基础介绍
基本概念
简介
Kafka是由Apache开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
特性
- 高吞吐量、低延迟:每秒可以处理几十万条消息,它的延迟最低只有几毫秒
- 可扩展性:集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且 支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1 个节点失败)
- 高并发:支持数千个客户端同时读写
术语
Procucer:消息生产者,向Kafka发消息的客户端
Consumer:消息消费者,向Kafka取消息的客户端
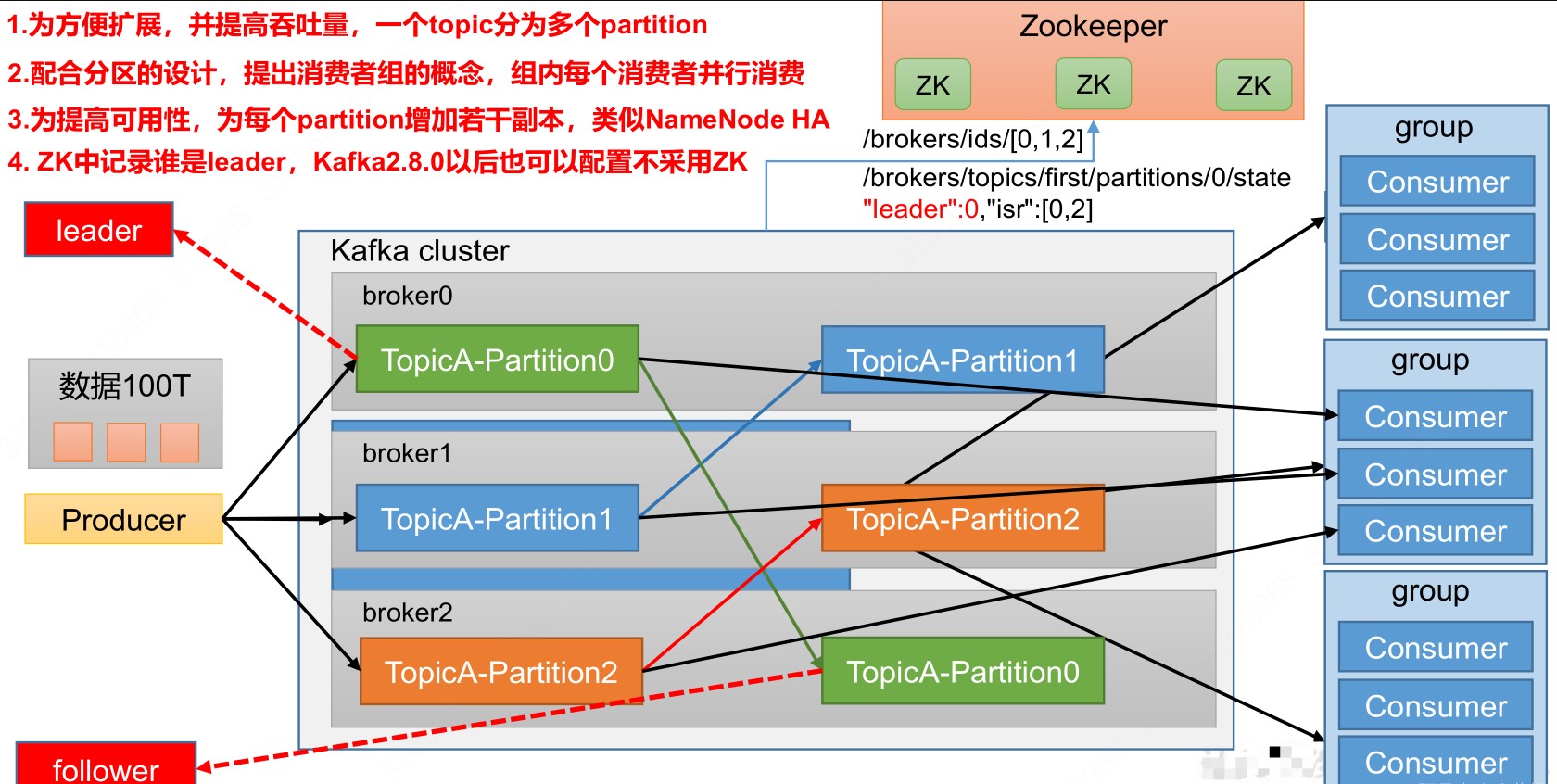
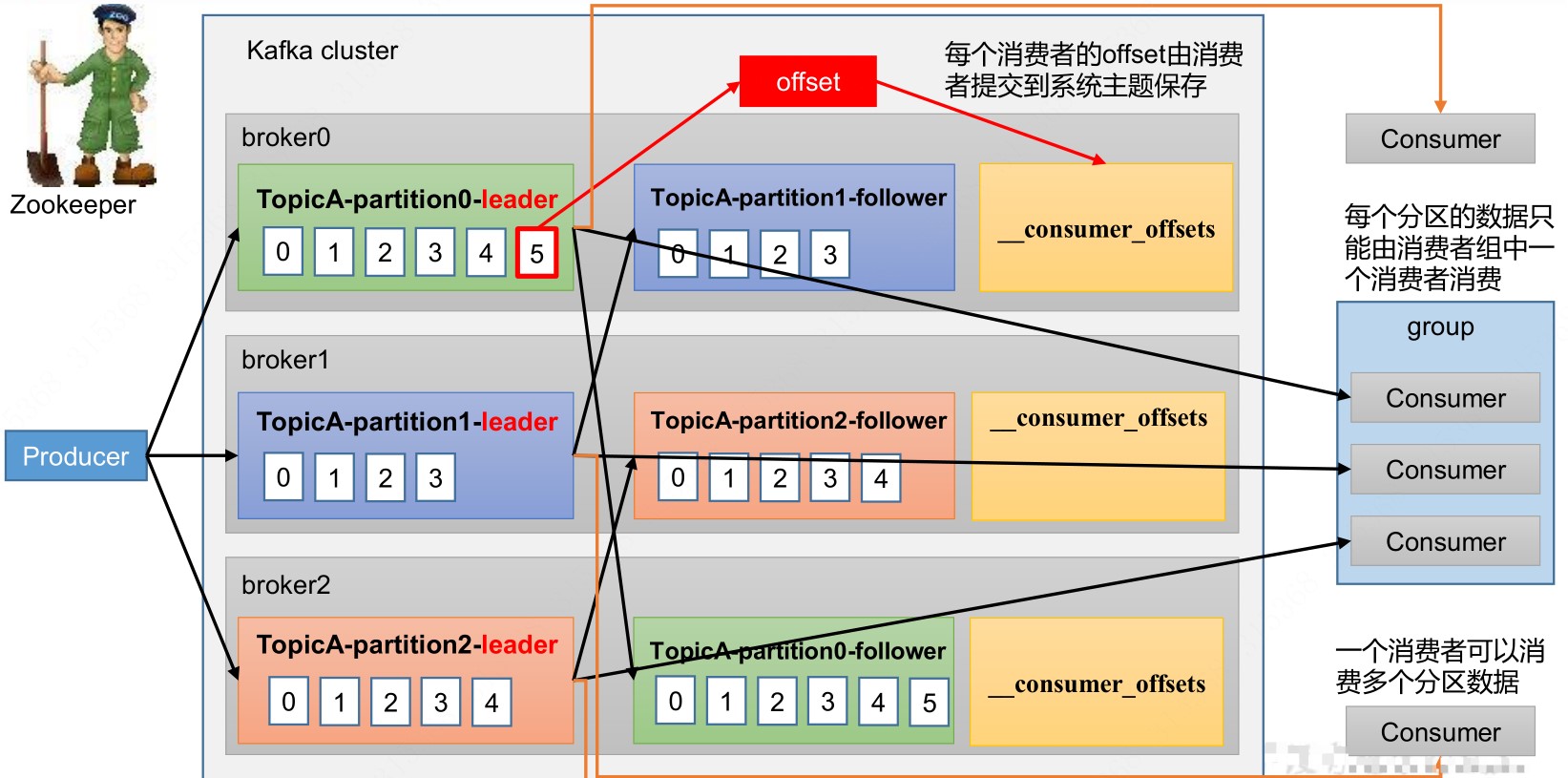
Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不影响。所有消费者都属于某个消费者组,消费者组是逻辑上的一个订阅者
Broker:一台Kafka服务器就是一个Broker。一个集群又多个Broker组成
Topic:队列,生产者和消费者面对的都是topic
Partition:分区,为了实现扩展性,一个topic可以分为多个partition,每个partition是一个有序队列
