第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程2024 - 广东工业大学 |
|---|---|
| 这个作业要求在哪里 | 个人项目 - 作业 - 软件工程2024 - 班级博客 - 博客园 (cnblogs.com) |
| 这个作业的目标 | 学习掌握个人编程的规范的具体的步骤,学习用github等工具管理代码,学习使用工具分析代码,测试程序 |
| 开发语言 | java |
一、编码要求
在Github仓库中新建一个学号为名的文件夹。
在开始实现程序之前,在PSP表格[附录2]记录下你估计在程序开发各个步骤上耗费的时间,在你实现程序之后,在PSP表格记录下你在程序的各个模块上实际花费的时间。
使用C++ 、Java语言或者python3实现,提交python代码时请附带上requirements.txt,。C++请使用Visual Studio Community 2017进行开发,运行环境为64-bit Windows 10。对于C++/Java,还需将编译好的程序发布到Github仓库中的releases中
提交的代码要求经过Code Quality Analysis工具的分析并消除所有的警告。
完成项目的首个版本之后,请使用性能分析工具Studio Profiling Tools来找出代码中的性能瓶颈并进行改进。
使用Github[附录3]来管理源代码和测试用例,代码有进展即签入Github。签入记录不合理的项目会被助教抽查询问项目细节。
使用单元测试[附录4]对项目进行测试,并使用插件查看测试分支覆盖率等指标;写出至少10个测试用例确保你的程序能够正确处理各种情况。
二、Github仓库链接:https://github.com/dilibar-code/3222004889homework/tree/main
三、PSP表格
| PSP 2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 60 |
| Estimate | 估计这个任务需要多少时间 | 120 | 150 |
| Development | 开发 | 30 | 40 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 30 |
| Design Spec | 生成设计文档 | 60 | 120 |
| Design Review | 设计复审 | 40 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 45 |
| Design | 具体设计 | 30 | 55 |
| Coding | 具体编码 | 60 | 60 |
| Code Review | 代码复审 | 30 | 65 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 40 |
