正则表达式必知必会
 正则表达式学习笔记,欢迎批评指正!
学习资源:正则表达式必知必会(人民邮电出版社)
资源:
链接:https://pan.baidu.com/s/1ET9K_AXMK-Nfy_zIlDjt7g
提取码:n072
正则表达式学习笔记,欢迎批评指正!
学习资源:正则表达式必知必会(人民邮电出版社)
资源:
链接:https://pan.baidu.com/s/1ET9K_AXMK-Nfy_zIlDjt7g
提取码:n072
资源:
- 链接:https://pan.baidu.com/s/1ET9K_AXMK-Nfy_zIlDjt7g
- 提取码:n072
注:本文所用正则表达式查找替换工具为notepad++
第一章 正则表达式入门
正则表达式(regular expression),一种工具。
用途:查找特定的信息(搜索);查找并编辑特定的信息(替换)。
正则表达式是一些用来匹配和处理文本的字符串,是由正则语言创建的。
正则表达式语言并不是一种完备的程序设计语言,甚至算不上一种能够直接安装并运行的程序。正则表达式是一种内置于其他语言或软件产品中的“迷你”语言。
第二章 匹配单个字符
1.纯文本正则表达式
【文本】
Hello, my name is Ben. Please visit
my website at http://www.forta.com/

正则表达式是大小写敏感的
![]()
通过某些条件可以指定不区分字母大小写的匹配操作
2.匹配任意字符
.字符可以匹配任意一个单个的字符
【文本】
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
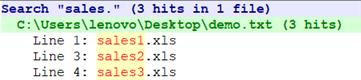
\为转义字符,作用是告诉正则表达式我们需要的是.字符本身,而不是其在正则语言中的特殊含义
第三章 匹配一组字符
1.字符集合
【文本】
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
使用元字符[和]可以定义一个字符集合
[大写字母+小写字母]用于局部不区分大小写的匹配
【文本】
The phrase \'regular expression\' is often
abbreviated as RegEx or regex

2.字符集合区间
【文本】
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
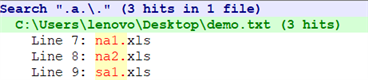
数字集合用于过滤sam.xls
正则表达式提供了一个特殊的元字符——字符区间可以用-(连字符)来定义
如[A-Z],[a-z],[0-9],[A-Za-z0-9]
字符区间的首、尾字符可以是ASCII字符表中的任意字符,但在实际中常用的只有上面的示例

【文本】
<BODY BGCOLOR=\'#336633\' TEXT=\'#FFFFFF\'
MARGINWIDTH=\'0\' MARGINHEIFHT=\'0\'
TOPMARGI\'0\' LEFTMARGIN=\'0\'>
匹配一个RGB色彩值