Replica:副本,一个topic每个分区都有若干个副本,一个leader和若干个follower
Leader:每个分区多个副本的主,生产者发送消息和消费者消费数据的对象都是leader
Follower:每个分区多个副本的从,实时从leader中同步数据,leader故障时某个follower会成为新的主
基础架构
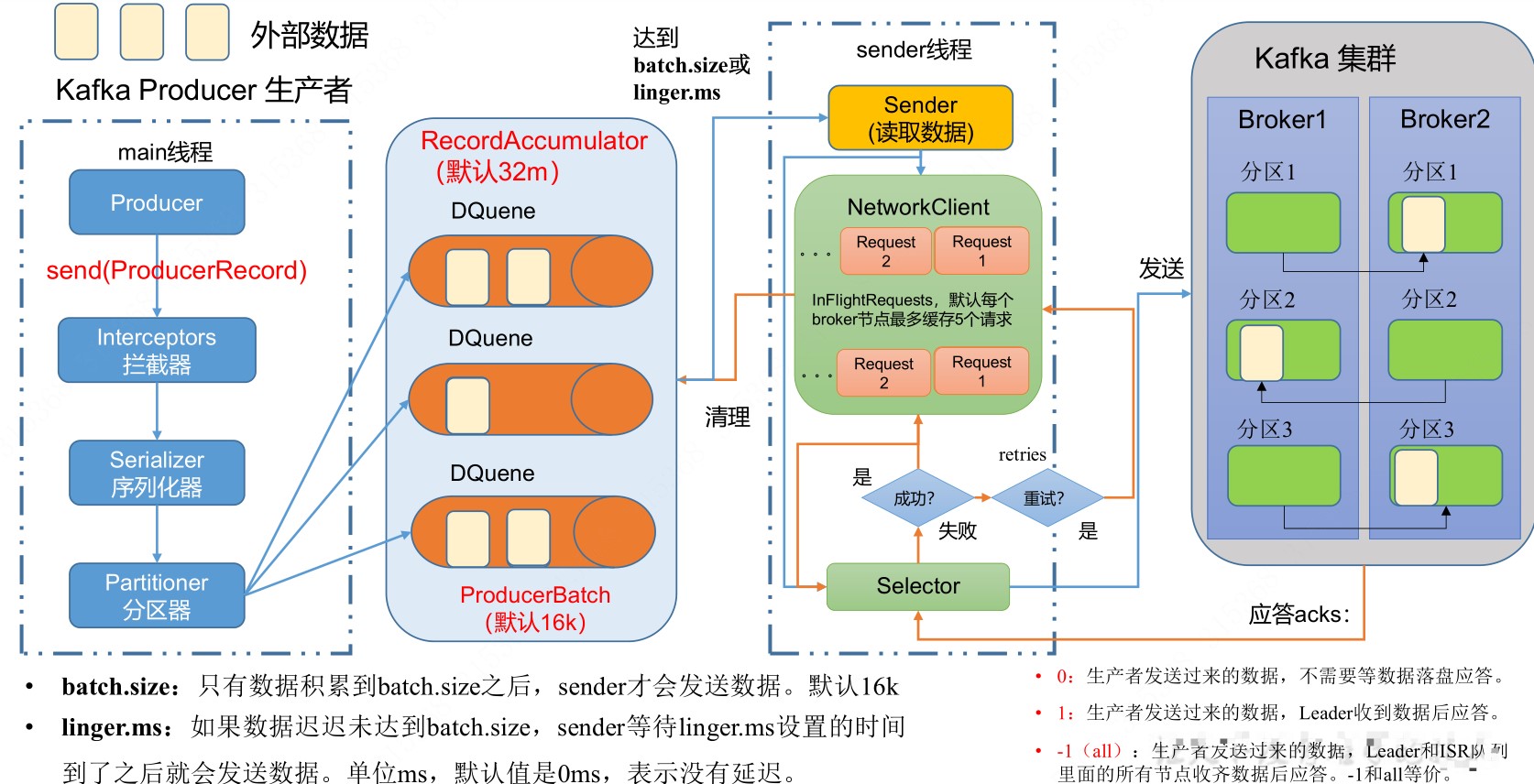
生产者
发送流程
分区
分区优点
- 便于合理使用存储资源,每个partition在一个broker上存储,可以把海量的数据按照分区切割成一块一块的数据存储在多个broker上,合理控制分区任务,可以实现负载均衡的效果
- 提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位消费数据
分区策略
- 在没有设置partition又没有设置key值的情况下,默认采用粘性分区,在一个分区数据发送之后再选择另一个分区
生产者吞吐量
batch.seiz:批次大小
linger.ms:等待时间
compression.type:压缩算法
buffer.memory:缓冲区大小
数据可靠性
ack=0:生产者发送数据,不需要等待落盘确认
ack=1:生产者发送数据,leader收到数据后确认
ack=-1:生产者发送数据,leader和follower收到后确认
生产者事务
发送时,设置唯一的transactional.id,kafka内部会有事务协调器来保证事务
消费者