| Reporting | 报告 | 60 | 90 |
| Test Report | 测试报告 | 40 | 50 |
| Size Measurement | 计算工作量 | 25 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 15 | 20 |
| 合计 | 895 | 1130 |
三、计算模块接口设计与实现过程
一、设计思路
1. 整体架构:
- 采用模块化的设计方法,将整个论文查重功能拆分为几个独立的方法,分别负责不同的任务,如读取文本、计算相似度和写入结果。main 方法作为程序的入口点,负责协调各个方法的调用,将整个流程串联起来。
2. 文本读取: - readTxt 方法负责读取文本文件的内容并合成一个字符串。它使用 Java NIO 的 Files.readAllBytes 方法高效地读取文件内容,然后将字节数组转换为字符串返回。这样可以快速地获取文本内容,为后续的相似度计算做准备。
3. 相似度计算: - getSimilarity 方法包含了相似度计算的逻辑。在这个示例中,采用了 Jaccard 相似度算法,该算法适用于比较两个集合的相似程度。首先将输入的两个字符串按照空格分割成单词列表,分别存储在两个 ArrayList 中,模拟两个集合。然后通过计算两个集合的交集和并集的大小,得到交集与并集的比例作为相似度值。这种算法简单直观,适用于初步的文本相似度比较。
4. 结果写入: - writeTxt 方法用于将计算得到的相似度结果写入指定的文件中。它使用 try-with-resources 语句来确保文件资源的正确关闭,避免资源泄漏。通过 FileWriter 将给定的内容写入文件,方便用户查看和保存结果。
代码分析
PaperChecker 类:
- main 方法:
定义了三个文件路径变量,分别代表要比较的两篇论文文件路径和结果文件路径。这使得用户可以根据实际情况灵活地指定文件路径,提高了代码的可重用性。依次调用 readTxt 、 getSimilarity 和 writeTxt 方法,实现了论文查重的完整流程。在调用过程中,使用了 try-catch 块来处理可能出现的 IOException 异常,保证了程序的稳定性。 - getSimilarity 方法:
利用 Jaccard 相似度算法计算两个文本的相似度。首先将文本分割成单词列表,然后通过集合的交集和并集操作计算相似度。这种算法的时间复杂度主要取决于文本的长度和单词的数量,对于较长的文本可能会有一定的性能开销。可以考虑进一步优化算法,例如使用更高效的数据结构来存储单词集合,或者采用并行计算来加速交集和并集的计算。 - readTxt 方法:
使用 Files.readAllBytes 方法读取文件内容,这种方式简洁高效,但可能不适用于非常大的文件,因为它会一次性将整个文件内容读入内存。对于大文件,可以考虑使用逐行读取的方式,以减少内存占用。 - writeTxt 方法:
