大数据自学2-Hue集成环境中使用Sqoop组件从Sql Server导数据到Hive/HDFS
安装完CDH后,发现里面的东东实在是太多了,对于一个初学大数据的来说就犹如刘姥姥进了大观园,很新奇,这些东东每个单拿出来都够喝一壶的。

接来来就是一步一步地学习了,先大致学习了每个模组大致做什么用的,然后再按模组一个一个细致学习,并实际演练。
我给自已的第一个课题是如何将Sql Server的一个表数据导入到HDFS中,网上有很多这样的教程,不过我觉得最有用的还是官网的User Guide,网上的教程直接把命令列出来,后面的参数基本没有用,因此可以考虑官网User Gruide进行详细了解。
步骤如下:
1、因为是要连Sql Server,因此需要先从Microsoft官网下载Sql server jdbc驱动,下载地址:https://www.microsoft.com/zh-CN/download/details.aspx?displaylang=en&id=11774,
找到sqljdbc42.jar文件,上传到hadoop文件系统。
2、在Hue里新建一个WorkFlow ,拖入一个Sqoop Action
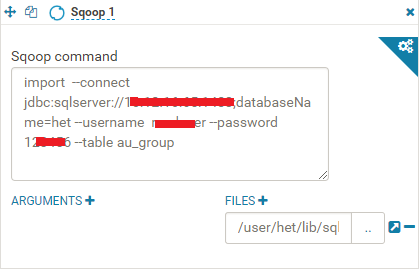
3、修改Sqoop的Command,如下图,命令:import --connect jdbc:sqlserver://xx.xx.xx.xx:xx;databaseName=xxx --username xxx --password xxx --table au_group,然后在Files下选择第一步上传的jdbc驱动。
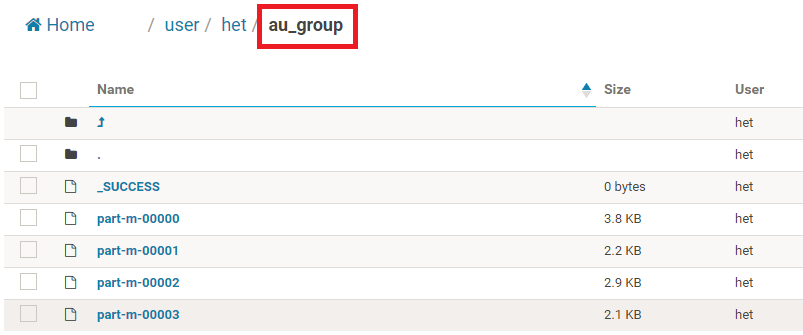
4、保存并Submit,就可以执行了,执行后会显示Success,如果出错的话,可以查Log,很容易找出问题。成功后就可以在Hdfs文件系统中看到在/User/用户名/下多了一个文件夹,文件夹名称即为--table指定的表名。
你会发现,这个小小的需求,实际上用到了Hue、Ozzie、Sqoop、HDFS这四个东东了。
接下来需要稍微变下,如何将Sql Server的一个表数据导入到Hive,这个如果在命令行模式下操作很简单,只要在上面的命令后面加上参数--hive-import就可以了,但在CDH 使用Hue Web 界面的集成环境里,却无法成功,问了以前碰过大数据的专家才知道这是个吭,可以用以下变通的方式实现
1、先使用Hive脚本创建表,类似以下这样的Hive Script
CREATE TABLE IF NOT EXISTS `xxx.xxxx` ( `ID` INT) COMMENT 'xxx' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE
这个Hive Script手写起来比较麻烦,可以执行create-hive-table命令加--verbose参数,可以在Log中看到完整的脚本,然后将此脚本存至HDFS。
2、执行此Hive Script脚本,可新建一Workflow里面只拉入一个Hive Script Action,这个Action指向上一步创建的脚本文件。
3、将数据从Sql Server中导入到HDFS,这一步完全跟上面的需求实现是一模一样的
4、将数据从HDFS中导入到Hive数据库中,命令参照如下
LOAD DATA INPATH '/user/het/***' OVERWRITE INTO TABLE xxx;
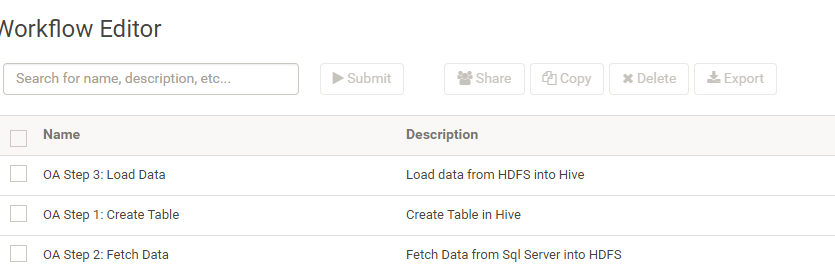
整个步骤我分为三步,如下图,当然也可以将三步合在一个Workflow里。
执行完所有步骤后,可以到Hive数据库中查询,一开始发现Hive数据库中所有的数据全是Null,查了资料 发现是分隔符的问题,也就是说Hive表各字段的分隔符与导入数据的分隔符是不一致的,表分隔符在创建表时可以使用
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
参数来指定,因此在导入数据时也指定相同的分隔符即可,也就是import Command后面加上--fields-terminated-by "\t",问题解决。
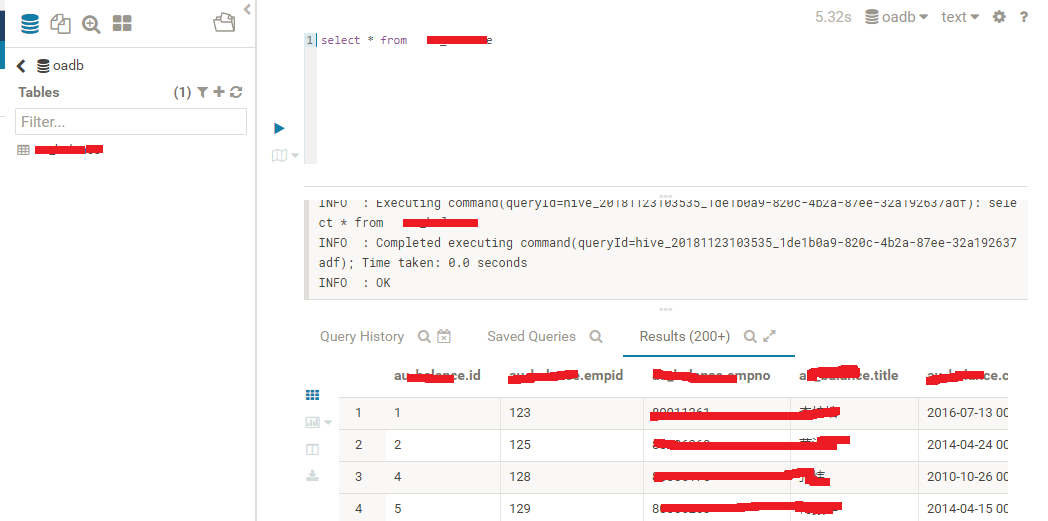
最后看下导入到Hive中的数据效果吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号