

Java多线程之ThreadPoolExecutor详解使用
1、概述
我将讲解JAVA原生线程池的基本使用,并由此延伸出JAVA中和线程管理相关的类结构体系,然后我们详细描述JAVA原生线程池的结构和工作方式
2、为什么要使用线程池
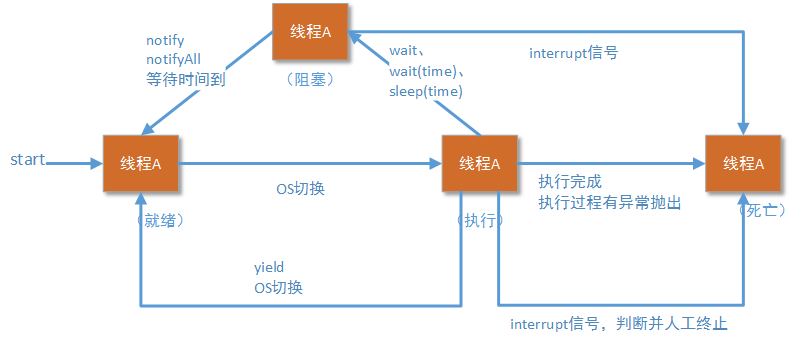
前文我们已经讲到,线程是一个操作系统概念。操作系统负责这个线程的创建、挂起、运行、阻塞和终结操作。而操作系统创建线程、切换线程状态、终结线程都要进行CPU调度。
另一方面,目前大多数生产环境我们所面临问题的技术背景一般是:处理某一次请求的时间是非常短暂的,但是请求数量是巨大的。这种技术背景下,如果我们为每一个请求都单独创建一个线程,那么物理机的所有资源基本上都被操作系统创建线程、切换线程状态、销毁线程这些操作所占用,用于业务请求处理的资源反而减少了。所以最理想的处理方式是,将处理请求的线程数量控制在一个范围,既保证后续的请求不会等待太长时间,又保证物理机将足够的资源用于请求处理本身。
另外,一些操作系统是有最大线程数量限制的。当运行的线程数量逼近这个值的时候,操作系统会变得不稳定。这也是我们要限制线程数量的原因。
3、线程池的基本使用方式
JAVA语言为我们提供了两种基础线程池的选择:ScheduledThreadPoolExecutor和ThreadPoolExecutor。它们都实现了ExecutorService接口(注意,ExecutorService接口本身和“线程池”并没有直接关系,它的定义更接近“执行器”,而“使用线程管理的方式进行实现”只是其中的一种实现方式)。这篇文章中,我们主要围绕ThreadPoolExecutor类进行讲解。
3-1、简单使用
首先我们来看看ThreadPoolExecutor类的最简单使用方式:
随后的文章中我们将对线程池中的corePoolSize、maximumPoolSize、keepAliveTime、timeUnit、workQueue、threadFactory、handler参数和一些常用/不常用的设置项进行逐一讲解。
3-2、ThreadPoolExecutor逻辑结构和工作方式
在上面的代码中,我们创建线程池的时候使用了ThreadPoolExecutor中最简单的一个构造函数:
- 构造函数中需要传入的参数包括corePoolSize、maximumPoolSize、keepAliveTime、timeUnit和workQueue。要明确理解这些参数(和后续将要介绍的参数)的含义,就首先要搞清楚ThreadPoolExecutor线程池的逻辑结构。
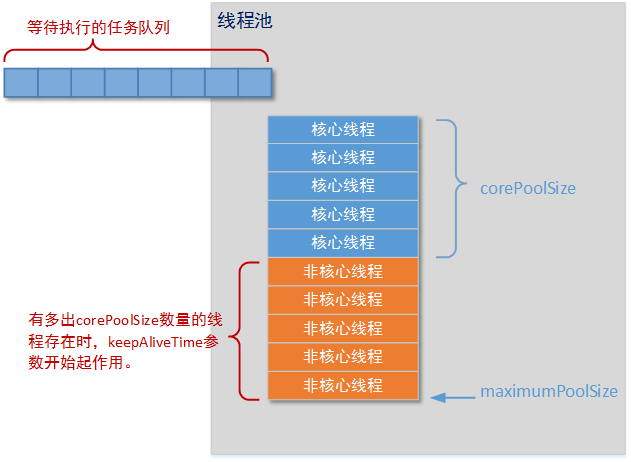
一定要注意一个概念,即存在于线程池中容器的一定是Thread对象,而不是您要求运行的任务(所以叫线程池而不叫任务池也不叫对象池,更不叫游泳池);您要求运行的任务将被线程池分配给某一个空闲的Thread运行。
从上图中,我们可以看到构成线程池的几个重要元素:
-
等待队列:顾名思义,就是您调用线程池对象的submit()方法或者execute()方法,要求线程池运行的任务(这些任务必须实现Runnable接口或者Callable接口)。但是出于某些原因线程池并没有马上运行这些任务,而是送入一个队列等待执行(这些原因后文马上讲解)。
-
核心线程:线程池主要用于执行任务的是“核心线程”,“核心线程”的数量是您创建线程时所设置的corePoolSize参数决定的。如果不进行特别的设定,线程池中始终会保持corePoolSize数量的线程数(不包括创建阶段)。
-
非核心线程:一旦任务数量过多(由等待队列的特性决定),线程池将创建“非核心线程”临时帮助运行任务。您设置的大于corePoolSize参数小于maximumPoolSize参数的部分,就是线程池可以临时创建的“非核心线程”的最大数量。这种情况下如果某个线程没有运行任何任务,在等待keepAliveTime时间后,这个线程将会被销毁,直到线程池的线程数量重新达到corePoolSize。
-
要重点理解上一条描述中黑体字部分的内容。也就是说,并不是所谓的“非核心线程”才会被回收;而是谁的空闲时间达到keepAliveTime这个阀值,就会被回收。直到线程池中线程数量等于corePoolSize为止。