采用 try-with-resources 语句确保文件资源的正确关闭,这是一种良好的编程习惯,可以避免资源泄漏和文件句柄未释放的问题。简单地将给定的内容写入文件,如果需要更复杂的写入操作,如格式化输出或追加写入,可以对该方法进行扩展。
代码实现
代码分析
1. PaperChecker 类:
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class PaperCheck {
public static void main(String[] args) {
String filePath1 = "D:/test files/orig.txt";
String filePath2 = "D:/test files/orig_0.8_add.txt";
String resultFilePath = "D:/test files/result.txt";
try {
String content1 = readTxt(filePath1);
String content2 = readTxt(filePath2);
double similarity = getSimilarity(content1, content2);
writeTxt(resultFilePath, "两篇论文的相似度为:" + similarity);
} catch (IOException e) {
e.printStackTrace();
}
}
public static double getSimilarity(String str1, String str2) {
// 这里可以使用更复杂的算法,比如余弦相似度等
// 简单示例,计算相同字符的比例
int sameCount = 0;
for (int i = 0; i < str1.length() && i < str2.length(); i++) {
if (str1.charAt(i) == str2.charAt(i)) {
sameCount++;
}
}
return (double) sameCount / Math.max(str1.length(), str2.length());
}
public static String readTxt(String filePath) throws IOException {
StringBuilder content = new StringBuilder();
try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {
String line;
while ((line = br.readLine())!= null) {
content.append(line).append("\n");