3.取非匹配
【文本】
sales1.xls
orders3.xls
sales2.xls
sales3.xls
apac1.xls
europe2.xls
sam.xls
na1.xls
na2.xls
sa1.xls
ca1.xls
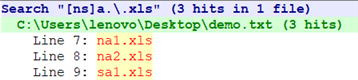
^可以进行取非操作,这与逻辑非很相似
![]()
第四章 使用元字符
1.对特殊字符进行转义
【文本】
var myArray = new Array();
...
if (myArray[0] == 0){
...
}
![]()
任何一个元字符都可以通过给它加上一个反斜杠字符(\)作为前缀的办法来转义
![]()
【文本】
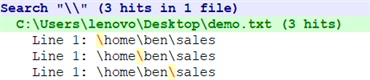
\home\ben\sales
\字符也是一个元字符,在需要匹配\本身的时候,我们必须把它转义为\\
2.匹配空白字符
| [\b] | 回退(并删除)一个字符 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \v | 垂直制表符 |
【文本】
"101","Ben","Forta"
"102","Jim","James"
"103","Roberta","Robertson"
"104","Bob","Bobson"
\r\n匹配一个“回车+换行”组合,\r\n\r\n可以匹配空白行
![]()
3.匹配特定的字符类别
| \d | 任何一个数字字符[0-9] |
| \D | 任何一个非数字字符[^0-9] |
| \w | 任何一个字母数字字符或下划线字符[a-zA-Z0-9_] |
| \W | [^a-zA-Z0-9_] |
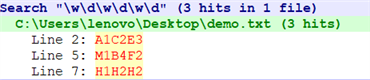
【文本】
11213
A1C2E3
48075
48237
M1B4F2
90046
H1H2H2
匹配加拿大城市的邮政编码
| \s | 任何一个空白字符[\f\n\r\t\v] |
| \S | [^\f\n\r\t\v] |
4.使用十六进制值和八进制值
十六进制值要用前缀\x来给出——\x0A对应于ASCII字符10,效果等价于\n
八进制值要用前缀\0来给出——\011对应于ASCII字符9,效果等价于\t
5.POSIX字符类
| [:digit:] | 任何一个数字[0-9] |
| [:alpha:] | 任何一个字母[a-zA-Z] |
| [:upper:] | 任何一个大写字母[A-Z] |
| [:lower:] | 任何一个小写字母[a-z] |
| [:alnum:] | 任何一个字母或数字[a-zA-Z0-9] |
| [:space:] | 任何一个空白字符(含空格)[\f\n\r\t\v ] |
| [:blank:] | 空格或制表符[\t ] |
| [:cntrl:] | ASCII控制字符(ASCII0到31,再加上ASCII127) |
| [:print:] | 任何一个可打印字符 |
| [:graph:] | 不包括空格的可打印字符 |
| [:punct:] | 既不属于[:alnum:]也不属于[:cntrl:]的任何一个字符 |
| [:xdigit:] | 任何一个十六进制数字[a-fA-F0-9] |
【文本】
<BODY BGCOLOR=\'#336633\' TEXT=\'#FFFFFF\'
MARGINWIDTH=\'0\' MARGINHEIFHT=\'0\'
TOPMARGI\'0\' LEFTMARGIN=\'0\'>
匹配一个RGB色彩值

外层的[和]用来定义一个字符集合,内层的[和]字符是POSIX字符类本身的组成部分
第五章 重复匹配
1.一次或多次重复
要想匹配同一个字符的多次重复,只要给这个字符后加上一个+字符作为后缀就行了。
使用+可以匹配一个或多个字符(+是一个元字符,匹配+本身需要转义)
【文本】
Send personal email to ben@forta.com. For questions
about a book use support@forta.com. Feel free to send
unsolicited email to spam@forta.com (wouldn't it be
nice if it were that simple, huh?).

【文本】
Send personal email to ben@forta.com or
ben.forta@forta.com. For questions about a
book use support@forta.com. If your message
is urgent try ben@urgent.forta.com. Feel
free to send unsolicited email to
spam@forta.com (wouldn't it be
nice if it were that simple, huh?).
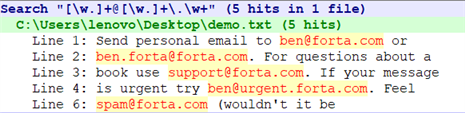
当在字符集合里使用的时候,像.和+这样的元字符将被解释为普通字符,可以不必转义。
2.零次或多次重复
*的用法与+完全一样
【文本】
Hello .ben@forta.com is my email address.
使用*,排除原文中多加了一个.的错误。
![]()
3.零次或一次出现
?只能匹配一个字符的零次或一次出现
【文本】
The URL is http://www.forta.com/, to connect
securely use https://www.forta.com/ instead.