消费流程
消费方式
pull
由consumer决定消费速率,kafka采用此方式,不足之处是如果没有数据,消费者会陷入到循环中,一直返回空数据
push
由broker决定消费速率,很难适应消费者的消费速率
Offset
自动提交
Kafka提供了自动提交offset的功能,相关参数如下:
enable.auto.commit:是否开启自动提交功能,默认true
auto.commit.interval.ms:自动提交间隔,默认5s
手动提交
虽然自动提交offset十分便利,但由于是基于时间提交的,开发人员难以把握提交时机,因此kafka也提供了手动提交的方式,手动提交分为同步提交和异步提交。同步提交必须等待提交完毕后才会消费下一批数据,会重试;异步提交发送完提交请求后就会开发消费下一批数据,不会重试,故可能提交失败
消费者事务
如果想完成consumer端的精准一次性消费,可以将cunsumer消费端消费过程和提交offset过程做原子绑定,保证事务
数据积压
如果是kafka消费能力不足,可以考虑增加topic的分区数,同事提升消费组的消费者数量,消费者数=分区数
如果是下游的数据处理不及时,批次拉去数据过少,可设置批次拉取的数量,参数如下
fetch.max.bytes:消费者获取一批消息最大的字节数
max.poll.records:消费者一个拉取消息的最大条数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号