-
maximumPoolSize参数也是当前线程池允许创建的最大线程数量。那么如果您设置的corePoolSize参数和您设置的maximumPoolSize参数一致时,线程池在任何情况下都不会回收空闲线程。keepAliveTime和timeUnit也就失去了意义。
-
keepAliveTime参数和timeUnit参数也是配合使用的。keepAliveTime参数指明等待时间的量化值,timeUnit指明量化值单位。例如keepAliveTime=1,timeUnit为TimeUnit.MINUTES,代表空闲线程的回收阀值为1分钟。
说完了线程池的逻辑结构,下面我们讨论一下线程池是怎样处理某一个运行任务的。下图描述了一个完整的任务处理过程:
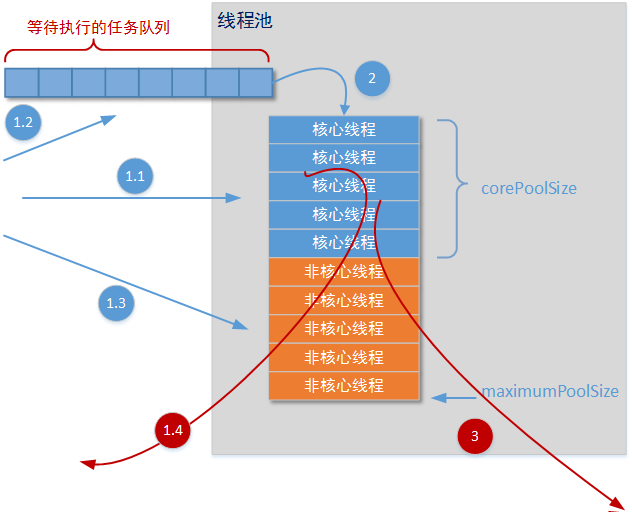
1、首先您可以通过线程池提供的submit()方法或者execute()方法,要求线程池执行某个任务。线程池收到这个要求执行的任务后,会有几种处理情况:
1.1、如果当前线程池中运行的线程数量还没有达到corePoolSize大小时,线程池会创建一个新的线程运行您的任务,无论之前已经创建的线程是否处于空闲状态。
1.2、如果当前线程池中运行的线程数量已经达到设置的corePoolSize大小,线程池会把您的这个任务加入到等待队列中。直到某一个的线程空闲了,线程池会根据您设置的等待队列规则,从队列中取出一个新的任务执行。
1.3、如果根据队列规则,这个任务无法加入等待队列。这时线程池就会创建一个“非核心线程”直接运行这个任务。注意,如果这种情况下任务执行成功,那么当前线程池中的线程数量一定大于corePoolSize。
1.4、如果这个任务,无法被“核心线程”直接执行,又无法加入等待队列,又无法创建“非核心线程”直接执行,且您没有为线程池设置RejectedExecutionHandler。这时线程池会抛出RejectedExecutionException异常,即线程池拒绝接受这个任务。(实际上抛出RejectedExecutionException异常的操作,是ThreadPoolExecutor线程池中一个默认的RejectedExecutionHandler实现:AbortPolicy,这在后文会提到)
2、一旦线程池中某个线程完成了任务的执行,它就会试图到任务等待队列中拿去下一个等待任务(所有的等待任务都实现了BlockingQueue接口,按照接口字面上的理解,这是一个可阻塞的队列接口),它会调用等待队列的poll()方法,并停留在哪里。
3、当线程池中的线程超过您设置的corePoolSize参数,说明当前线程池中有所谓的“非核心线程”。那么当某个线程处理完任务后,如果等待keepAliveTime时间后仍然没有新的任务分配给它,那么这个线程将会被回收。线程池回收线程时,对所谓的“核心线程”和“非核心线程”是一视同仁的,直到线程池中线程的数量等于您设置的corePoolSize参数时,回收过程才会停止。
3-3、不常用的设置
在ThreadPoolExecutor线程池中,有一些不常用的设置。我建议如果您在应用场景中没有特殊的要求,就不需要使用这些设置:
3-3-1、 allowCoreThreadTimeOut:
前文我们讨论到,线程池回收线程只会发生在当前线程池中线程数量大于corePoolSize参数的时候;当线程池中线程数量小于等于corePoolSize参数的时候,回收过程就会停止。
allowCoreThreadTimeOut设置项可以要求线程池:将包括“核心线程”在内的,没有任务分配的任何线程,在等待keepAliveTime时间后全部进行回收:
以下是设置前的效果:

以下是设置后的效果:
3-3-2 prestartAllCoreThreads
前文我们还讨论到,当线程池中的线程还没有达到您设置的corePoolSize参数值的时候,如果有新的任务到来,线程池将创建新的线程运行这个任务,无论之前已经创建的线程是否处于空闲状态。这个描述可以用下面的示意图表示出来:
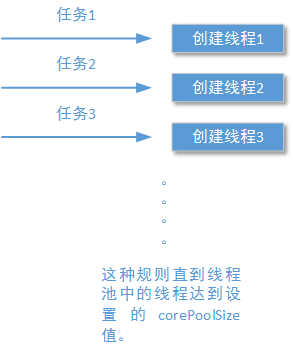