4.设定匹配的重复次数
重复次数要用{和}来给出——把数值写在它们之间({和}是元字符)
还可以使用,来分割最小次数和最大次数
| {6} | 重复6次 |
| {2,4} | 最少重复2次,最多重复4次 |
| {3,} | 至少重复3次 |
【文本】
4/8/03
10-6-2004
2/2/2
01-01-01

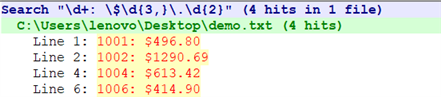
【文本】
1001: $496.80
1002: $1290.69
1003: $26.43
1004: $613.42
1005: $7.61
1006: $414.90
1007: $25.00
查找大于100美元的记录
5.防止过度匹配
【文本】
This offer is not available to customers
living in <B>AK</B> and <B>HI</B>.
![]()
因为*和+都是所谓的“贪婪型”元字符,它们在进行匹配时的行为模式是多多益善而不是适可而止的。
| 贪婪型元字符 | 懒惰型元字符 |
| * | *? |
| + | +? |
| {n,} | {n,}? |

第六章 位置匹配
1.单词边界
【文本】
The cat scattered his food all over the room.

限定符\b可以指定单词边界,用来匹配一个单词的开始或结尾。(b——boundary)
实际上,\b匹配的是这样一个位置,这个位置位于一个能够用来构成单词的字符(字母、数字和下划线,即与\w匹配的字符)和一个不能用来构成单词的字符(\W)之间。
![]()
【文本】
The captain wore his cap and cape proudly as
he sat listening to the recap of how his
crew saved the men from a capsized vessel.
搜索以cap开头或结尾的单词。

\B可以匹配非单词边界
即字母数字下划线之间,或者非字母数字下划线之间
2.字符串边界
| ^ | 用来定义字符串开头 |
| $ | 用来定义字符串结尾 |
【文本】
<?xml version="1.0" encoding="UTF-8" ?>
<wsdl:definitions targetNamespace="http://tips.cf"
xmlns:impl="http://tips.cf" xmlns:intf="http://tips.cf"
xmlns:apachesoap="http://xml.apache.org/xml-soap"
![]()
3.分行匹配模式
分行匹配模式((?m))将使得正则表达式引擎把行分隔符当做一个字符串分隔符来对待。
在这种模式下,^不仅能匹配正常的字符串开头,还将匹配换行符后面的开始位置。
$不仅能匹配正常的字符串结尾,还将匹配换行符后面的结束位置。
注意,(?m)必须出现在整个模式的最前面。
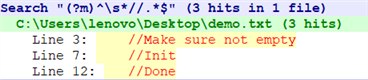
【文本】
<SCRIPT>
function doSpellCheck(form, field){
//Make sure not empty
if(field.value == ''){
return false;
}
//Init
var windowName='spellWindow';
var
spellCheckURL='spell.cfm?formname=comment&fieldname='+field.name;
...
//Done
return false;
}
</SCRIPT>
找出程序中的每一条注释
第七章 使用子表达式
1.子表达式
子表达式是一个更大的表达式的一部分,把一个表达式划分为一系列子表达式的目的是为了把那些子表达式当做一个独立元素来使用。子表达式必须用(和)括起来。
【文本】
Hello, my name is Ben Forta, and I am
the author of books on SQL, ColdFusion, WAP,
Windows 2000, and other subjects.
匹配连续出现两次及以上的非换行空格

【文本】
Pinging hog.forta.com [12.159.46.200]
with 32 bytes of data;
匹配IP地址
![]()
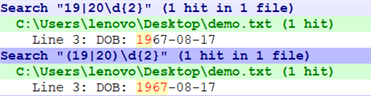
【文本】
ID: 042
SEX: M
DOB: 1967-08-17
Status: Active
匹配年份。
|为或运算符
2.子表达式的嵌套
子表达式允许多重嵌套,但在实际工作中应当适可而止。
把必须匹配的情况考虑周全,并写出一个匹配结果符合预期的正则表达式很容易,但把不需要匹配的情况也考虑周全,并确保它们都将被排除在匹配结果以外,往往要困难的多!
IP地址的准确匹配:(0~255)
- 任何一个1位或2位数字
- 任何一个以1开头的3位数字
- 任何一个以2开头、第2位数字在0~4之间的3位数字
- 任何一个以25开头、第三位数字在0~5之间的3位数字
原书:(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))
改进:(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((25[0-5])|(2[0-4]\d)|(1\d{2})|(\d{1,2}))
【文本】
Pinging hog.forta.com [12.159.46.200]
with 32 bytes of data;

