Solr集群搭建详细教程(一)
注:欢迎大家转载,非商业用途请在醒目位置注明本文链接和作者名dijia478,商业用途请联系本人dijia478@163.com。
一、Solr集群的系统架构
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
SolrCloud是基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡

1.物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
2.逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
2.1. collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX
2.2. Core
每个Core是Solr中一个独立运行单位,提供 索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成所以collection一般由多个core组成。
2.3. Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
2.4. Shard
Collection的逻辑分片。每个Shard被化成一个或者多个replication,通过选举确定哪个是Leader。
3.本教程实现的solr集群架构

Zookeeper作为集群的管理工具。
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口
需要实现zookeeper 高可用。需要搭建集群。建议是奇数节点。需要三个zookeeper服务器。
搭建solr集群至少需要7台服务器。
这里因环境限制,演示的是搭建伪分布式(在一台虚拟机上,建议内存至少1G):
需要三个zookeeper节点
需要四个tomcat节点。
本文使用tomcat进行部署,而不使用solr自带的jetty
4.系统环境
CentOS-6.7-i386-bin-DVD1
jdk-8u151-linux-i586
apache-tomcat-8.5.24
zookeeper-3.4.10
solr-7.1.0
注意:solr6.0以上版本,官方建议使用jdk8,tomcat8,搭建步骤和solr6以下略微有区别
二、 Zookeeper集群搭建
第一步:需要安装jdk环境。
JDK安装过程省略,不会的去看我的这篇文章:
Linux服务器上安装JDK小白教程
能看集群搭建教程的,应该不可能不会安JDK吧,安好之后是这样的
第二步:把zookeeper的压缩包上传到服务器。
第三步:解压缩。
解压过程省略,我这里解压到了/usr/share/

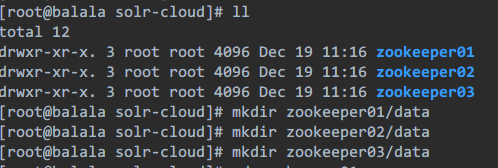
第四步:把zookeeper复制三份。
先创建目录/usr/local/solr-cloud

第五步:在每个zookeeper目录下创建一个data目录。
第六步:在data目录下创建一个myid文件,文件名就叫做“myid”。内容就是每个实例的id。例如1、2、3
这里我就截一个图啊,其他两个分别照着做,2和3