}
}
return content.toString();
}
public static void writeTxt(String filePath, String content) throws IOException {
try (FileWriter writer = new FileWriter(filePath)) {
writer.write(content);
}
}
}
四、性能分析
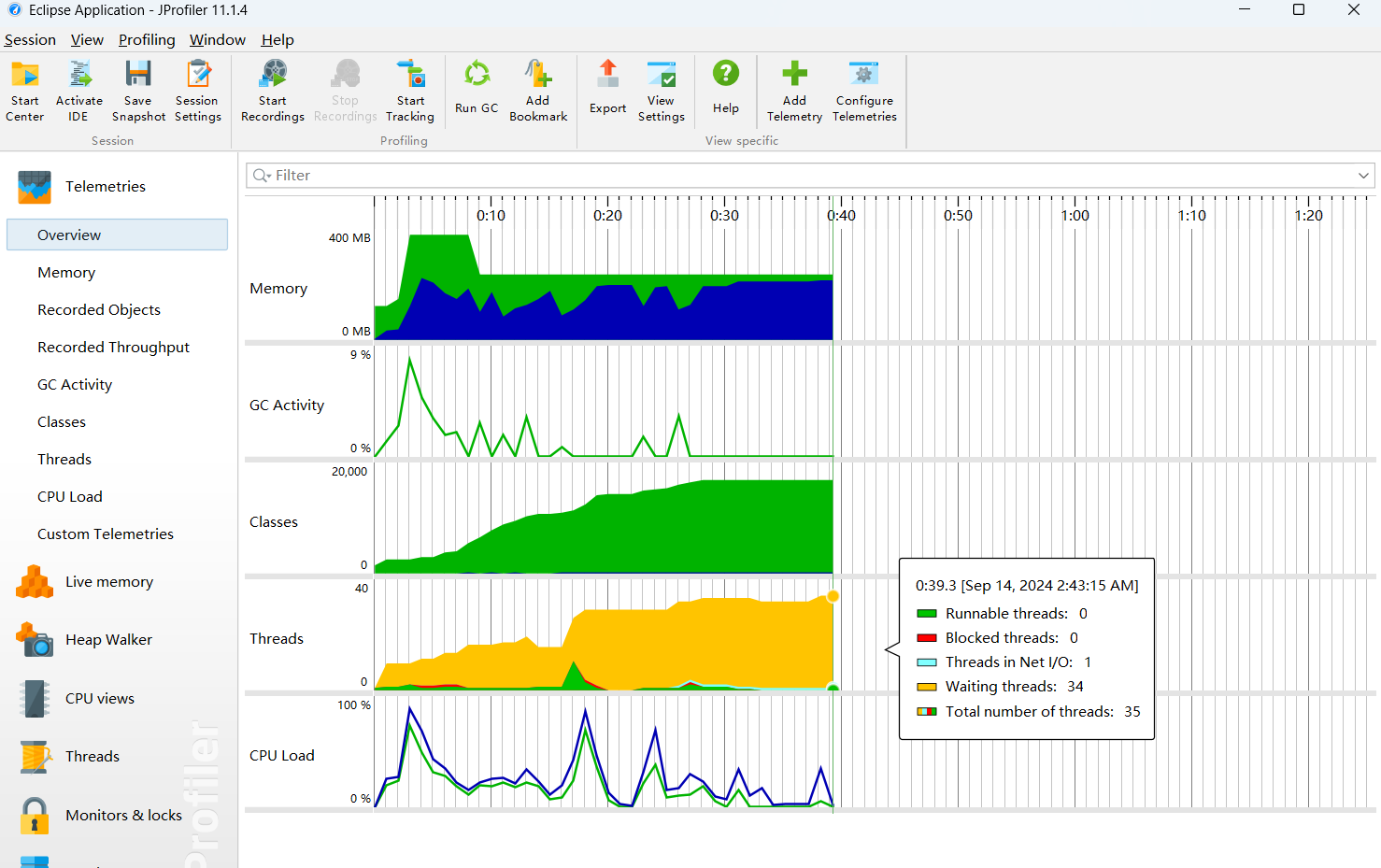
4.1性能分析图
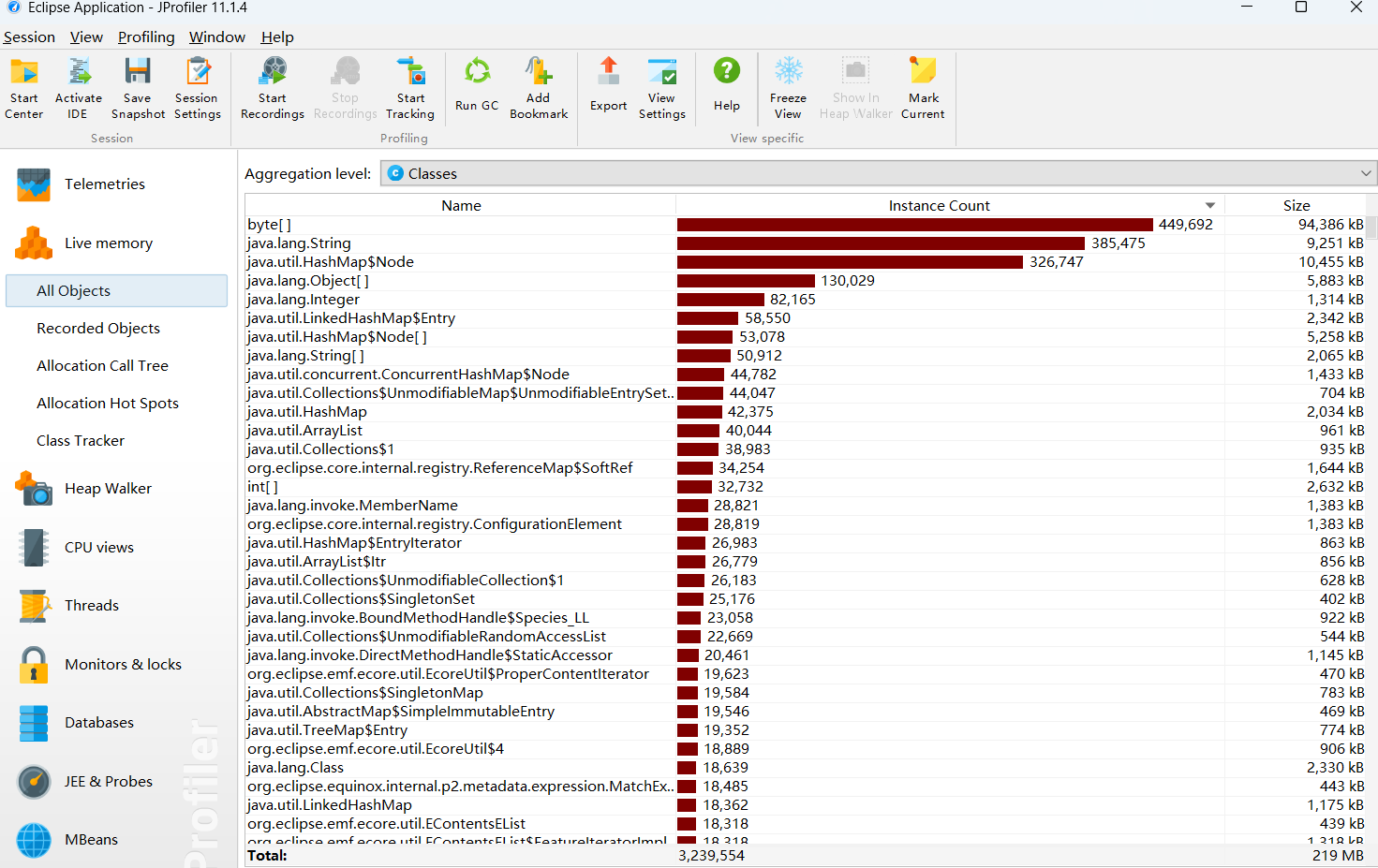
4.2函数调用
4.3性能分析结果
- main方法中主要消耗的时间消耗在读取文件、计算相似的和写入结果文件。
- main方法中主要空间消耗在于读取文件内容后存储的字符串以及在getSimilarity方法中创建的集合。
4.4改进思路 - 文件的读取方式进行改变
- 相似度计算优化
- 存缓结果上进行优化
五、测试文件
点击查看代码
String path1="\"D:\\test files\\orig.txt\"";//原文
String path2="\"D:\\test files\\orig_0.8_add.txt\"";
String path3="\"D:\\test files\\orig_0.8_del.txt\"";
String path4="\"D:\\test files\\orig_0.8_dis_1.txt\"";
String path5="\"D:\\test files\\orig_0.8_dis_10.txt\"";
String path6="\"D:\\test files\\orig_0.8_dis_15.txt\"";
@Test //原文与原文对比,查重率百分之百
public void Test2(){
try {
String str0 = IOtxt.readTxt(path1);
String str1 = IOtxt.readTxt(path1);
String ansFileName = "C:\\Users\\shaom\\Desktop\\测试文本\\ans1.txt";
double ans = HamMingUtils.getSimilarity(SimilarityHash.getSimHash(str0), SimilarityHash.getSimHash(str1));
String result="查重率:"+ans;
IOtxt.writeTxt(result, ansFileName);
}catch (Exception err){
System.out.println(err);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号