prestartAllCoreThreads设置项,可以在线程池创建,但还没有接收到任何任务的情况下,先行创建符合corePoolSize参数值的线程数:
1、概述
我将讲解JAVA原生线程池的基本使用,并由此延伸出JAVA中和线程管理相关的类结构体系,然后我们详细描述JAVA原生线程池的结构和工作方式
2、为什么要使用线程池
前文我们已经讲到,线程是一个操作系统概念。操作系统负责这个线程的创建、挂起、运行、阻塞和终结操作。而操作系统创建线程、切换线程状态、终结线程都要进行CPU调度。
另一方面,目前大多数生产环境我们所面临问题的技术背景一般是:处理某一次请求的时间是非常短暂的,但是请求数量是巨大的。这种技术背景下,如果我们为每一个请求都单独创建一个线程,那么物理机的所有资源基本上都被操作系统创建线程、切换线程状态、销毁线程这些操作所占用,用于业务请求处理的资源反而减少了。所以最理想的处理方式是,将处理请求的线程数量控制在一个范围,既保证后续的请求不会等待太长时间,又保证物理机将足够的资源用于请求处理本身。
另外,一些操作系统是有最大线程数量限制的。当运行的线程数量逼近这个值的时候,操作系统会变得不稳定。这也是我们要限制线程数量的原因。
3、线程池的基本使用方式
JAVA语言为我们提供了两种基础线程池的选择:ScheduledThreadPoolExecutor和ThreadPoolExecutor。它们都实现了ExecutorService接口(注意,ExecutorService接口本身和“线程池”并没有直接关系,它的定义更接近“执行器”,而“使用线程管理的方式进行实现”只是其中的一种实现方式)。这篇文章中,我们主要围绕ThreadPoolExecutor类进行讲解。
3-1、简单使用
首先我们来看看ThreadPoolExecutor类的最简单使用方式:
随后的文章中我们将对线程池中的corePoolSize、maximumPoolSize、keepAliveTime、timeUnit、workQueue、threadFactory、handler参数和一些常用/不常用的设置项进行逐一讲解。
3-2、ThreadPoolExecutor逻辑结构和工作方式
在上面的代码中,我们创建线程池的时候使用了ThreadPoolExecutor中最简单的一个构造函数:
- 构造函数中需要传入的参数包括corePoolSize、maximumPoolSize、keepAliveTime、timeUnit和workQueue。要明确理解这些参数(和后续将要介绍的参数)的含义,就首先要搞清楚ThreadPoolExecutor线程池的逻辑结构。
一定要注意一个概念,即存在于线程池中容器的一定是Thread对象,而不是您要求运行的任务(所以叫线程池而不叫任务池也不叫对象池,更不叫游泳池);您要求运行的任务将被线程池分配给某一个空闲的Thread运行。
从上图中,我们可以看到构成线程池的几个重要元素:
-
等待队列:顾名思义,就是您调用线程池对象的submit()方法或者execute()方法,要求线程池运行的任务(这些任务必须实现Runnable接口或者Callable接口)。但是出于某些原因线程池并没有马上运行这些任务,而是送入一个队列等待执行(这些原因后文马上讲解)。
-
核心线程:线程池主要用于执行任务的是“核心线程”,“核心线程”的数量是您创建线程时所设置的corePoolSize参数决定的。如果不进行特别的设定,线程池中始终会保持corePoolSize数量的线程数(不包括创建阶段)。
-
非核心线程:一旦任务数量过多(由等待队列的特性决定),线程池将创建“非核心线程”临时帮助运行任务。您设置的大于corePoolSize参数小于maximumPoolSize参数的部分,就是线程池可以临时创建的“非核心线程”的最大数量。这种情况下如果某个线程没有运行任何任务,在等待keepAliveTime时间后,这个线程将会被销毁,直到线程池的线程数量重新达到corePoolSize。
-
要重点理解上一条描述中黑体字部分的内容。也就是说,并不是所谓的“非核心线程”才会被回收;而是谁的空闲时间达到keepAliveTime这个阀值,就会被回收。直到线程池中线程数量等于corePoolSize为止。
-
