率、营业现金流量、审计意见类型、每股收益、存货周转率和资产负债率
5.2 模型建立
算法步骤如下:
- 数据初始化和网络初始化。从样本空间中随机选择$m$组训练数据,初始化测试数据的分布权值${D_t}(i) = \frac{1}{m}$,根据样本输入输出维数确定神经网络结构,初始化BP神经网络权值和阈值。
- 若分类器预测。训练第$t$个弱分类器时,用训练数据训练BP神经网络并且预测训练数据输出,得到预测序列$g(t)$的预测误差$e_{t}$,误差和$e_{t}$的计算公式为\[{e_t} = \sum\limits_i {{D_t}(i)} \;\;\;i = 1,2, \ldots ,m(g(t) \ne y)\]
- 计算预测序列权重。根据预测序列$g(t)$的预测误差$e_{t}$计算序列的权重$a_{t}$,权重计算公式为\[{a_t} = \frac{1}{2}\ln \left( {\frac{{1 - {e_t}}}{{{e_t}}}} \right)\]
- 测试数据权重调整。根据预测序列权重$a_{t}$挑中下一轮训练样本的权重,调整公式为\[{D_{t + 1}}(i) = \frac{{{D_t}(i)}}{{{B_t}}} \cdot {e^{ - {a_t}{y_i}{g_t}({x_i})}}\;\;\;i = 1,2, \ldots ,m\]式中,$B_{t}$为归一化因子,目的是在权重比例不变的情况下使分布权值和为1。
- 强分类函数。训练$T$轮后得到$T$组弱分类函数$f(g_{t},a_{t})$,由$T$组弱分类函数组合得到了强分类函数\[h(x) = {\rm{sign}}[\sum\limits_{t = 1}^T {{a_t} \cdot f({g_t},{a_t})} ]\]
5.3 编程实现
5.3.1 载入数据(初始化)
%% 基于BP-Adaboost的强分类器分类
%% 清空环境变量
clc
clear
%% 加载数据
load('data.mat')
%% 权重初始化
[mm,nn]=size(input_train);
D(1,:)=ones(1,nn)/nn;
5.3.2 弱分类器训练
%% 弱分类器分类
K=30;
for i=1:K
%训练样本归一化
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
error(i)=0;
%BP神经网络构建
net=newff(inputn,outputn,[15,8]);
net.trainParam.epochs=20;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00004;
%BP神经网络训练
net=train(net,inputn,outputn);
%训练数据预测
an1=sim(net,inputn);
test_simu1(i,:)=mapminmax('reverse',an1,outputps);
%测试数据预测
inputn_test =mapminmax('apply',input_test,inputps);
an=sim(net,inputn_test);
test_simu(i,:)=mapminmax('reverse',an,outputps);
%统计输出效果
kk1=find(test_simu1(i,:)>0);
kk2=find(test_simu1(i,:)<0);
aa(kk1)=1;
aa(kk2)=-1;
%统计错误样本数
for j=1:nn
if aa(j)~=output_train(j)
error(i)=error(i)+D(i,j);
end
end
%弱分类器i权重
at(i)=0.5*log((1-error(i))/error(i));
%更新D值
for j=1:nn
D(i+1,j)=D(i,j)*exp(-at(i)*aa(j)*test_simu1(i,j));
end
%D值归一化
Dsum=sum(D(i+1,:));
D(i+1,:)=D(i+1,:)/Dsum;
end
5.3.3 统计结果
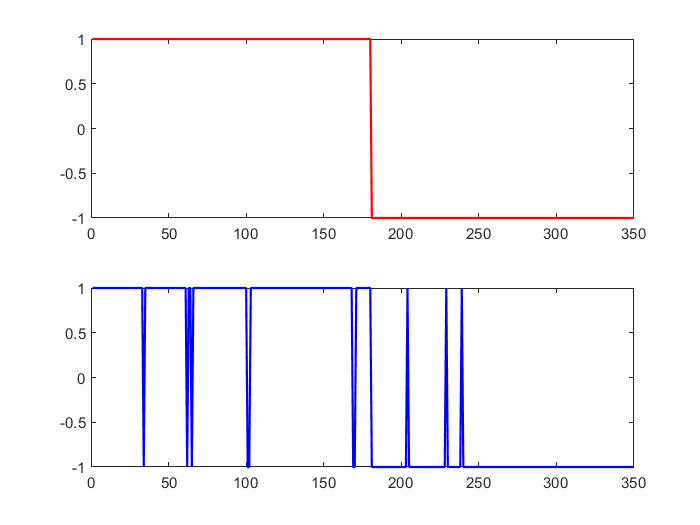
%% 强分类器分类结果 output=sign(at*test_simu); %% 分类结果统计 [tbl,chi2,p]=crosstab(output,output_test)

subplot(2,1,1) plot(output_test,'r',"LineWidth",1.3) subplot(2,1,2) plot(output,'b',"LineWidth",1.3)
%统计强分类器分类效果 error_q=(tbl(1,2)+tbl(2,1))/sum(sum(tbl)); error_q
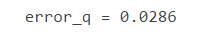
%统计弱分离器效果
for i=1:K
kk1=find(test_simu(i,:)>0);
kk2=find(test_simu(i,:)<0);
bb(kk1)=1;
bb(kk2)=-1;
[tbl1,~,~]=crosstab(bb,output_test);
error_r(i)=(tbl1(1,2)+tbl1(2,1))/sum(sum(tbl));
end
%统计弱分类器分类效果
error_r

mean(error_r)

5.4 强预测器
与强分类器设计方法类似,都是先赋予测试样本权重,然后根据弱预测器预测结果调整测试样本权重并确定弱预测器权重,最后把弱预测器序列加权作为强预测器。不同的是在强分类器中增加预测类别错误的样本的权重,在强预测器中增加预测误差超过阈值的样本的权重。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号