算了,我怕有些人不会。。。看清楚我在solr-cloud目录下执行的啊

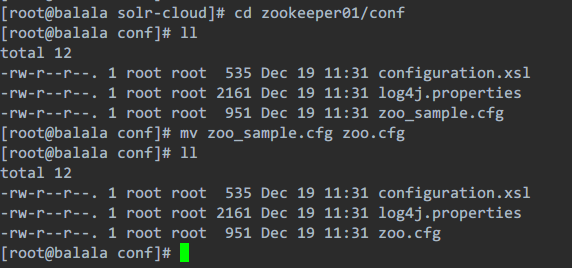
第七步:把conf目录下的zoo_sample.cfg文件改名为zoo.cfg
这次我就真的只演示一个了,其他两个照做,其实第五步和第七步可以在第四步前做,是我疏忽了。
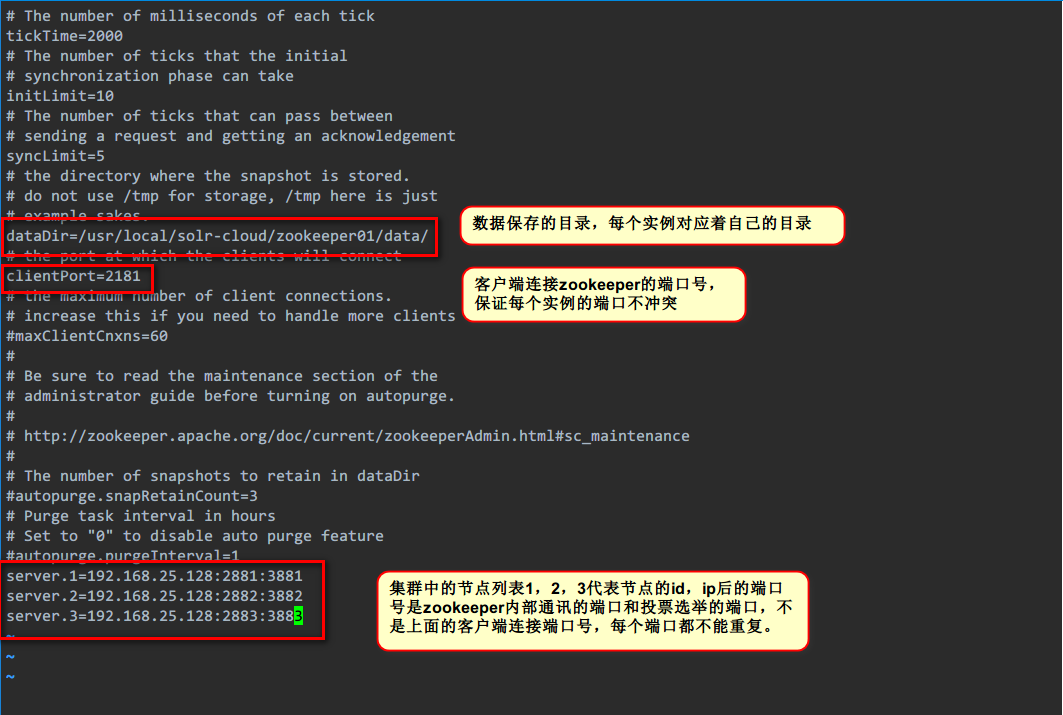
第八步:修改zoo.cfg配置文件。
只演示第一个,另外两个自己改。只改前两个红色框框里的(目录和端口号),最后那个红框里的内容三个配置文件一样
server.1的这个1,就是上面第六步的内容。在实际工作中每个实例在不同的服务器上,所以后面的ip应该是不同的,我这里是在一台虚拟机上演示,所以ip相同。
第九步:启动每个zookeeper实例
这里一个个进目录里启动实在是好麻烦啊,我替大家写个简单的脚本

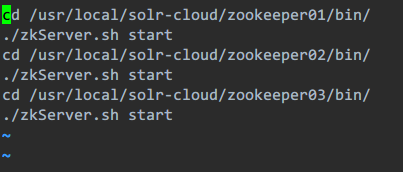
cd /usr/local/solr-cloud/zookeeper01/bin/ ./zkServer.sh start cd /usr/local/solr-cloud/zookeeper02/bin/ ./zkServer.sh start cd /usr/local/solr-cloud/zookeeper03/bin/ ./zkServer.sh start
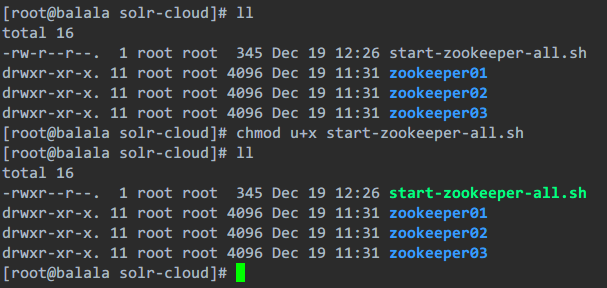
写完后发现没有执行权限,添加权限:
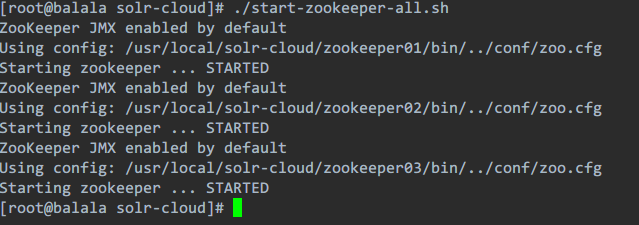
然后运行脚本,就OK了
为了验证,去三个zookeeper的实例里bin目录下分别查看每个实例的状态
(我刚开始是把查看状态的命令写在脚本里的,让一启动就查看,可每次都显示not running,后来想了想,应该是因为脚本执行太快,启动命令执行了但还没启动起来,就去查看状态,所以会显示没有运行)



如果你显示的是这样子的一个领导两个部下(leader和follower不一定是谁,随机的),那么就代表zookeeper集群已经搭建完成
第一步完成了,下来搭建solr集群
Solr集群搭建详细教程(二)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号