maximumPoolSize参数也是当前线程池允许创建的最大线程数量。那么如果您设置的corePoolSize参数和您设置的maximumPoolSize参数一致时,线程池在任何情况下都不会回收空闲线程。keepAliveTime和timeUnit也就失去了意义。
-
keepAliveTime参数和timeUnit参数也是配合使用的。keepAliveTime参数指明等待时间的量化值,timeUnit指明量化值单位。例如keepAliveTime=1,timeUnit为TimeUnit.MINUTES,代表空闲线程的回收阀值为1分钟。
说完了线程池的逻辑结构,下面我们讨论一下线程池是怎样处理某一个运行任务的。下图描述了一个完整的任务处理过程:
1、首先您可以通过线程池提供的submit()方法或者execute()方法,要求线程池执行某个任务。线程池收到这个要求执行的任务后,会有几种处理情况:
1.1、如果当前线程池中运行的线程数量还没有达到corePoolSize大小时,线程池会创建一个新的线程运行您的任务,无论之前已经创建的线程是否处于空闲状态。
1.2、如果当前线程池中运行的线程数量已经达到设置的corePoolSize大小,线程池会把您的这个任务加入到等待队列中。直到某一个的线程空闲了,线程池会根据您设置的等待队列规则,从队列中取出一个新的任务执行。
1.3、如果根据队列规则,这个任务无法加入等待队列。这时线程池就会创建一个“非核心线程”直接运行这个任务。注意,如果这种情况下任务执行成功,那么当前线程池中的线程数量一定大于corePoolSize。
1.4、如果这个任务,无法被“核心线程”直接执行,又无法加入等待队列,又无法创建“非核心线程”直接执行,且您没有为线程池设置RejectedExecutionHandler。这时线程池会抛出RejectedExecutionException异常,即线程池拒绝接受这个任务。(实际上抛出RejectedExecutionException异常的操作,是ThreadPoolExecutor线程池中一个默认的RejectedExecutionHandler实现:AbortPolicy,这在后文会提到)
2、一旦线程池中某个线程完成了任务的执行,它就会试图到任务等待队列中拿去下一个等待任务(所有的等待任务都实现了BlockingQueue接口,按照接口字面上的理解,这是一个可阻塞的队列接口),它会调用等待队列的poll()方法,并停留在哪里。
3、当线程池中的线程超过您设置的corePoolSize参数,说明当前线程池中有所谓的“非核心线程”。那么当某个线程处理完任务后,如果等待keepAliveTime时间后仍然没有新的任务分配给它,那么这个线程将会被回收。线程池回收线程时,对所谓的“核心线程”和“非核心线程”是一视同仁的,直到线程池中线程的数量等于您设置的corePoolSize参数时,回收过程才会停止。
3-3、不常用的设置
在ThreadPoolExecutor线程池中,有一些不常用的设置。我建议如果您在应用场景中没有特殊的要求,就不需要使用这些设置:
3-3-1、 allowCoreThreadTimeOut:
前文我们讨论到,线程池回收线程只会发生在当前线程池中线程数量大于corePoolSize参数的时候;当线程池中线程数量小于等于corePoolSize参数的时候,回收过程就会停止。
allowCoreThreadTimeOut设置项可以要求线程池:将包括“核心线程”在内的,没有任务分配的任何线程,在等待keepAliveTime时间后全部进行回收:
- 1
- 2
- 3
以下是设置前的效果:
以下是设置后的效果:
3-3-2 prestartAllCoreThreads
前文我们还讨论到,当线程池中的线程还没有达到您设置的corePoolSize参数值的时候,如果有新的任务到来,线程池将创建新的线程运行这个任务,无论之前已经创建的线程是否处于空闲状态。这个描述可以用下面的示意图表示出来:
prestartAllCoreThreads设置项,可以在线程池创建,但还没有接收到任何任务的情况下,先行创建符合corePoolSize参数值的线程数:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号