第八章 回溯引用:前后一致匹配
1. 回溯引用
回溯引用允许正则表达式模式引用前面的匹配结果。
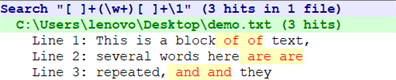
【文本】
This is a block of of text,
several words here are are
repeated, and and they
should not be.
找出文本中重复了两遍的单词。(打字错误)
\1是一个回溯引用,它引用的正是前面()中划分出来的那个子表达式。
【文本】
<BODY>
<H1>Welcome to my Homepage</H1>
Content is divided into two sections:<BR>
<H2>ColdFusion</H2>
Information about Macromedia ColdFusion.
<H2>Wireless</H2>
Information about Bluetooth, 802.11, and more.
<H2>This is not valid HTML</H3>
</BODY>
匹配各级标题。

2. 回溯引用用来替换
【文本】
Hello .ben@forta.com is my email address.
将原始文本中的电子邮件地址转换为可点击的链接。

【结果】
Hello .<A HREF="mailto:ben@forta.com">ben@forta.com</A> is my email address.
【文本】
313-555-1234
248-555-9999
810-555-9000
将电话号码重新排版为所需的格式。

【结果】
(313) 555-1234
(248) 555-9999
(810) 555-9000
3.大小写转换
| \l | 把下一个字符转换为小写 |
| \u | 把下一个字符转换为大写 |
| \L | 把\L和\E之间的字符全部转换为小写 |
| \U | 把\U和\E之间的字符全部转换为大写 |
| \E | 结束\L或\U转换 |
【文本】
<BODY>
<H1>Welcome to my Homepage</H1>
Content is divided into two sections:<BR>
<H2>ColdFusion</H2>
Information about Macromedia ColdFusion.
<H2>Wireless</H2>
Information about Bluetooth, 802.11, and more.
<H2>This is not valid HTML</H3>
</BODY>
把一级标题的文字转换为大写。

【结果】
<BODY>
<H1>WELCOME TO MY HOMEPAGE</H1>
Content is divided into two sections:<BR>
<H2>ColdFusion</H2>
Information about Macromedia ColdFusion.
<H2>Wireless</H2>
Information about Bluetooth, 802.11, and more.
<H2>This is not valid HTML</H3>
</BODY>
第九章 前后查找
1. 前后查找
有时我们使用正则表达式除了匹配文本,还需要标记匹配的文本的位置(而不仅仅是文本本身)。这就需要用前后查找对某一位置的前、后内容进行查找)。
向前查找指定了一个必须匹配但不在结果中返回的模式。向前查找是一个以?=开头的子表达式,需要匹配的文本跟在=的后面。
【文本】
http://www.forta.com/
https://mail.forta.com/
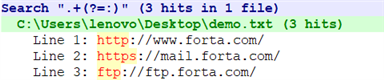
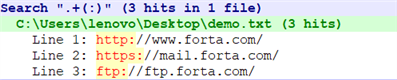
向后查找操作符是?<=
【文本】
ABC01: $23.45
HGG42: $5.31
CFMX1: $899.00
XTC99: $69.96
Total items found: 4
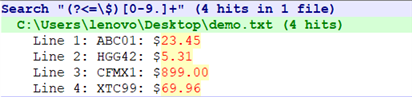
向前查找模式的长度是可变的,它们可以包含.和+之类的元字符,所以非常灵活。
而向后查找模式只能是固定长度,几乎所有的正则表达式都遵守这一限制。
【文本】
<HEAD>
<TITLE>Ben Forta's Homepage</TITLE>
</HEAD>
查找标题内容——结合使用向前和向后模式。
![]()
2.对前后查找取非
负向前查找:向前查找不与给定模式相匹配的文本
负向后查找:向后查找不与给定模式相匹配的文本
| (?=) | 正向前查找 |
| (?!) | 负向前查找 |
| (?<=) | 正向后查找 |
| (?<!) | 负向后查找 |
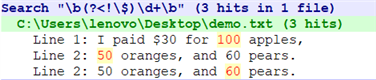
【文本】
I paid $30 for 100 apples,
50 oranges, and 60 pears.
I saved $5 on this order.
只匹配数量,而不匹配价格。
第十章 嵌入条件
1. 嵌入条件
正则表达式还有一个威力强大的功能——在表达式的内部嵌入条件处理功能。
正则表达式里的条件要用?来定义。
嵌入条件使用的两种情况:
根据一个回溯引用来进行条件处理
根据一个前后查找来进行条件处理
【文本】
<!-- Nav bar -->
<TD>
<A HREF="/home"><IMG SRC="/images/home.gif"></A>
<IMG SRC="/images/spacer.gif">
<A HREF="/search"><IMG SRC="/images/search.gif"></A>
<IMG SRC="/images/spacer.gif">
<A HREF="/help"><IMG SRC="/images/help.gif"></A>
</TD>
把文本中的<IMG>标签全部找出来,如果某个<IMG>标签是一个链接的话,匹配整个链接标签。
(<[Aa]\s+[^>]+>\s*)?<[Ii][Mm][Gg]\s+[^>]+>(?(1)\s*</[Aa]>)

【文本】(第1条和第2条是正确的格式)
123-456-7890
(123)456-7890
(123)-456-7890
(123-456-7890
1234567890
123 456 7890
查找格式符合要求的电话号码。

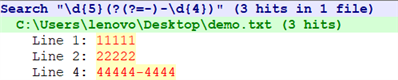
2.前后查找条件
前后查找条件只在一个向前查找或向后查找取得成功的情况下才允许一个表达式被调用。
【文本】(第3个格式不正确)
11111
22222
33333-
44444-4444
总结
1.非打印字符
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的'c'字符 |
| \f | 匹配一个换页符。等价于\x0c和\cL |
| \n | 匹配一个换行符。等价于\x0a和\cJ |
| \r | 匹配一个回车符。等价于\x0d和\cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[\f\n\r\t\v]。注意Unicode正则表达式会匹配全角空格符 |
| \S | 匹配任何非空白字符。等价于[^\f\n\r\t\v] |
| \t | 匹配一个制表符。等价于\x09和\cI |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK |
2.特殊字符
| $ | 匹配输入字符串的结尾位置。如果设置了RegExp对象的Multiline属性,则$也匹配'\n'或'\r'。要匹配$字符本身,请使用\$ |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用\(和\) |
| * | 匹配前面的子表达式零次或多次。要匹配*字符,请使用\* |
| + | 匹配前面的子表达式一次或多次。要匹配+字符,请使用\+ |
| . | 匹配除换行符\n之外的任何单字符。要匹配.,请使用\. |
| [ | 标记一个中括号表达式的开始。要匹配[,请使用\[ |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配?字符,请使用\? |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如,'n'匹配字符'n'。'\n'匹配换行符。序列'\\'匹配"\",而'\('则匹配"(" |
| ^ | 匹配输入字符串的开始位置,除非在方括号表达式中使用,此时它表示不接受该字符集合。要匹配^字符本身,请使用\^ |
| { | 标记限定符表达式的开始。要匹配{,请使用\{ |
| | | 指明两项之间的一个选择。要匹配|,请使用\| |
3.限定符
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*' |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号